1、深大团队让机器人听懂指令精准导航,成功率可达72.5%,推理效率提升40%
2、2比特复数模型媲美全精度,北大通用框架让大模型在手机上也能流畅运行
3、只用512张H200,106B模型靠分布式RL杀出重围,全网开源
4、智谱开源GLM-4.6V:从看懂图片到自动完成任务
5、5000万元“机器人+大模型”订单落锤!优必选Walker S2年内交付
6、告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%
1、深大团队让机器人听懂指令精准导航,成功率可达72.5%,推理效率提升40%
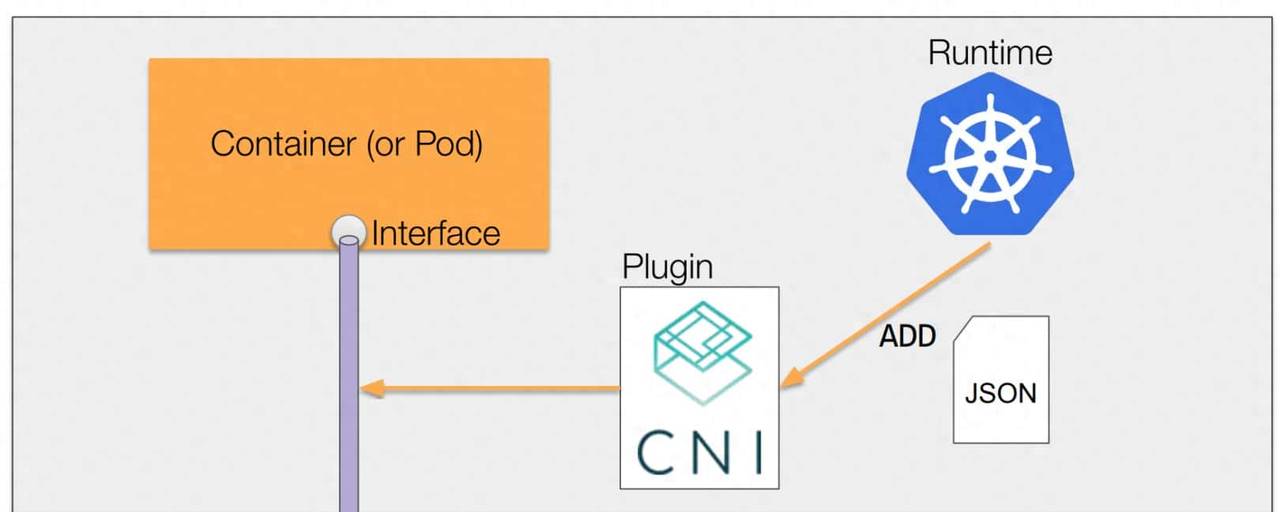
- 深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。
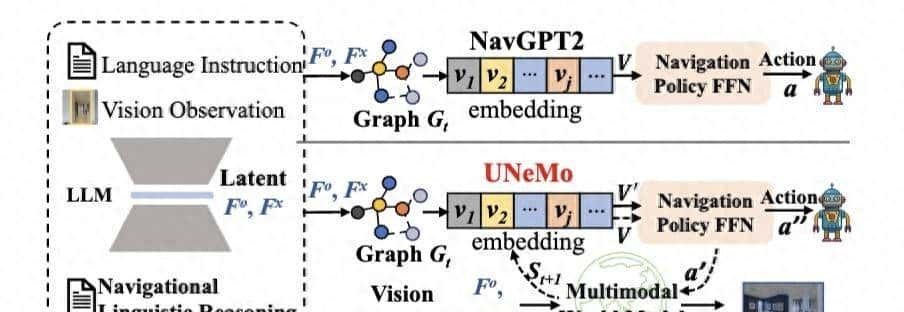
- 通过多模态世界模型与分层预测反馈机制,能够让导航智能体不仅可以看到当前环境,还能预测接下来可能看到的内容,并据此做出更机智的决策。
- 相比主流方法,UNeMo可大幅度降低资源消耗,在未见过的环境中导航成功率可达72.5%,尤其是在长轨迹导航中表现突出。
- 实验结果显示,其在unseen场景的导航成功率(SR)与远程目标定位成功率(RGS)指标上均有提升。
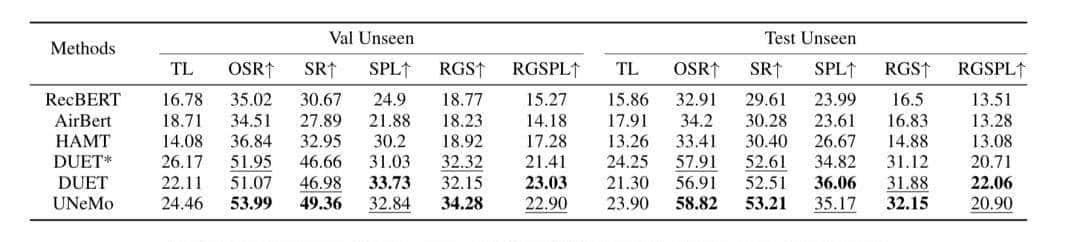
- 这表明UNeMo的协同训练架构并非局限于LLM-based基线,而是能灵活适配不同类型的导航系统,在不同任务场景中释放价值,验证了其强可拓展性。
- 其轻量化配置具备高性能、长路径导航稳健、跨场景适配性强的优势,为VLN提供高效可行方案,助力服务机器人等实际场景落地,推动VLN领域发展。
- 论文链接:https://arxiv.org/abs/2511.18845
2、2比特复数模型媲美全精度,北大通用框架让大模型在手机上也能流畅运行
- 近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。
- Fairy2i针对性地解决了这一痛点,具体表目前:
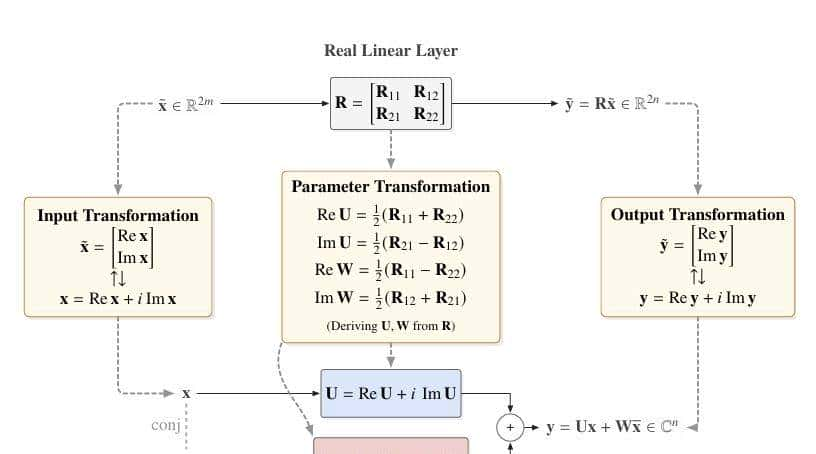
- 广义线性表明:低成本无损继承,打通实数与复数桥梁
在“架构”上,Fairy2i通过解决实数模型如何“变身”复数模型的问题,极大地降低了训练所需的成本。
- 相位感知量化:沿用{±1, ±i}高效编码
- 在“量化”上,Fairy2i继承了iFairy的核心优势。
- 它利用单位圆上的四个四次单位根{+1, -1, +i, -i}作为码本,相比于实数域的二值(+1, -1)或三值(+1, 0, -1)量化,复数域的这四个点充分利用了2-bit的编码空间,具有更高的信息密度和更好的对称性。
- 递归残差量化:极低代价消除误差
- 为了进一步逼近全精度性能,团队提出了递归残差量化(Recursive Residual Quantization) 机制。
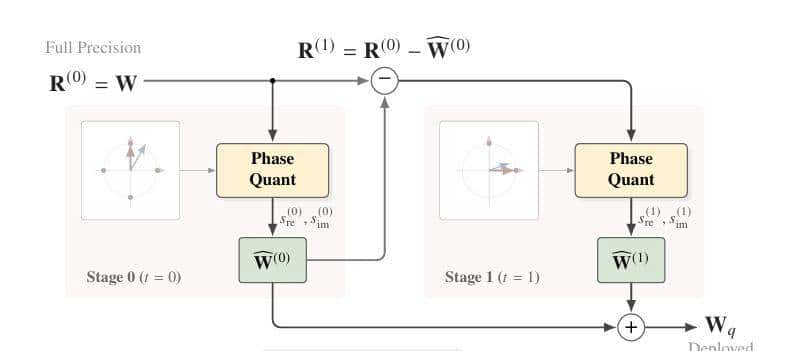
- 既然一次量化有误差,那就对“误差”再进行一次量化,Fairy2i将权重表明为几个低比特项的和。
- 实验表明,仅需T=2的递归阶段(即等效2-bit),就能大幅消除量化噪声。
- 实验结果显示,Fairy2i在LLaMA-2 7B模型上取得了令人瞩目的成绩。
- 在语言建模能力(C4数据集PPL)上,Fairy2i (2-bit)取得了7.85的极低困惑度。
- 论文链接:https://arxiv.org/abs/2512.02901
- HuggingFace:https://huggingface.co/PKU-DS-LAB/Fairy2i-W2
- GitHub: https://github.com/PKULab1806/Fairy2i-W2
- modelscope:https://modelscope.cn/models/PKULab1806/Fairy2i-W2
3、只用512张H200,106B模型靠分布式RL杀出重围,全网开源
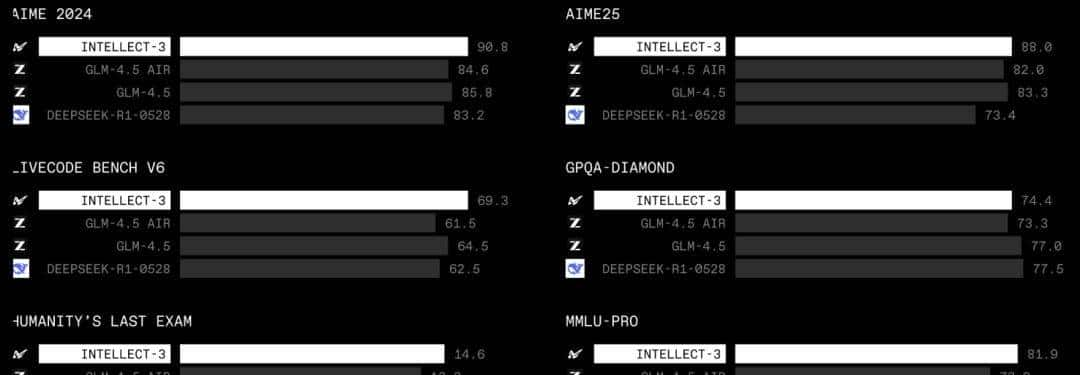
- 最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。
- 在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
- Prime Intellect已经把完整的训练流程——包括模型权重、训练框架、数据集、RL环境和评测体系——全部开源,希望能推动更多关于大规模强化学习的开放研究。
- 训练中,Prime Intellect使用了以下核心组件:
- PRIME-RL:自研的分布式RL框架,支持监督微调和大规模MoE模型的强化学习。
- Verifiers 与 Environments Hub:统一的环境接口与生态,用于各类智能体式RL环境与评测。
- Prime Sandboxes:高吞吐、安全的代码执行系统,用于智能体代码类环境。
- 算力编排:在64个互联节点上的512张NVIDIA H200 GPU完成调度与管理。
- INTELLECT-3完整使用PRIME-RL进行端到端训练。这套框架与Verifiers环境深度整合,支撑从合成数据生成、监督微调、强化学习到评估的整个后训练体系。
- INTELLECT-3主要分两阶段:
- 基于GLM-4.5-Air的监督微调,以及大规模RL训练。
- 两个阶段以及多轮消融实验都在512张H200 GPU上运行,总共持续两个月。
- 研究人员训练了覆盖数学、代码、科学、逻辑、深度研究、软件工程等类别的多样化RL环境,用来提升模型的推理与智能体能力。
- 参考资料:https://www.primeintellect.ai/blog/intellect-3
4、智谱开源GLM-4.6V:从看懂图片到自动完成任务
- 正式上线并开源 GLM-4.6V 系列多模态大模型,包括:
- GLM-4.6V(106B-A12B):面向云端与高性能集群场景的基础版;
- GLM-4.6V-Flash(9B):面向本地部署与低延迟应用的轻量版。
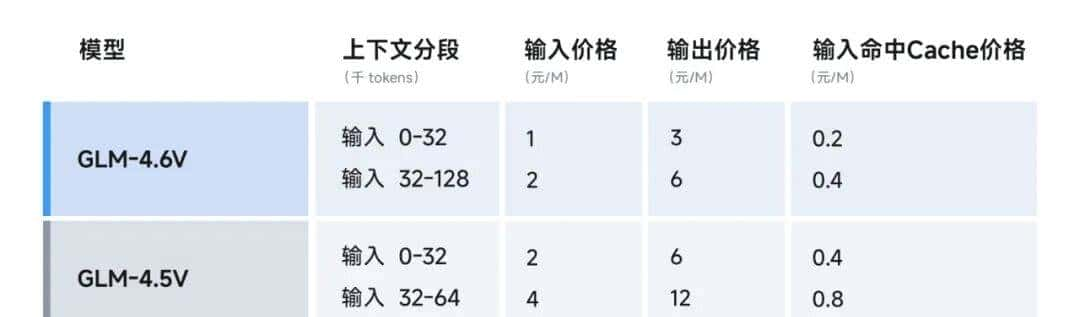
- 作为 GLM 系列在多模态方向上的一次重大迭代,GLM-4.6V 将训练时上下文窗口提升到 128k tokens,在视觉理解精度上达到同参数规模 SOTA,并首次在模型架构中将 Function Call(工具调用)能力原生融入视觉模型,打通从「视觉感知」到「可执行行动(Action)」的链路,为真实业务场景中的多模态 Agent 提供统一的技术底座。
- 在性能优化之外,GLM-4.6V 系列相较于 GLM-4.5V 降价 50%,API 调用价格低至输入 1 元/百万 tokens,输出 3 元/百万 tokens。
- 同时,GLM-4.6V-Flash 免费供大家使用。
- GLM-4.6V 即日起融入 GLM Coding Plan,针对用户 8 大类场景定向开发了专用 MCP 工具,模型可自主调用最匹配的接口。
- GLM-4.6V 的模型权重、推理代码与示例工程,便于快速集成:
- GitHub:https://github.com/zai-org/GLM-V
- Hugging Face:https://huggingface.co/collections/zai-org/glm-46v
- 魔搭社区:https://modelscope.cn/collections/GLM-46V-37fabc27818446
- 开放平台:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-4.6v
- Coding Plan 视觉理解 MCP:https://docs.bigmodel.cn/cn/coding-plan/mcp/vision-mcp-server
- 技术 blog:z.ai/blog/glm-4.6v
5、5000万元“机器人+大模型”订单落锤!优必选Walker S2年内交付
- 优必选科技宣布与国内头部 AI 大模型公司签署销售合同,总金额超0.5亿元人民币,产品为全球首款 自主换电工业人形机器人 Walker S2,将于今年内完成交付。公司同时开放机器人数据接口,支持合作方将自有 AI 大模型与本体深度集成,形成「具身智能+垂直模型+数据」闭环 。
- 交付节奏:年内完成,产能已超300台/月
- 交付量:合同以 Walker S2为主,年内分批交付,全年累计交付有望突破500台
- 产线状态:11月中旬已开启量产,首批数百台投入汽车制造、智能制造、智慧物流与具身智能数据中心等场景
- 产能:无锡工厂月产能超300台,2025全年目标500+ 台
- 技术接口:向大模型厂商开放 SDK
- 接口范围:基础运动控制、多模态感知、任务状态、电池管理
- 合作模式:分阶段交付——硬件→SDK→联合调优→场景落地,支持合作方二次开发与私有模型部署
- 目标:共同攻克「具身智能×复杂大模型」集成难题,探索人形机器人在高复杂场景下的应用潜力
- 产品亮点:自主换电 + Co-Agent + 群体协同
- 自主换电:全球首创热插拔电池系统,实现7×24小时不间断作业,换电过程无需人工干预
- Co-Agent 框架:单机内置专用智能体,可与上位 AI 大模型协同完成高级任务规划、多模态感知与实时控制
- 群体协同:搭载群脑网络2.0,支持多台机器人任务分配与动态调度,适配柔性产线与黑灯工厂
6、告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%
- 来自复旦大学、同济大学与上海创智学院的OpenMoss与SiiRL团队联合提出了自参考策略优化框架(SRPO),通过构建内生自参照评估机制,实现了无需外部专家数据注入、免除任务特定奖励工程的自适适应策略优化。SRPO在LIBERO榜单上以99.2%的成功率刷新SOTA°,在LIBERO–Plus的泛化任务上性能暴涨167%,并能大幅提升m0等开源模型的真机表现。
- 近期研究表明,强化学习作为一种有效的后训练策略,能显著提升 VLA 模型在分布内与分布外的性能。在强化学习方法中,基于组优化的方法(如 GRPO)因其简洁高效的学习范式,已成为 VLA-RL 的重大技术路径,但其仍面临奖励信号稀疏的挑战。
- 该问题在 VLA 领域尤为突出:多轮轨迹推理的计算成本极高,对失败轨迹信息的低效利用严重降低了训练效率。虽有研究尝试通过过程监督提供密集反馈,但这些方法一般依赖专家示范或人工任务分解来定义中间进展,其固有的扩展性局限与自主学习目标存在根本矛盾。
- 该范式的核心挑战在于如何量化成功与失败轨迹之间的行为类似性,以评估任务完成进度。传统像素级世界模型存在跨领域泛化能力不足或需要大量任务特定微调的问题,我们发现潜在世界表征天然捕捉了跨环境可迁移的行为进展模式,使得无需准确环境重建或领域特定训练即可实现鲁棒的轨迹比较。
- 基于以上洞察,团队提出自参考策略优化(SRPO),贡献主要包括以下三方面:
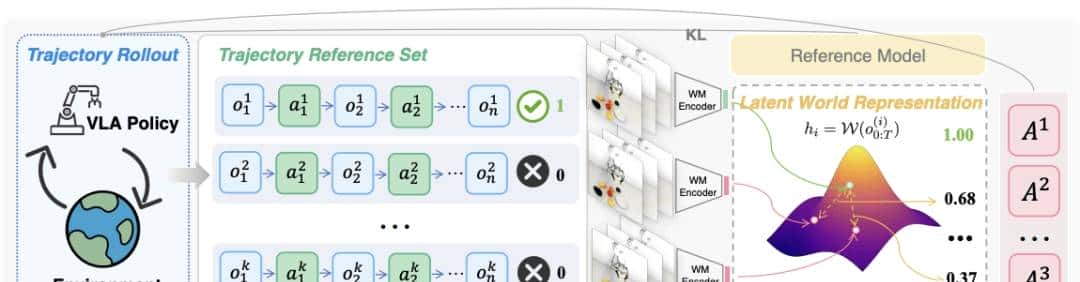
- 提出 SRPO 框架,通过利用模型生成的成功轨迹为失败尝试提供渐进式奖励,缓解奖励稀疏性问题,消除对专家示范或任务特定工程的依赖。
- 提出基于潜在世界表征的渐进式奖励方法,克服传统像素级世界模型的泛化局限与领域特定训练需求。
- 实验结果表明,我们的方法在 LIBERO 基准测试中达到 SOTA 性能,在 LIBERO-Plus 上展现出强劲泛化能力,并验证了奖励建模的真机可迁移性。
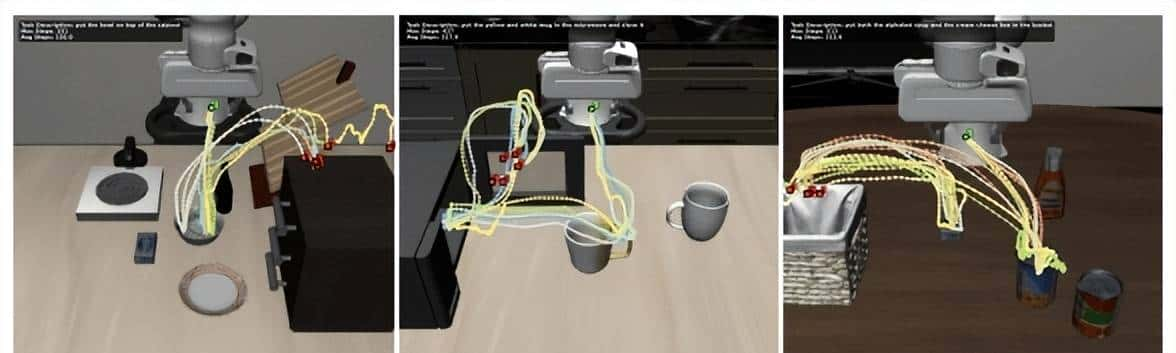
- 研究团队发现SRPO 训练后,模型能够自主探索出多种专家轨迹中不存在的新路径与抓取姿态,如图 6 所示。说明 SRPO 不仅能提升成功率,更能激发机器人超越示范、自主探索新的解决策略。
- 论文链接:https://arxiv.org/pdf/2511.15605
- 代码仓库:https://github.com/sii-research/siiRL
- 技术文档:https://siirl.readthedocs.io/en/latest/examples/embodied_srpo_example.html
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...