【AI学习-comfyUI学习-LCM lora八步生成 工作流-各个部分学习-第八节】
1,前言2,说明1,整个工作流说明2,各个模块说明3,提升方向建议
3,流程(1)调用模块1)整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片
4,模块介绍参数说明🧩 一、Checkpoint 加载器(简易)🎨 二、LoRA 加载器🧠 三、CLIP 文本编码器(正向提示词)🚫 四、CLIP 文本编码器(负向提示词)🪄 五、空 Latent⚙️ 六、K 采样器(KSampler)🧩 七、VAE 解码器
5,细节部分6,使用的工作流7,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1,整个工作流说明
使用 ComfyUI 的 LCM + LoRA 快速生图工作流
2,各个模块说明
1️⃣ Checkpoint加载器 → 提供模型结构与风格基底
2️⃣ LoRA加载器 → 融合LCM加速推理能力
3️⃣ CLIP编码 → 把Prompt转成特征嵌入
4️⃣ 空Latent → 初始化随机噪声(潜空间)
5️⃣ K采样器 → 根据Prompt与模型生成潜图
6️⃣ VAE解码 → 把潜图还原为真实图像
7️⃣ 预览 & 保存 → 输出最终图像
3,提升方向建议
| 目标 | 建议操作 |
|---|---|
| 增加细腻度 | 步数:8→10,CFG:1.5→2.2 |
| 提升光影与立体感 | 加关键词 |
| 更水墨感 | 加 |
| 二次元更清晰 | 添加 |
| 批量输出 | 加入 BatchPrompt 或 Image Grid 节点进行多样化生成 |
3,流程
(1)调用模块
1)整个模块部分
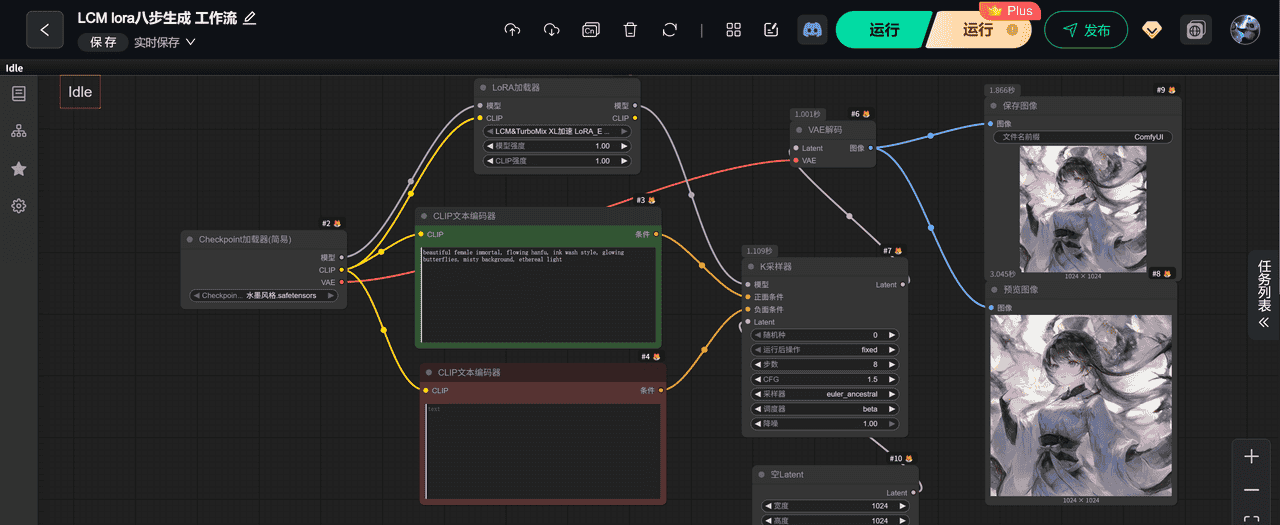
这回整个模块都可以截截图下了
(2)输出 提示词
如下是输入提示词

(masterpiece, best quality, 8k, ultra detailed, cinematic lighting, surreal atmosphere),
a futuristic AI dream architect surrounded by floating holographic screens and glowing data streams,
building a virtual world made of neural networks, algorithms, and colors,
transparent layers of code and image fragments orbiting around the person,
the workspace looks like a dream-like digital cathedral,
soft silver-blue and violet tones, volumetric lighting, ambient haze,
the person is calm, intelligent, focused, creative coder immersed in digital creation,
mix of realism and abstraction, artistic science aesthetic, visionary composition.
(3)模型加载


(4)生成图片
(1)生成图片

4,模块介绍参数说明
🧩 一、Checkpoint 加载器(简易)
作用:加载主模型(即
.safetensors
是整个生成风格的“核心引擎”。
| 参数 | 含义 | 建议值 / 说明 |
|---|---|---|
| 模型路径 | 指向 |
例: |
| CLIP | 文本编码器模型(通常自动匹配) | 与主模型一致即可 |
| VAE | 解码器(图像质量关键) | 建议使用主模型自带或高保真VAE,如 |
📌 小贴士
如果图像偏灰或糊,换 VAE。如果想要更亮更干净的画面,可用
vae-ft-mse
🎨 二、LoRA 加载器
作用:加载轻量化附加模型,用于注入特定风格或加速。
| 参数 | 含义 | 建议值 / 说明 |
|---|---|---|
| LoRA 模型 | 选定 |
例: |
| 模型强度(权重) | 控制 LoRA 影响程度 | 一般 0.8–1.2,越大越接近LoRA风格 |
| 深度(深层融合) | 控制是否影响模型深层特征 | 通常保持 1.0 |
📌 建议
如果你用的是 LCM加速LoRA,强度 = 1.0 最合适。如果换成风格LoRA(如汉服、国潮等),可调 0.6~0.9,避免风格过重。
🧠 三、CLIP 文本编码器(正向提示词)
作用:将 Prompt 文本转成模型可理解的特征向量。
| 参数 | 含义 | 建议 |
|---|---|---|
| Prompt 文本 | 生成描述 | 例: |
| CLIP | 连接主模型的 CLIP 模块 | 保持默认 |
📌 技巧
英文关键词效果最佳(CLIP训练语言)。风格触发词:
ink wash style
Chinese ink painting
soft brush strokes
主语(who)+ 场景(where)+ 风格(style)+ 光感/氛围(lighting)
🚫 四、CLIP 文本编码器(负向提示词)
作用:告诉模型要“避免”的特征。
| 参数 | 含义 | 建议内容 |
|---|---|---|
| Negative Prompt | 负面描述 | 例: |
| CLIP | 一样连接主模型 CLIP | 保持默认 |
📌 要点
这是生成干净画面的关键。建议用通用模板 + 画风专用词(如避免 3D 感、写实化等)。
🪄 五、空 Latent
作用:定义生成画布的基础“噪声空间”。
| 参数 | 含义 | 建议值 |
|---|---|---|
| 宽度 | 图像宽度 | 1024 |
| 高度 | 图像高度 | 1024 |
| 批次大小 | 一次生成几张图 | 1~4(注意显存) |
📌 小技巧
方形图(1024×1024)细节最好。想做封面图,可设 768×1344 或 1152×768。
⚙️ 六、K 采样器(KSampler)
作用:生成的“核心推理器”,控制风格细节与速度。
| 参数 | 含义 | 建议值 / 说明 |
|---|---|---|
| 采样步数 | 每次生成的迭代次数 | 8(LCM适合低步数) |
| CFG | 提示词强度(越大越贴合Prompt) | 1.5–2.5(推荐2.0) |
| 采样器类型 | 生成算法 | |
| 调度器 | 控制步数衰减方式 | |
| 降噪 | 控制初始噪声强度 | 通常 1.0 |
📌 说明
步数越高 → 细节更多,但速度变慢。CFG太高 → 容易过锐或溢色。LCM系列推荐:8步以内,CFG低一点(1.5–2.0)。
🧩 七、VAE 解码器
作用:将潜空间的“隐图像”还原成可视RGB图像。
| 参数 | 含义 | 建议 |
|---|---|---|
| 输入 | 接采样器的 Latent 输出 | 无需修改 |
| 输出 | 连接到图像预览节点 | — |
📌 建议
若画面发灰或颜色异常,换 VAE。若画风柔和、色彩淡,则当前匹配良好。
5,细节部分
无
6,使用的工作流
https://download.csdn.net/download/qq_22146161/92282842
7,总结
这也算各一个开始吧,我也在学习摸索中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...