【AI学习-comfyUI学习-抠图+实时图像裁剪-各个部分学习-第九节1】
1,前言2,说明1:1-inspynet抠图工作流说明2:实时图像裁剪
3,流程1-inspynet抠图工作流(1)调用模块整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片(5)模块介绍参数说明🧩 一、加载图像(Load Image)🧠 二、Inspyrnet Rembg Advanced(核心节点)🧩 输出端口:
2-实时图像裁剪(1)调用模块整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片(5)模块介绍参数说明
🧩 一、Checkpoint加载器(简易)🧠 二、CLIP文本编码器(绿色)—— 正向提示词🚫 三、CLIP文本编码器(红色)—— 负面提示词🌫️ 四、空Latent(初始化潜空间)⚙️ 五、K采样器(核心生成器)🎨 六、VAE解码(VAE解码器)✂️ 七、图像裁剪(Image Crop)
4,细节部分5,使用的工作流1:1-inspynet抠图工作流说明2:实时图像裁剪
6,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1:1-inspynet抠图工作流说明
ComfyUI 的「Inspyrnet 抠图工作流」,用于自动去除图片背景(即“Rembg”功能)。
整个流程非常简洁,是一个“输入 → 抠图 → 输出”的轻量结构。
| 目标 | 调整建议 |
|---|---|
| 想单独保留人物 | threshold ≈ 0.85–0.9 |
| 想保留头发细节 | threshold ≈ 0.7–0.8 |
| 背景太复杂 | 可先用 |
| 想替换背景 | 将输出的 mask 用在“图像合成”节点(如 Combine / Blend)中 |
2:实时图像裁剪
一个完整的 ComfyUI 文生图工作流(Text-to-Image Workflow)+ 图像裁剪(Image Crop)
Checkpoint加载模型(主风格)
↓
CLIP文本编码(正向/负向)
↓
空Latent生成画布
↓
K采样器生成潜空间图
↓
VAE解码为图像
↓
(可选)裁剪 → 预览 → 保存
3,流程
1-inspynet抠图工作流
(1)调用模块
整个模块部分
这回整个模块都可以截截图下了

(2)输出 提示词
无
(3)模型加载
无
(4)生成图片
(1)原图片

(2)抠出的图

(5)模块介绍参数说明
🧩 一、加载图像(Load Image)
作用:
从本地上传或加载一张图片,作为抠图的输入源。
| 参数 | 含义 | 建议 / 说明 |
|---|---|---|
| 图片 | 上传的原始图像 | 点击“选择文件上传”选择输入图 |
| 过滤 | 是否启用图像过滤 | 一般不用改,保持默认 |
🟢 说明:
此节点会输出一个 IMAGE 类型数据,连接到后续处理模块。这一步只是读取图片,不做任何变换。
🧠 二、Inspyrnet Rembg Advanced(核心节点)
这是整个工作流的主逻辑模块,负责 人物/物体抠图与背景去除。
| 参数 | 含义 | 默认值 | 建议值 / 说明 |
|---|---|---|---|
| image | 输入图像 | — | 连接自“加载图像”节点 |
| threshold | 掩模阈值(0~1) | 0.85 | 控制抠图精度(越高越严格) |
| torchscript_jit | 模型加载方式 | |
可选 |
🧩 输出端口:
| 输出口 | 类型 | 说明 |
|---|---|---|
| IMAGE | 抠完背景的图像(透明背景 PNG) | |
| MASK | 掩模图(白色为主体,黑色为背景) |
2-实时图像裁剪
(1)调用模块
整个模块部分
这回整个模块都可以截截图下了,如下图所示
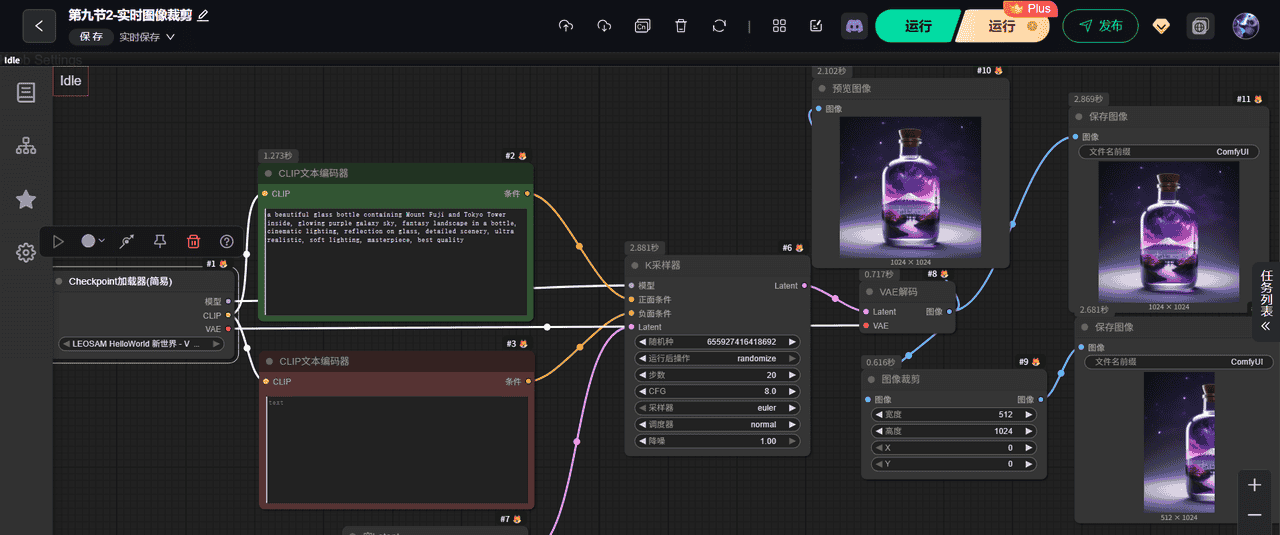
(2)输出 提示词

a beautiful glass bottle containing Mount Fuji and Tokyo Tower inside, glowing purple galaxy sky, fantasy landscape in a bottle, cinematic lighting, reflection on glass, detailed scenery, ultra realistic, soft lighting, masterpiece, best quality
(3)模型加载

(4)生成图片
(1)原图片

(2)切出的一半图

(5)模块介绍参数说明
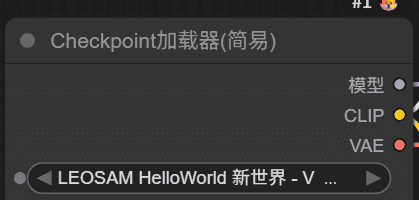
🧩 一、Checkpoint加载器(简易)
模块名:
Checkpoint加载器(简易)
加载模型:
LEOSAM HelloWorld 新世界-V
| 参数 | 说明 |
|---|---|
| 模型路径 | 加载主模型(即 |
| CLIP | 文本编码模块,用于解析Prompt。自动匹配主模型。 |
| VAE | 解码器模块,用于将潜空间图像转为可视图像。 |
🔹 作用:决定整体画风(HelloWorld 模型偏向梦幻、光影柔和)。
🔹 建议:
想要水墨、写实、动漫风,可以替换不同的 Checkpoint。不建议频繁改动 CLIP/VAE 除非模型失配。
🧠 二、CLIP文本编码器(绿色)—— 正向提示词
模块名:
CLIP文本编码器
作用: 将文字 Prompt 转换为语义向量供模型理解。
当前 Prompt:
a beautiful glass bottle containing Mount Fuji and Tokyo Tower inside, glowing purple galaxy sky, fantasy landscape in a bottle, cinematic lighting, reflection on glass, detailed scenery, ultra realistic, soft lighting, masterpiece, best quality
🔹 解释:
glass bottle containing Mount Fuji and Tokyo Tower inside
purple galaxy sky
fantasy landscape in a bottle
cinematic lighting
reflection on glass
ultra realistic
masterpiece
best quality
🔹 调整技巧:
想让瓶子更透明:加
clear glass, realistic reflection
Tokyo Tower glowing red lights
night city skyline, bokeh background
🚫 三、CLIP文本编码器(红色)—— 负面提示词
模块名:
CLIP文本编码器
作用: 告诉模型要“避免”的内容。
当前内容:
text
🔹 建议补充完整 Negative Prompt:
low quality, blurry, distorted, watermark, text, extra objects, bad lighting, bad composition, lowres, artifacts, ugly
这样可以防止出现:
模糊边缘多余物体画面过暗或溢色
🌫️ 四、空Latent(初始化潜空间)
模块名:
空Latent
| 参数 | 含义 | 建议值 |
|---|---|---|
| 宽度 | 图像宽度 | 1024 |
| 高度 | 图像高度 | 1024 |
| 批次大小 | 每次生成张数 | 1 |
🔹 作用: 创建一个“噪声画布”,模型从随机噪声开始生成图像。
🔹 建议:
想生成竖图(瓶子形状)→ 改成
512×1024
1024×512
⚙️ 五、K采样器(核心生成器)
模块名:
K采样器
作用: 控制模型如何“从噪声变清晰”,决定出图速度与细节。
| 参数 | 说明 | 建议 |
|---|---|---|
| 随机种子(Seed) | 控制随机性 | 固定数值→复现同图;randomize→每次不同 |
| 运行后操作 | 一般为 fixed/randomize | 取决于是否想要随机出图 |
| 步数(Steps) | 生成迭代次数 | 20(当前设置不错) |
| CFG | 提示词权重(Prompt影响力) | 8.0(较强,贴合Prompt) |
| 采样器(Sampler) | 采样算法 | |
| 调度器(Scheduler) | 控制每步噪声衰减 | |
| 降噪 | 控制最终细节保留 | 1.0(默认即可) |
🔹 优化技巧:
想更梦幻柔和 → 降低 CFG 到 6.5–7.0想更精确贴Prompt → 提高 CFG 到 9.0想更多细节 → 步数 +5
🎨 六、VAE解码(VAE解码器)
作用:
将潜空间的图像数据(Latent)解码成可见图像。
接收来自采样器的 Latent 输出。
🔹 建议:
如果颜色偏灰 → 尝试换 VAE(如
vae-ft-mse-840000-ema-pruned
✂️ 七、图像裁剪(Image Crop)
作用:
裁剪图像尺寸(如从 1024×1024 剪出 512×1024)。
| 参数 | 含义 | 当前值 |
|---|---|---|
| 宽度 | 裁剪后宽 | 512 |
| 高度 | 裁剪后高 | 1024 |
| X/Y | 起点坐标 | 0 / 0 |
🔹 解释:
你这里是把正方形图切成“竖瓶图”比例。如果想改横图或中景,可以调整
X,Y
宽高
4,细节部分
无
5,使用的工作流
1:1-inspynet抠图工作流说明
https://download.csdn.net/download/qq_22146161/92292149
2:实时图像裁剪
https://download.csdn.net/download/qq_22146161/92292151
6,总结
这也算各一个开始吧,我也在学习摸索中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...