

一般,在使用 Google Protobuf 等库时,您不会思考它们可能做错的实际,您只是信任它们。
几十年来,我们一直在使用 Google Protobuf,但是当我们开始在生产中使用 Golang 和 Google Protobuf 时,我们面临着可怕的性能问题,尽管我们像往常一样做所有事情。
在构建我们的数据仓库时,我们发明了 nerve,这是我们的小型 Golang 库,用于高效处理以队列形式呈现的大量数据。 目前,我们可以使用 nerve 在 MacBook 上每秒读取大约 650 000 条消息。 我们在生产服务器上的绝对读取速度记录是每秒 230 万条消息。 不过,当我们尝试处理所有这些消息时,我们面临着可怕而戏剧性的速度下降。 而不是处理数百万条消息,我们只能处理 20 000 条,发现这个问题的根本缘由是解析 protobuf 消息的速度。
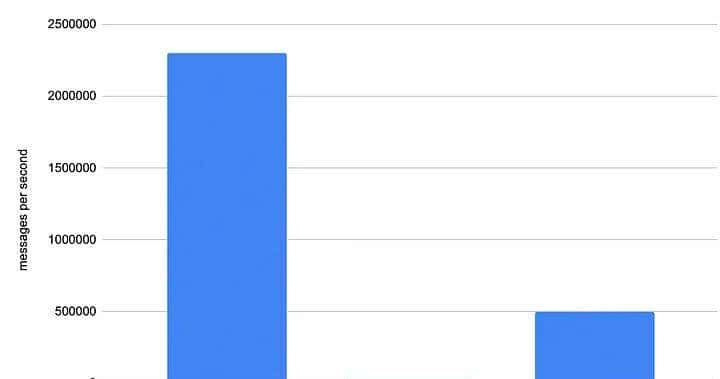
试着想象一下那种感觉,当你每秒能够从数据库中读取数百万条消息,但只能解析 2 万条时。
所以我们的第一个想法是简单地尝试并发解析,但是我们每秒无法获得超过 50 万条消息,并且该过程导致 CPU 使用率超级高。 发生这种情况有两个缘由。 第一个缘由是反思; 但是,第二个缘由是超级出乎意料的,并且存在于内部锁中。 如果消息具有可变结构,则会导致锁定每个新的复杂字段。
正是在这一点上,我们开始寻找可以解决上述问题的替代方案,并解决以下协议问题:
当你想使用 Protobuf 时,你需要安装适当的 protoc 二进制文件,有时还需要安装特定语言的二进制文件(例如 Golang Protobuf 插件)。 因此,您有多个需要维护的外部依赖项。

但我们的搜索没有结果,所以我们创建了自己的库,可以超级快速、高效地处理 protobuf 消息,同时还具有巨大的速度储备。 我们将这个新库称为“gremlin”。
在前面,我们实现了每秒 30,000,000 条消息的解析速度和每秒 87,000,000 条消息的序列化速度。 与谷歌相比,它的阅读速度快了大约 60 倍,写作速度快了 20 倍。
是怎么做到的?
1.解析
第一个关键点超级明显——省略反射和锁。 没有反射意味着没有开销,也没有复杂的逻辑。
但我们能做得更好吗?

我们可以。 我们可以使所有解析变得惰性。
在事件总线架构中的大型复杂消息中,每个特定阶段一般只需要一小部分数据。 例如,如果我们尝试计算用户的存款总额,我们不需要 IP 地址、用户代理或任何其他元数据。 我们只需要事件的类型和金额。 所以如果我们停止解析整个消息,我们可以获得几乎无限的解析速度。
但这并非没有它的复杂性,由于它会在这种惰性结构的序列化方面产生许多问题。 锁、默认值、复杂的逻辑——所有这些都可能成为未来“痛苦”的来源。
我们怎样才能防止这种情况发生?
我们可以通过分离解析和序列化来避免这种复杂性。
因此,我们为每种 protobuf 消息类型创建了两个结构:
- MessageReader
- Message
MessageReader 用于延迟解析,而 Message 仅用于序列化。
在阅读器中,我们只需要存储所有字段的原始字节和偏移量,我们不需要“解析”整个消息。
例如,对于以下 protobuf 定义:
message Example {
string name = 1;
}reader的用法将如下所示:
reader := proto.NewExampleReader();
if err := reader.Unmarshal(data); err != nil {
// handle err
}
reader.GetName() // 转到底层偏移量并只读取一次名称。2. 序列化
与解析的情况一样,优化的第一步是删除反射。 但是,与解析一样,我们有另一个想法。
在查看 Google protobuf Golang 编组(和 gogofast)时,我们发现有许多分配。 在我们的例子中——每个操作 14 个分配。 但实际上,我们只需要一个。 我们总是可以为包括所有子消息在内的整个消息分配具有可预测大小的字节数组,并将所有结构序列化为一个[]字节。 这是另一个游戏规则改变者:我们得到了 156 ns/op,而不是 428 ns/op。
此外,丢弃反射的另一个毋庸置疑的优势是序列化不会失败。 一个基本的序列化示例如下所示:
writer := &proto.Example{
Name: "foo",
}
messageBytes := writer.Marshal()而不是谷歌protobuf:
writer := &proto.Example{
Name: "foo",
}
messageBytes, err := proto.Marshal(writer)
if err != nil {
// ????
}3. 降低复杂性
在使用 protobuf 时,我们发现了一种将通信协议与数据描述语言和业务逻辑混合在一起的趋势。
结果,有许多复杂性和许多扩展。 一些解决方案实际上涉及尝试使用插件来增加更多的复杂性。 但就数十年的生产使用而言,很难为此类事情提供支持。 此外,目前并非所有语言都支持所有 protobuf 功能,某些操作可能因语言而异。
因此,为了使我们的解决方案更简单、更稳定,我们只删除:
- 所有 protobuf 插件和扩展
- grpc
- oneof’s
- 任何不推荐使用的东西,例如 `groups`
- protoc
结果
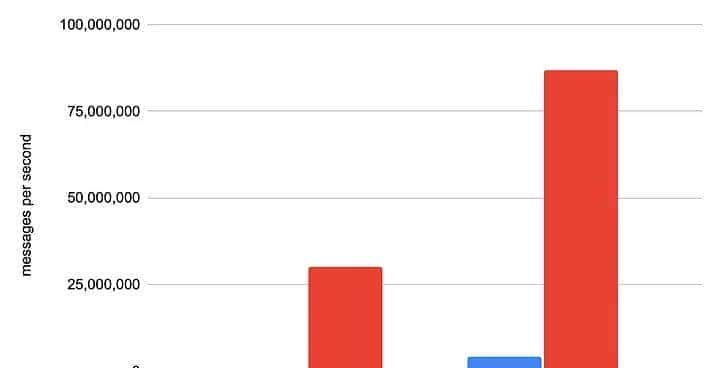
因此,我们不仅开发了一个快速、简单的 protobuf Golang 库,并且可以添加其他语言,而且我们还显着降低了生产服务器上的 CPU 使用率,在某些情况下高达 30%。
如何使用
gremlin 和 nerve 都可以作为我们octopus框架的一部分使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











