
一、本体三个核心层级
Palantir 的 Ontology 包含三个核心层级:Semantic(语义层)、Kinetic(动势层)、Dynamic(动态层)。
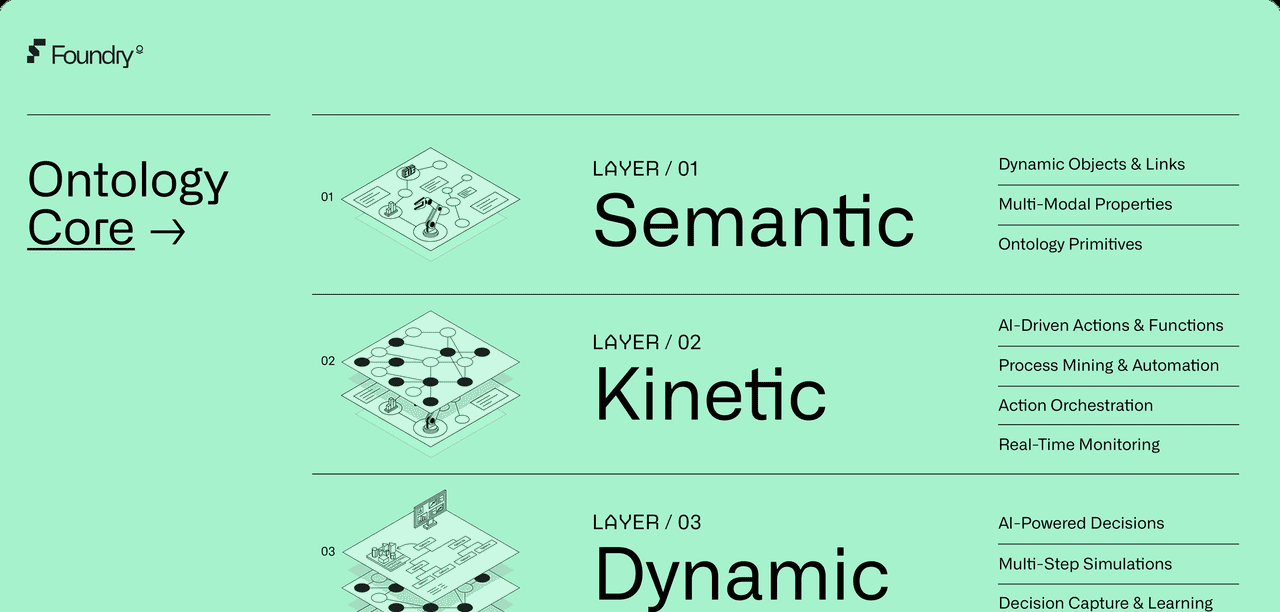
这三层共同构成一个从数据建模到业务执行的完整闭环系统,每一层承担不同职责,区别如下:
1. Semantic Layer(语义层)——“世界是什么”
作用:定义业务世界中的“名词”,即对象、属性、关系。
内容:
实体(如:客户、订单、设备)
属性(如:客户的姓名、订单的金额)
关系(如:客户“拥有”订单)
目标:统一不同系统中的数据语义,建立跨部门的“共同语言”。
比喻:就像字典,告诉你每个词是什么意思。
举例:把 ERP 中的“用户”、CRM 中的“客户”统一建模为
Person
2. Kinetic Layer(动势层)——“世界如何变化”
作用:定义业务世界中的“动词”,即操作、行为、流程。
内容:
操作类型(如:创建订单、审批流程)
函数(如:计算库存、触发警报)
数据同步与写入(将外部系统的数据映射到语义层)
目标:让语义层“活”起来,支持实时数据更新和业务行为执行。
比喻:像引擎,驱动数据流动和状态变化。
举例:当库存低于阈值时,自动触发“创建采购订单”的操作。
3. Dynamic Layer(动态层)——“世界如何决策”
作用:定义规则、逻辑、权限、AI模型,实现智能决策。
内容:
业务规则(如:只有活跃用户才能被分配任务)
权限控制(如:某部门只能查看本部门数据)
AI 模型推理(如:基于语义和动势数据预测最优决策)
多步模拟(如:模拟不同策略下的供应链表现)
目标:实现自动化决策、策略优化和智能推荐。
比喻:像大脑,基于语义和动势信息做出判断。
举例:AI 模型结合“客户行为”(语义)和“订单流程”(动势)预测是否应给予折扣。
总结对比表:
|
层级 |
核心问题 |
功能关键词 |
比喻 |
|
Semantic |
世界是什么? |
对象、属性、关系、统一语义 |
字典 |
|
Kinetic |
世界如何变化? |
操作、流程、数据同步、行为 |
引擎 |
|
Dynamic |
世界如何决策? |
规则、AI、权限、模拟、优化 |
大脑 |
这三层不是孤立的,而是逐层依赖、协同工作:语义层提供结构;动势层注入行为;动态层赋予智能。
这种架构让 Palantir 的 Foundry 平台不仅是数据平台,更是可执行、可优化、可演化的业务操作系统。
二、本体的持久化
Palantir 的 Ontology 是持久化的,但其存储不是“一个数据库”,而是一个由数据库、时序库、对象存储、关系型/KV 存储等组成的分布式多模型架构,按需存储不同类型的数据,并通过一系列服务提供统一的访问和修改能力。
关键服务组件:
|
服务名称 |
功能 |
|
Ontology Metadata Service (OMS) |
存储 Ontology 的元数据定义(如对象类型、属性、关系) |
|
Object Storage V1/V2 |
存储实际的对象实例数据(即“语义层”的数据) |
|
Object Set Service (OSS) |
提供对对象数据的查询、过滤、聚合等读取服务 |
|
Actions Service |
处理用户通过 Action 提交的数据修改请求,并持久化到对象数据库 |
Palantir Ontology 模式本身可以 导出并导入为 JSON 文件,以便进行编辑和版本控制。本体中的实际 数据(对象、属性和链接)最终存储于底层数据集中,默认采用高效、结构化且列式的格式,例如 Parquet。
1.本体模式 (JSON)
格式: 本体的元数据以及对象类型、链接类型、动作类型等结构组件的定义均存储在JSON模式文件中。用法: 该JSON文件可通过本体管理器进行导出和导入,便于离线编辑及在不同环境间传输本体结构。注意: 导出的JSON模式的具体结构属于Palantir内部架构且可能持续演进,因此不建议外部系统严格依赖其格式构建功能。
2.本体数据(Parquet 等)
底层存储: 本体论所表示的操作数据由 Palantir Foundry 中的数据集支持。Palantir 支持开放数据格式,转换后的数据默认通常以 Parquet 等格式提供。效率: Parquet因其高效性、列式存储特性以及适用于Spark等大规模数据处理技术而备受青睐.互操作性:尽管Parquet是处理数据的标准格式,但数据仍可通过其他格式(如CSV)进行访问或导出,以便与外部系统集成.API:通过API与本体数据交互时,数据通常在API响应中以JSON格式呈现.
总之,Palantir使用JSON进行本体模式的定义和配置,并采用Parquet(及其他开放格式)作为其数据集中实际对象数据的高效底层存储格式。
三、存储示例
Ontology 的“模型定义”——对象类型、属性、关系、动作等存储对业务透明,由 Object Storage Service、OSS、OMS 等微服务统一封装。
下面用一个“风力发电机监控”场景,示例Palantir Ontology 的持久化过程。
1.先把“模型”写成 JSON(仅截断展示)
{
"objectTypes": {
"WindTurbine": {
"primaryKey": "turbineId",
"properties": {
"ratedPower": {"type": "double"},
"location": {"type": "geopoint"}
}
},
"Sensor": {
"primaryKey": "sensorId",
"properties": {
"unit": {"type": "string"}
}
}
},
"linkTypes": {
"HAS_SENSOR": {
"from": "WindTurbine",
"to": "Sensor"
}
},
"actionTypes": {
"ReportSensorReading": {
"parameters": {
"timestamp": {"type": "datetime"},
"value": {"type": "double"}
},
"operation": "appendToTimeSeries(sensorId, 'readings', timestamp, value)"
}
}
}这份 JSON 通过 Ontology Manager 上传后,OMS 把它持久化为文件 + 内部元数据表(也是 JSON 化字段)。
系统据此在图库中建好“WindTurbine/Sensor 节点类型”与“HAS_SENSOR 边类型”的骨架,但此时还没有实例数据。
2.业务开始产生“实例”数据
① 风机对象
turbine-001
→ Object Storage Service 把它写成一条 图节点(Vertex)
id='turbine-001', label='WindTurbine', ratedPower=3.5, location=POINT(13.4050 52.5200)
② 传感器对象
sensor-T001
同样落地为图节点,并通过一条 图边
(turbine-001) -[HAS_SENSOR]-> (sensor-T001)
③ 传感器每 10 秒上报转速
ReportSensorReading(sensorId='sensor-T001', timestamp='2025-11-06T14:00:10Z', value=18.3)
→ Actions Service 校验后,把这条时间序列点直接写进 InfluxDB 表
measurement=sensor-T001, field=value, timestamp=2025-11-06T14:00:10Z, value=18.3
④ 现场工程师拍了一张齿轮箱照片,挂到该传感器
文件本身流式上传到 S3,Ontology 里只记一条指针属性
attachment: s3://palantir-bucket/turbine-001/gearbox_20251106.jpg
3.查询时怎么拼回来
要看“turbine-001 有哪些传感器”
→ OSS 向图库发一句
g.V().hasLabel('WindTurbine').has('id','turbine-001').out('HAS_SENSOR')
要看“sensor-T001 过去 1 小时转速曲线”
→ Object Set Service 把 sensorId 透传给 InfluxDB,
SELECT value FROM sensor-T001 WHERE time > now()-1h
要点开那张齿轮箱照片
→ UI 直接把 S3 预签名 URL 拉回浏览器。
四、链路(推测、待确认)
Palantir 把企业所有数据源先接进 Foundry,再经过连接→集成→管理→建模→行动五层流水线,最终生成一张可实时更新、可反向操作业务系统的“数字孪生知识图谱”。
整套架构的核心思想是:
数据只存一份,放在开放列式文件(Parquet/ORC)里;语义、关系、逻辑、权限全部上浮到本体层做虚拟化;查询时优先走内存/SSD 混合索引,未命中则把算子下推到源系统,回来再与本地的增量事务视图合并;推理与行动统一封装成“函数”,供人类或 AI-Agent 调用,形成人在环中的闭环决策。下面按层次展开。
1. 连接层:多模态连接器框架
内置 200+ 连接器(SAP、Oracle、Snowflake、S3、Kafka、PLC、Modbus…),全部用增量 CDC 方式拉取,避免全表扫描。数据入湖后原始格式不变,同步生成只读副本供溯源,满足合规 。
2. 集成层:Pipeline Builder + 增量事务日志
通过可视化的 Pipeline Builder 把原始表清洗、合并、打标签;底层执行引擎是Spark + 自研向量化算子,支持微批与流式一体。每一次 transform 都会产生一条增量事务日志(时间戳 + 行级变更),日志本身存成列存 + 布隆过滤,可秒级回放 。
3. 管理层:Lakehouse + 改进倒排
所有表统一落到Lakehouse 目录,文件格式为 Parquet + Zstd 压缩,块内按字典序排序,块外建Min/Max 索引。对高频查询列(主键、外键、时间、本体 ID)再建一层改进倒排 + 布隆过滤器,常驻 SSD;冷查询回落到对象存储,通过零拷贝 sendfile 返回 。权限下沉到文件粒度的 ABAC,与 Active Directory / SAML 联动,继承到所有衍生数据集 。
4. 建模层:Ontology Manager —— 把表变成“对象+链接”
业务人员用 Ontology Manager 拖拽定义
– 对象类型(如“设备”“订单”)
– 属性(字段映射到列)
– 链接(外键升级成语义关系,如“订单-包含-设备”)背后自动生成三张虚拟表:
Object表(一行一个实例)Link表(一行一条边)Time-series表(可选,用于传感器类数据)
这三张表物理上仍是 Parquet,但通过Catalog暴露成 REST/GraphQL 端点,外部调用无感知 。
同时自动生成 API 网关 + OSDK(TypeScript/Java/Python),把对象和函数封装成 SDK 方法,供前端 Workshop 或外部系统调用 。
5. 逻辑层:函数即服务(Function-as-a-Service)
任何复杂逻辑(指标、预测、优化、审批流)都用 TypeScript/Python 写成“函数”,注册到本体;
– 函数可调用内部数据、外部 API、容器化模型;
– 运行时由 Serverless 池 拉起,自动扩缩,毫秒级冷启动;函数本身也变成可调用的工具,被 AIP Logic 中的 LLM Agent 动态编排,实现“模型驱动决策” 。
6. 行动层:闭合回路的“动词”
在本体里给对象绑定行动(Action),例如“设备→安排维护”“订单→冻结库存”;行动底层就是函数 + 表单 + 审批流,支持多用户角色冲突检测与回滚策略;一旦人工或 AI 确认,平台通过反向连接器把指令写回 ERP/CRM/MES,完成闭环 。
7. 查询与推理执行路径
|
场景 |
执行路径 |
典型延迟 |
|
点查对象属性 |
内存倒排 → 对象 ID → Parquet 块 |
<50 ms |
|
1 跳关系 |
Link 表倒排 → 两个 ID 集合 → Bitmap 与 |
<100 ms |
|
2 跳以上 |
同上多次迭代,或下推到图引擎 |
<500 ms |
|
实时聚合 |
列式向量化执行 → SIMD |
<1 s |
|
规则推理(subClassOf) |
预计算闭包 → 查询时 0 跳 |
<50 ms |
|
重推理(DL 约束) |
TBox 进内存 DL 机 → ABox 走位图过滤 |
<2 s |
所有路径都支持增量事务可见性:查询时把“已提交但未合并”的增量日志也做一次合并,保证读写一致 。
总结:
|
维度 |
Palantir 实现 |
|
主存储 |
Parquet + 倒排 |
|
写入模式 |
增量日志 + 定期合并 |
|
查询引擎 |
Spark + 向量化 + 下推 |
|
关系推理 |
预计算闭包 + Bitmap |
|
水平扩展 |
Lakehouse + 联邦下推 |
|
反向写回 |
原生 Action 框架 |
五、补充说明
本体的关系确实依托数据库实现存储,但并非单一依赖传统数据库的表结构关联,而是结合 Palantir 平台的底层存储架构与 “动态本体论” 设计,形成 “关系模型定义 + 数据库存储承载 + 跨源关联映射” 的多层实现方式,具体说明:
一方面,本体关系的核心定义与元数据通过专用数据库存储。例如在 Palantir Gotham 中,本体所定义的实体间关系(如 “患者 – 诊断”“装备 – 任务分配”),其规则、属性关联逻辑等元数据,会与本体实体定义一同存储在 Postgres 或 Oracle 数据库中(部署于 AWS EC2/RDS、Azure 虚拟机等云基础设施),数据库通过表结构记录关系类型、关联条件、权限映射等信息,同时依托数据库的事务特性保障关系定义的完整性 —— 比如当用户新增 “临床试验患者 – 用药方案” 的关联关系时,该关系的字段约束、溯源标识等会被写入数据库表,与实体元数据形成关联索引。
另一方面,本体关系的实际数据关联通过底层存储与内存计算协同实现。对于本体关系所关联的具体业务数据(如 “患者 A – 诊断 B” 的实际映射记录),Palantir 会结合不同平台的存储特性优化存储:Gotham 借助 Horizon 内存数据库,将高频访问的本体关系数据加载至内存,支持实时查询与关系遍历(如通过 Graph 应用可视化实体关系网络);Foundry 则将本体关系与实际业务数据的关联逻辑,存储于 AWS S3、Azure Blob Storage 等云存储服务中,同时通过 Cassandra 数据库管理关系的实时同步状态 —— 例如当供应链平台的本体新增 “供应商 – 物料” 关系时,该关系对应的实际数据关联记录会与物料数据文件一同存储在云存储中,关系的更新状态则通过 Cassandra 实时同步,确保本体关系与业务数据的一致性。
此外,本体关系的跨源关联存储还依赖数据库与开放接口的协同。文档提到 Palantir 平台支持通过 JDBC/ODBC 驱动、RESTful API 对接外部数据库(如 HDFS、SQL Server),当本体关系涉及外部系统数据时(如医疗平台本体关联医院原有 EHR 系统数据),关系的映射规则会存储在 Palantir 的核心数据库中,实际关联则通过接口实时调用外部数据库数据,无需将外部数据重复存储,既减少冗余,也确保本体关系能动态适配外部数据的更新。
六、参考
https://www.palantir.com/platforms/foundry/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











