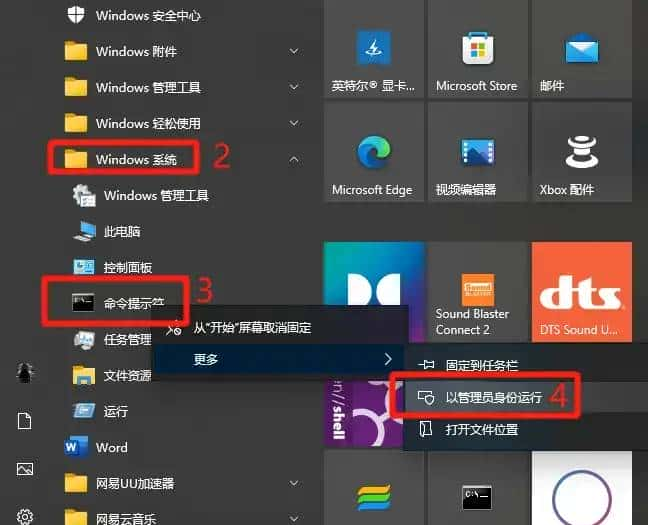
WrenAI+Ollama 本地部署实现自然语言读取数据库
作者:coder_fang
WrenAI 是开源且比较成熟的SQL AI,可以使用Ollama本地模型进行部署,本文是作者多次踩坑后能正确运行的配置,相比官网进行了少许改动。
运行环境:Wrenai:0.27.0,ollama:0.12.5,Windows11 Docker Desktop,3080TI显卡
安装Desktop Docker ,Ollama,本文需要的模型有:qwen2.5:14b,nomic-embed-text:latest,使用ollama pull进行下拉。
创建wren工作目录,目录结构如图:
.env
COMPOSE_PROJECT_NAME=wrenai
PLATFORM=linux/amd64
PROJECT_DIR=.
# service port
WREN_ENGINE_PORT=8080
WREN_ENGINE_SQL_PORT=7432
WREN_AI_SERVICE_PORT=5555
WREN_UI_PORT=3000
IBIS_SERVER_PORT=8000
WREN_UI_ENDPOINT=http://wren-ui:${WREN_UI_PORT}
# ai service settings
QDRANT_HOST=qdrant
SHOULD_FORCE_DEPLOY=1
EMBEDDER_OLLAMA_URL=192.168.1.37
EMBEDDING_MODEL=nomic-embed-text
# vendor keys
OPENAI_API_KEY=
# version
# CHANGE THIS TO THE LATEST VERSION
WREN_PRODUCT_VERSION=0.27.0
WREN_ENGINE_VERSION=0.18.3
WREN_AI_SERVICE_VERSION=0.27.1
IBIS_SERVER_VERSION=0.18.3
WREN_UI_VERSION=0.31.1
WREN_BOOTSTRAP_VERSION=0.1.5
# user id (uuid v4)
USER_UUID=
# for other services
POSTHOG_API_KEY=phc_nhF32aj4xHXOZb0oqr2cn4Oy9uiWzz6CCP4KZmRq9aE
POSTHOG_HOST=https://app.posthog.com
TELEMETRY_ENABLED=true
# this is for telemetry to know the model, i think ai-service might be able to provide a endpoint to get the information
GENERATION_MODEL=gpt-4o-mini
LANGFUSE_SECRET_KEY=
LANGFUSE_PUBLIC_KEY=
# the port exposes to the host
# OPTIONAL: change the port if you have a conflict
HOST_PORT=3000
AI_SERVICE_FORWARD_PORT=5555
# Wren UI
EXPERIMENTAL_ENGINE_RUST_VERSION=false
# Wren Engine
# OPTIONAL: set if you want to use local storage for the Wren Engine
LOCAL_STORAGE=.
config.yaml
type: llm
provider: litellm_llm
models:
- api_base: http://host.docker.internal:11434 # if you are using mac/windows, don't change this; if you are using linux, please search "Run Ollama in docker container" in this page: https://docs.getwren.ai/oss/installation/custom_llm#running-wren-ai-with-your-custom-llm-embedder
model: ollama_chat/qwen2.5-coder:14b # ollama_chat/<ollama_model_name>
timeout: 600
alias: default
kwargs:
n: 1
temperature: 0
---
type: embedder
provider: litellm_embedder
models:
- model: ollama/nomic-embed-text # put your ollama embedder model name here, openai/<ollama_model_name>
api_base: http://host.docker.internal:11434 # if you are using mac/windows, don't change this; if you are using linux, please search "Run Ollama in docker container" in this page: https://docs.getwren.ai/oss/installation/custom_llm#running-wren-ai-with-your-custom-llm-embedder
timeout: 600
alias: default
---
type: engine
provider: wren_ui
endpoint: http://wren-ui:3000
---
type: engine
provider: wren_ibis
endpoint: http://ibis-server:8000
---
type: document_store
provider: qdrant
location: http://qdrant:6333
embedding_model_dim: 768
timeout: 120
recreate_index: true
---
type: pipeline
pipes:
- name: db_schema_indexing
embedder: litellm_embedder.default
document_store: qdrant
- name: historical_question_indexing
embedder: litellm_embedder.default
document_store: qdrant
- name: table_description_indexing
embedder: litellm_embedder.default
document_store: qdrant
- name: db_schema_retrieval
llm: litellm_llm.default
embedder: litellm_embedder.default
document_store: qdrant
- name: historical_question_retrieval
embedder: litellm_embedder.default
document_store: qdrant
- name: sql_generation
llm: litellm_llm.default
engine: wren_ui
document_store: qdrant
- name: sql_correction
llm: litellm_llm.default
engine: wren_ui
document_store: qdrant
- name: followup_sql_generation
llm: litellm_llm.default
engine: wren_ui
document_store: qdrant
- name: sql_answer
llm: litellm_llm.default
- name: semantics_description
llm: litellm_llm.default
- name: relationship_recommendation
llm: litellm_llm.default
engine: wren_ui
- name: question_recommendation
llm: litellm_llm.default
- name: question_recommendation_db_schema_retrieval
llm: litellm_llm.default
embedder: litellm_embedder.default
document_store: qdrant
- name: question_recommendation_sql_generation
llm: litellm_llm.default
engine: wren_ui
document_store: qdrant
- name: intent_classification
llm: litellm_llm.default
embedder: litellm_embedder.default
document_store: qdrant
- name: misleading_assistance
llm: litellm_llm.default
- name: data_assistance
llm: litellm_llm.default
- name: sql_pairs_indexing
document_store: qdrant
embedder: litellm_embedder.default
- name: sql_pairs_retrieval
document_store: qdrant
embedder: litellm_embedder.default
llm: litellm_llm.default
- name: preprocess_sql_data
llm: litellm_llm.default
- name: sql_executor
engine: wren_ui
- name: chart_generation
llm: litellm_llm.default
- name: chart_adjustment
llm: litellm_llm.default
- name: user_guide_assistance
llm: litellm_llm.default
- name: sql_question_generation
llm: litellm_llm.default
- name: sql_generation_reasoning
llm: litellm_llm.default
- name: followup_sql_generation_reasoning
llm: litellm_llm.default
- name: sql_regeneration
llm: litellm_llm.default
engine: wren_ui
- name: instructions_indexing
embedder: litellm_embedder.default
document_store: qdrant
- name: instructions_retrieval
embedder: litellm_embedder.default
document_store: qdrant
- name: sql_functions_retrieval
engine: wren_ibis
document_store: qdrant
- name: project_meta_indexing
document_store: qdrant
- name: sql_tables_extraction
llm: litellm_llm.default
---
settings:
doc_endpoint: https://docs.getwren.ai
is_oss: true
engine_timeout: 30
column_indexing_batch_size: 50
table_retrieval_size: 10
table_column_retrieval_size: 100
allow_intent_classification: true
allow_sql_generation_reasoning: true
allow_sql_functions_retrieval: true
enable_column_pruning: false
max_sql_correction_retries: 3
query_cache_maxsize: 1000
query_cache_ttl: 3600
langfuse_host: https://cloud.langfuse.com
langfuse_enable: true
logging_level: DEBUG
development: false
historical_question_retrieval_similarity_threshold: 0.9
sql_pairs_similarity_threshold: 0.7
sql_pairs_retrieval_max_size: 10
instructions_similarity_threshold: 0.7
instructions_top_k: 10
docker-compose.yaml
version: "3"
volumes:
data:
networks:
wren:
driver: bridge
services:
bootstrap:
image: ghcr.io/canner/wren-bootstrap:${WREN_BOOTSTRAP_VERSION}
restart: on-failure
platform: ${PLATFORM}
environment:
DATA_PATH: /app/data
volumes:
- data:/app/data
command: /bin/sh /app/init.sh
wren-engine:
image: ghcr.io/canner/wren-engine:${WREN_ENGINE_VERSION}
restart: on-failure
platform: ${PLATFORM}
expose:
- ${WREN_ENGINE_PORT}
- ${WREN_ENGINE_SQL_PORT}
volumes:
- data:/usr/src/app/etc
- ${PROJECT_DIR}/data:/usr/src/app/data
networks:
- wren
depends_on:
- bootstrap
ibis-server:
image: ghcr.io/canner/wren-engine-ibis:${IBIS_SERVER_VERSION}
restart: on-failure
platform: ${PLATFORM}
expose:
- ${IBIS_SERVER_PORT}
environment:
WREN_ENGINE_ENDPOINT: http://wren-engine:${WREN_ENGINE_PORT}
volumes:
- ${LOCAL_STORAGE:-.}:/usr/src/app/data
networks:
- wren
wren-ai-service:
image: ghcr.io/canner/wren-ai-service:${WREN_AI_SERVICE_VERSION}
restart: no
platform: ${PLATFORM}
expose:
- ${WREN_AI_SERVICE_PORT}
ports:
- ${AI_SERVICE_FORWARD_PORT}:${WREN_AI_SERVICE_PORT}
environment:
# sometimes the console won't show print messages,
# using PYTHONUNBUFFERED: 1 can fix this
PYTHONUNBUFFERED: 1
CONFIG_PATH: /app/config.yaml
LOG_LEVEL: DEBUG
LOGGING_LEVEL: DEBUG
env_file:
- ${PROJECT_DIR}/.env
volumes:
- ${PROJECT_DIR}/config.yaml:/app/config.yaml:ro
- ${PROJECT_DIR}/data:/app/data:ro
- ${PROJECT_DIR}/entrypoint.sh:/app/entrypoint.sh:rw
networks:
- wren
depends_on:
- qdrant
qdrant:
image: qdrant/qdrant:v1.11.0
restart: on-failure
expose:
- 6333
- 6334
volumes:
- data:/qdrant/storage
networks:
- wren
wren-ui:
image: ghcr.io/canner/wren-ui:${WREN_UI_VERSION}
restart: on-failure
platform: ${PLATFORM}
environment:
DB_TYPE: sqlite
# /app is the working directory in the container
SQLITE_FILE: /app/data/db.sqlite3
WREN_ENGINE_ENDPOINT: http://wren-engine:${WREN_ENGINE_PORT}
WREN_AI_ENDPOINT: http://wren-ai-service:${WREN_AI_SERVICE_PORT}
IBIS_SERVER_ENDPOINT: http://ibis-server:${IBIS_SERVER_PORT}
# this is for telemetry to know the model, i think ai-service might be able to provide a endpoint to get the information
GENERATION_MODEL: ${GENERATION_MODEL}
# telemetry
WREN_ENGINE_PORT: ${WREN_ENGINE_PORT}
WREN_AI_SERVICE_VERSION: ${WREN_AI_SERVICE_VERSION}
WREN_UI_VERSION: ${WREN_UI_VERSION}
WREN_ENGINE_VERSION: ${WREN_ENGINE_VERSION}
USER_UUID: ${USER_UUID}
POSTHOG_API_KEY: ${POSTHOG_API_KEY}
POSTHOG_HOST: ${POSTHOG_HOST}
TELEMETRY_ENABLED: ${TELEMETRY_ENABLED}
# client side
NEXT_PUBLIC_USER_UUID: ${USER_UUID}
NEXT_PUBLIC_POSTHOG_API_KEY: ${POSTHOG_API_KEY}
NEXT_PUBLIC_POSTHOG_HOST: ${POSTHOG_HOST}
NEXT_PUBLIC_TELEMETRY_ENABLED: ${TELEMETRY_ENABLED}
EXPERIMENTAL_ENGINE_RUST_VERSION: ${EXPERIMENTAL_ENGINE_RUST_VERSION}
# configs
WREN_PRODUCT_VERSION: ${WREN_PRODUCT_VERSION}
ports:
# HOST_PORT is the port you want to expose to the host machine
- ${HOST_PORT}:3000
volumes:
- data:/app/data
networks:
- wren
depends_on:
- wren-ai-service
- wren-engine
entrypoint.sh,此文件映射出来的目的是修改TIMEOUT时间,因为在机器性能不是很强的情况下,wrenai-wren-ai-service 会出现timeout问题,60秒就会自动退出,导致服务无法启动,在本机中设置成100即可正常启动
#!/bin/bash
set -e
INTERVAL=1
TIMEOUT=100
# Wait for qdrant to be responsive
echo "Waiting for qdrant to start..."
current=0
while ! nc -z $QDRANT_HOST 6333; do
sleep $INTERVAL
current=$((current + INTERVAL))
if [ $current -eq $TIMEOUT ]; then
echo "Timeout: qdrant did not start within $TIMEOUT seconds"
exit 1
fi
done
echo "qdrant has started."
# Start wren-ai-service in the background
uvicorn src.__main__:app --host 0.0.0.0 --port $WREN_AI_SERVICE_PORT --loop uvloop --http httptools &
if [[ -n "$SHOULD_FORCE_DEPLOY" ]]; then
# Wait for the server to be responsive
echo "Waiting for wren-ai-service to start..."
current=0
while ! nc -z localhost $WREN_AI_SERVICE_PORT; do
sleep $INTERVAL
current=$((current + INTERVAL))
if [ $current -eq $TIMEOUT ]; then
echo "Timeout: wren-ai-service did not start within $TIMEOUT seconds"
exit 1
fi
done
echo "wren-ai-service has started."
# Wait for wren-ui to be responsive
echo "Waiting for wren-ui to start..."
current=0
while ! nc -z wren-ui $WREN_UI_PORT && ! nc -z host.docker.internal $WREN_UI_PORT; do
sleep $INTERVAL
current=$((current + INTERVAL))
if [ $current -eq $TIMEOUT ]; then
echo "Timeout: wren-ui did not start within $TIMEOUT seconds"
exit 1
fi
done
echo "wren-ui has started."
echo "Forcing deployment..."
python -m src.force_deploy
fi
# Bring wren-ai-service to the foreground
wait
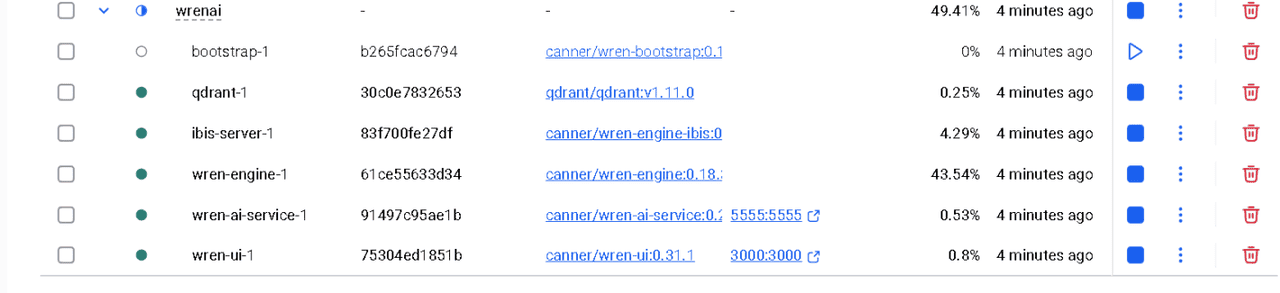
进入到工作目录,使用命令行运行,docker-compose up -d,首次会下拉相关镜像,启动成功后如图:
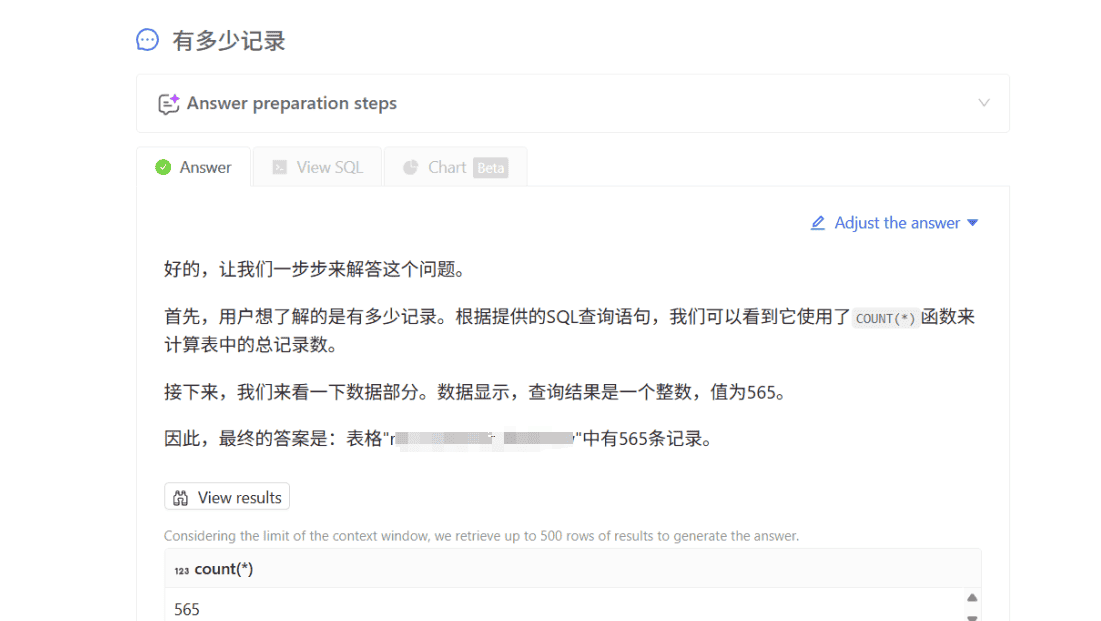
运行localhost:3000,根据官网进行数据库配置,模型配置,完成部署:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...




