
一、学前花絮
Python 爬虫是一种自动化获取互联网数据的工具,核心价值在于高效、批量地从网页/API 中提取结构化或非结构化信息。其应用场景广泛,涵盖商业、学术、生活服务等多个领域,但需始终遵守合法合规原则(如尊重 robots.txt、不爬取敏感数据、控制请求频率)。
二、Python爬虫实战
学习 Python 爬虫的核心是模拟浏览器行为获取数据,并从网页中提取有用信息。以下分两部分说明:必备知识和最简爬取示例。
2.1 学习爬虫需掌握的核心知识
1. 基础网络协议(HTTP/HTTPS)
爬虫本质是发送 HTTP 请求并接受响应,需理解:
- 请求方法:常用 GET(获取数据)、POST(提交数据);
- 请求头(Headers):如 User-Agent(模拟浏览器身份)、Cookie(维持登录状态);
- 状态码:200(成功)、403(禁止访问)、404(页面不存在)等;
- URL 结构:协议(http/https)、域名、路径、参数(如 ?page=1)。
2. HTML 结构与解析
网页数据一般嵌套在 HTML 标签中(如 <div>、<a>、<h1>),需掌握:
- 基本标签含义(如 <title>是标题,<a href=””>是链接);
- 用解析库提取标签内的文本、属性(如链接地址 href)。
3. Python 爬虫工具库
- 请求库:requests(发送 HTTP 请求,最常用)、urllib(Python 内置,较繁琐);
- 解析库:BeautifulSoup(简单易用,适合新手)、lxml(速度快,支持 XPath)、re(正则表达式,灵活但复杂);
- 存储库:csv/json(存文件)、pandas(数据分析)、sqlite3(轻量数据库);
- 反爬应对:fake_useragent(随机 User-Agent)、time.sleep()(控制请求频率)、代理 IP(如 requests+ 代理池)。
4. 法律与道德规范
- 遵守网站 robots.txt协议(如 https://www.example.com/robots.txt,查看允许爬取的路径);
- 不爬取敏感数据(个人隐私、付费内容);
- 控制请求频率(避免给服务器造成压力)。
2.2 最简爬取示例:爬取静态网页标题
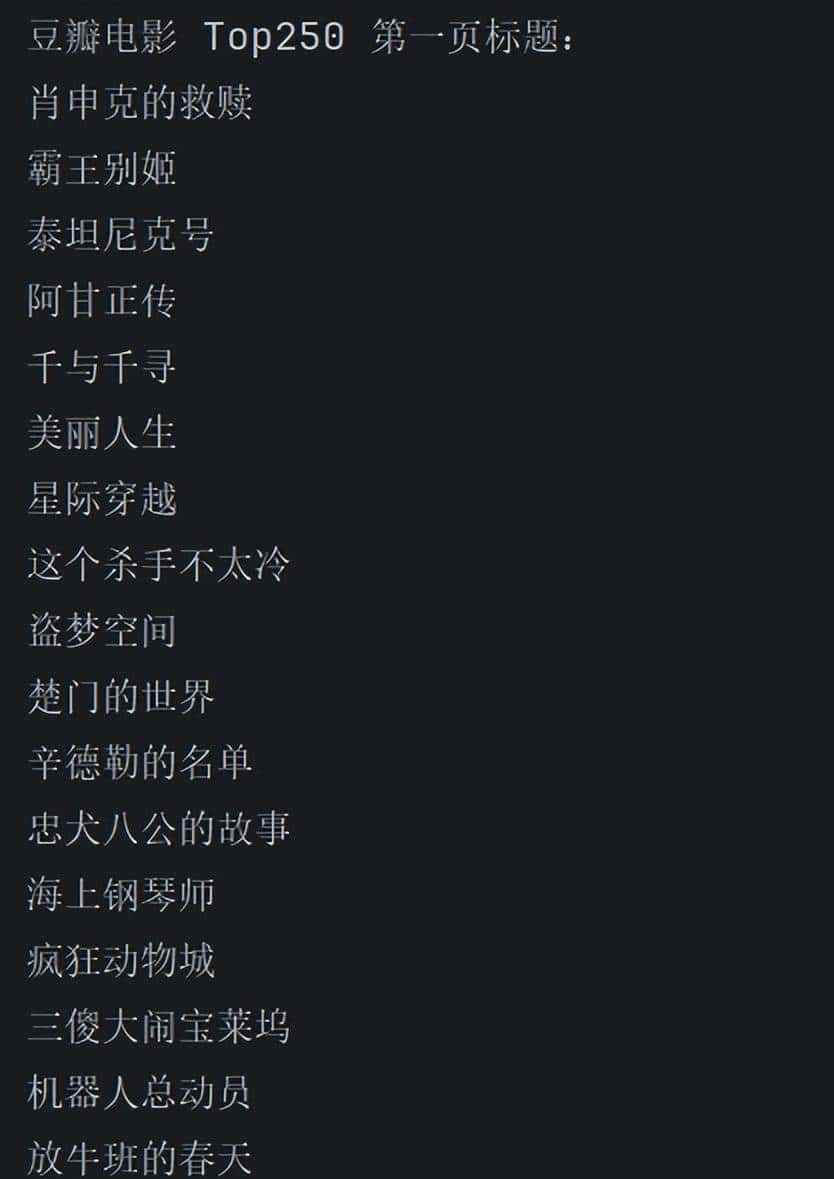
以爬取 豆瓣电影 Top250 第一页的电影标题 为例(静态 HTML,无复杂反爬),步骤如下:
步骤 1:安装必要库
|
pip install requests beautifulsoup4 # 安装请求库和解析库 |
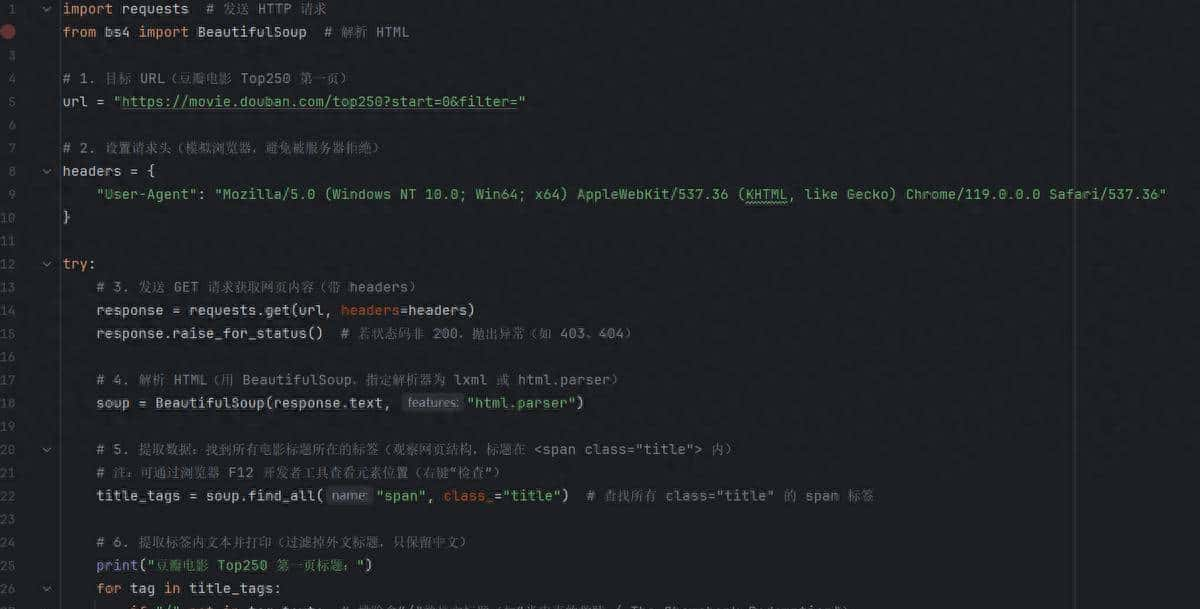
步骤 2:编写代码(附注释)
运行结果:
2.3 代码核心逻辑说明
- 发送请求:用 requests.get(url, headers=headers)模拟浏览器访问,避免被服务器识别为爬虫;
- 解析 HTML:用 BeautifulSoup将网页文本转为可操作的“标签树”,通过 find_all(标签名, 属性)定位目标数据;
- 提取数据:从标签对象中获取文本(tag.text)或属性(如 tag[“href”]获取链接);
- 异常处理:用 try-except捕获请求失败、解析错误等问题。
2.4 存储数据到文件
爬取的网站数据一般都很长,可以将内容存储到文件:
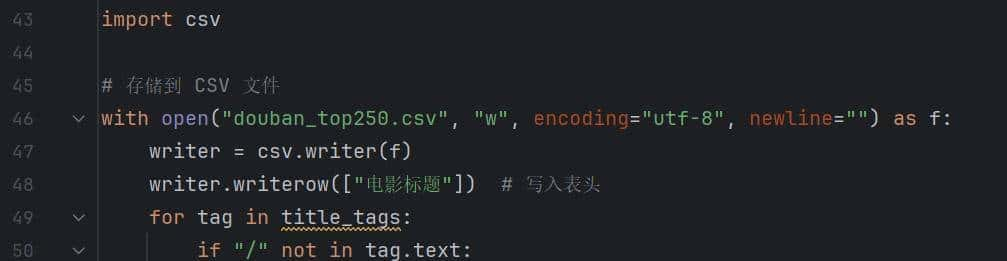
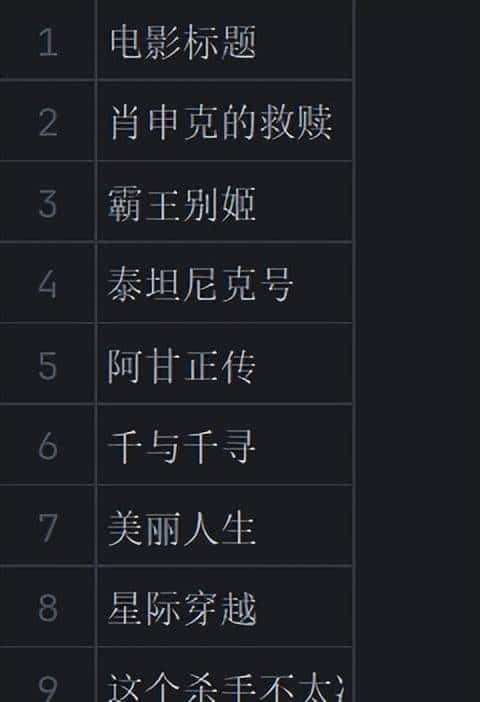
以上程序生成”douban_top250.csv”,可以查看该文件:
对以上学习内容的总结:
爬虫的本质是“请求→解析→存储”,入门只需掌握 requests(请求)+ BeautifulSoup(解析)+ 基础 HTML 知识。后续可进阶学习动态网页爬取(Selenium/Playwright)、反爬应对(代理/IP 池)、分布式爬虫(Scrapy 框架)等。始终记住:合法合规爬取,尊重网站规则。
三、小结
Python 爬虫是数据时代的“挖掘机”,能将互联网上的“信息碎片”转化为可利用的资源,支撑商业决策、学术研究、生活服务等场景。但核心价值不在于“爬取能力”,而在于数据背后的分析与应用。使用时需牢记:合法合规是前提,数据价值是目标。
让我们保持学习热烈,多做练习。我们下期再见!

快乐男孩
#python#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

您必须登录才能参与评论!
立即登录







收藏了,感谢分享
好好学习
持续性学习