
前几天在 Mac 上安装了 Ollama,并下载了通义千问的视觉模型做了些测试,整个过程还挺有意思,值得说道说道。
这个体验颠覆了许多 人对 大模型必须依赖云端的认知,原来在个人电脑上,也能拥有一个强劲的本地智能助手 。

Ollama 是一个能让用户在个 人电脑上 轻松运行大语言模型 的框架,它把复杂的部署过程打包,变成一个简单的应用程序,用户下载安装后,就能通过命令行或者图形界面,一键下载并运行 各种开源模型,这就像给电脑装上了一个“模型商店”,大大降低了普通人接触和使用尖端人工智能技术的门槛。
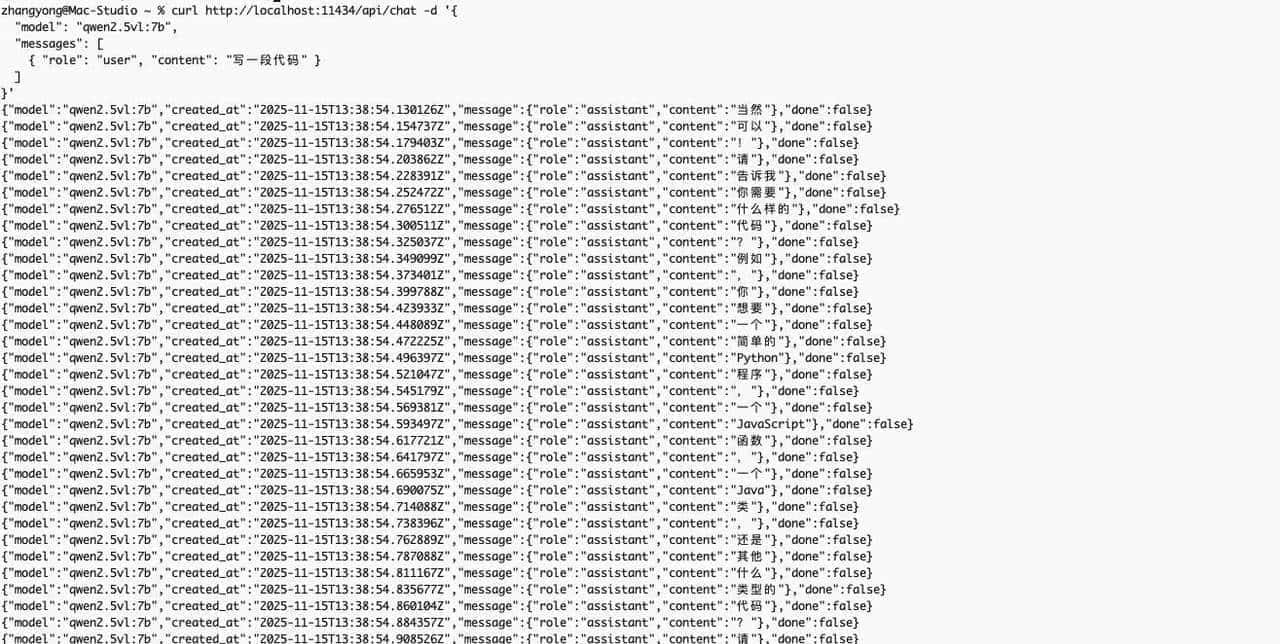
这次测试的主角是通义千问团队的 Qwen2,5-VL 7B 模型,这里的“VL”代表视觉语言,意味着它不仅懂文字,还能看懂图片和视频,7B 则表明模型的参数量是七十亿,这是一个在性能和资源消耗之间取得精妙平衡的尺寸,安装过程超级直接,无论是通过命令行输入指令,还是在 Ollama 的界面 里点击下载,都相当顺畅, 下载完成后,一个强劲的多模态模型就在本地准备就绪了。

把人工智能模型“请”回自己电脑,这事儿实则没那么玄乎,过去大家总觉得,这些机智的大家伙都住在遥远的云端服务器机房里,需要庞大的算力支持,但目前,Ollama 这类工具的出现,彻底改变了游戏规则,它就像一个翻译官,把那些复杂的模型语言,转化成我们个人电脑能听懂的指令,让模型在本地跑 起来。
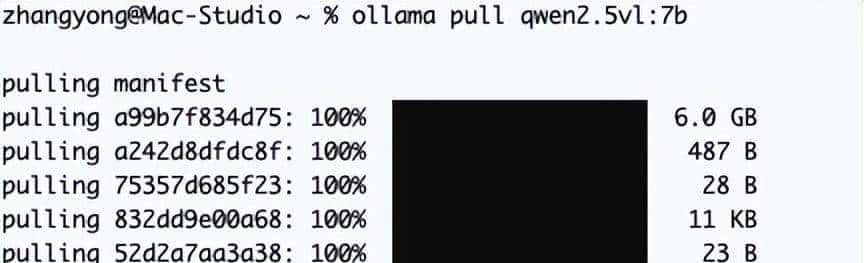
这背后实则是一种技术趋势的体现,就是“边缘计算”和“模型小型化”,大公司们不再只追求把模型做得更大更强,也在努力把它们变得更小更高效,通义千问的 Qwen 系列就是一个很好的例子,它有从十亿级别到几百亿级别的多种参数规模,7B(七十亿参数)这个版本,被很 多人称为“甜点级”模型,它不像那些千亿巨无霸那么吃资源,但能力又远超那 些小模型,足以应对大部分日常的图文处理任务。

在本地运行模型,最大的好处就是数据隐私和安全,你所有的对话、上传的图片,都只在你的电脑 内部处理,完全不经过互联网,这意味着,那些涉及个人隐私或者公司机密的信息,可以放心地交给它处理,再也不用 担心被泄露,而且,本地运行没有网络延迟,反应速度飞快, 还能省下一笔调用云端服务的费用,当然,这一切的前提是,你的电脑配置得跟得上。

网友评论:“电脑配置怎样才能跑7 B,CPU 8核以上,内存16 GB+,显 卡推荐8GB+显存,” 说的没错,想让这些本地模型跑得欢,硬件的确 是道坎,不过,这也催生了新的硬件升级需求,算是给平静的个人电脑市场注入了新活力。

本地部署大模型,象征着人工智能技术从“云端神坛”走向“寻常百姓家”的关键一步,这不仅仅是技术上的突破,更是一种理念的转变,它意味着,强劲的智能不再是少数科技巨头的专属工具,而是每个拥有合适电脑的个人都能掌握的力量,这种转变,让开发者有了更大的自由度,可以创造出更具个性化、更保护隐私的应用。

未来的挑战也很明显,随着模型越来越强劲,对硬件的要求也会水涨船高,如何平衡模型性能和硬件成本,将是决定本地人工智能能否普及的关键,同时,当每个人都能轻松部署和微调模型时,如何确保技术的善用,防止被用于制造虚假信息 等恶意行为,也成了一个必须面对的社会 议题,这股浪潮才刚刚开始,未来的路还很长。
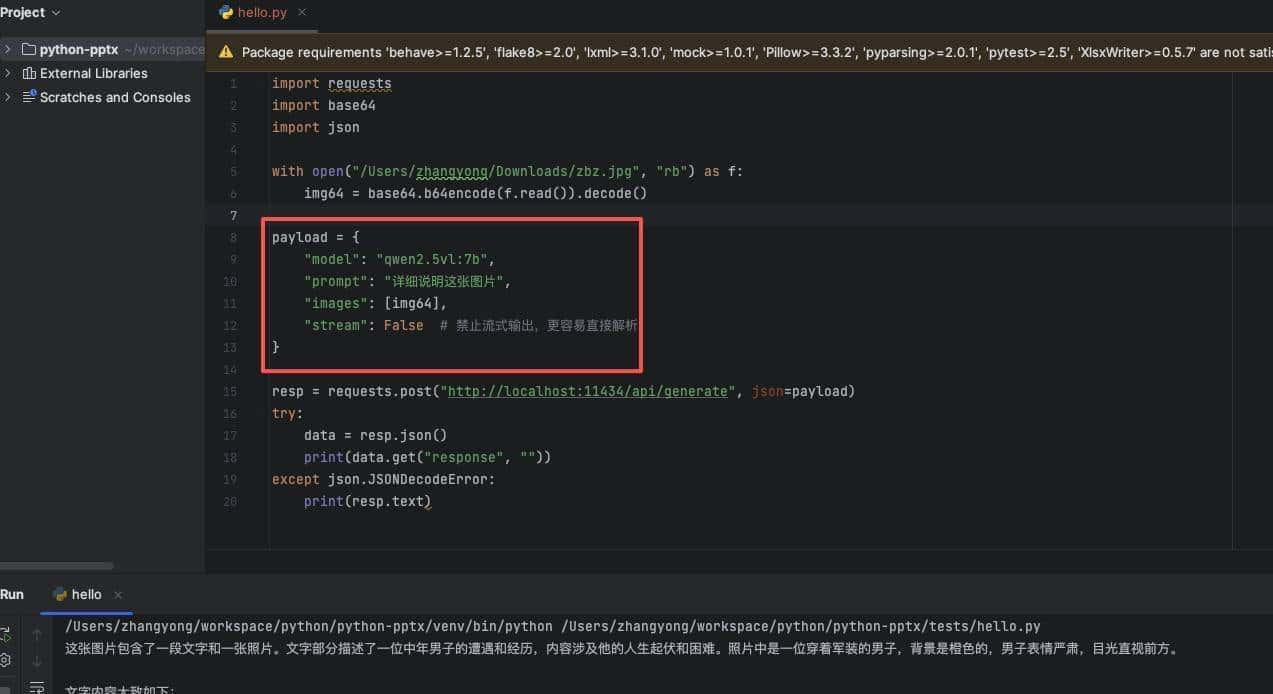
总结来看,在个人电脑上运行大模型,已经从极客的专属乐趣,变成了触手可及的现实,这不仅带来了数据安全和即时响应的好处, 也预示着人工 智能应用将迎来一波新的 创新浪潮,不过,一个有趣的反常识现象是,当技术工具变得越来越“傻瓜化” 时,使用者的创造力门槛反而可能在无形中被提高了,由于当工具不再是障碍,真正比拼的就是想法和创意本身了。
说实话,把这么个“小钢炮”装进自己电脑里 ,感觉挺爽的,就像是拥有了一个私人定制的超级大脑,随时待命,还不用担心它把你的小秘密到处乱说,以前总觉得人工智能离我们很远,目前发现,它实则就在我们身边,甚至就在我们的硬盘里,这种感觉,有点科幻,又有点亲切,它不再是冷冰冰的代码,更像一个可以随时交 流的伙伴。
你觉得本地AI会普及吗?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...








