
一、环境准备
硬件要求
- 最低配置CPU:支持 AVX2 指令集(加速矩阵运算,提升推理效率)内存:16GB(确保基础模型加载)存储:30GB 可用空间(模型文件 + 依赖库)
- 推荐配置GPU:NVIDIA RTX 3090 或更高(支持 FP16/INT8 加速,显存 ≥24GB)内存:32GB+(支持更大模型或并行任务)存储:64GB+(适配多模型或长期使用)
软件环境
- 操作系统Windows 10/11(64 位)macOS 10.15+(需 Rosetta 2 兼容)Linux(Ubuntu 20.04+/CentOS 7+,需 glibc ≥2.17)
- 依赖项Python 3.8+(推荐使用 Anaconda 管理环境)PyTorch 2.0+(GPU 版需 CUDA 11.8+ 和 cuDNN 8.6+)Docker(可选,用于容器化部署)
二、安装步骤
1. 安装 Ollama
- 官网下载
- Ollama
访问 Ollama 官网,选择对应系统的安装包:Windows/macOS:直接下载安装程序。Linux:使用命令行安装:
curl -fsSL https://ollama.com/install.sh | sh
- 网络问题处理
中国大陆用户若访问 GitHub 缓慢,可通过以下方式加速:使用代理工具(如 Clash、V2Ray)配置全局代理。替换镜像源(如 FastGit)。
2. 下载 DeepSeek 模型
模型选择
- 在 Ollama 模型库中搜索 deepseek-r1,根据硬件选择版本:1.5b(低配 CPU/入门 GPU)7b(中端 GPU,如 RTX 3060)16b(高端 GPU,如 RTX 3090/A100)若需量化版本,添加后缀(如 deepseek-r1:7b-q4 表明 4-bit 量化)。
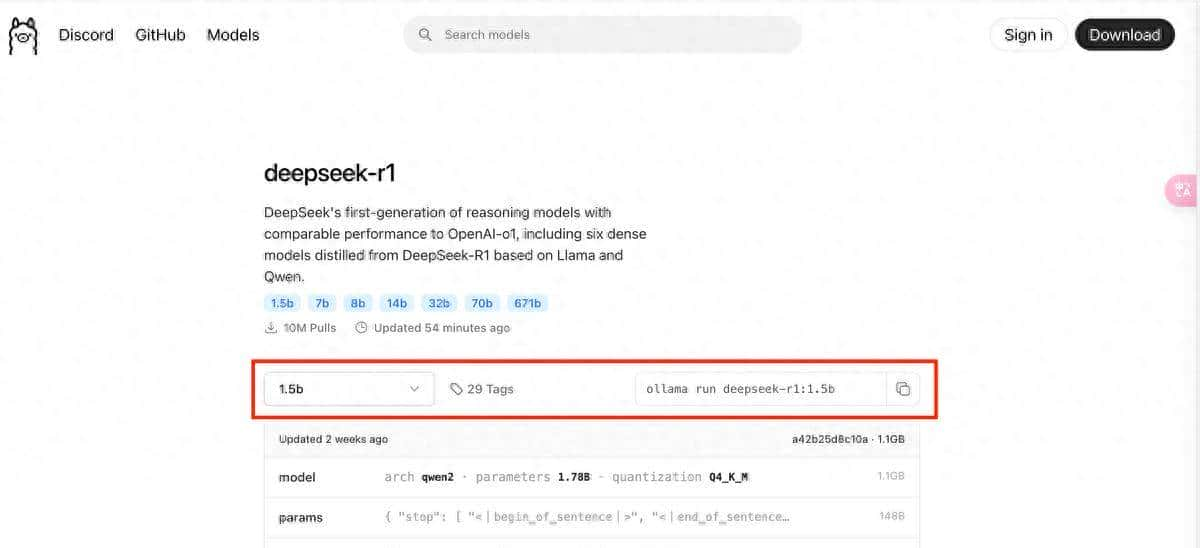
Ollama 模型库中搜索 deepseek-r1 的界面
下载命令
# 示例:下载 7B 基础版ollama run deepseek-r1:7b
- 首次运行会自动下载模型(约 5-30GB,具体取决于版本)。若下载中断,可通过 ollama pull deepseek-r1:7b 续传。

在终端中运行 ollama run deepseek-r1:1.5b 的示例
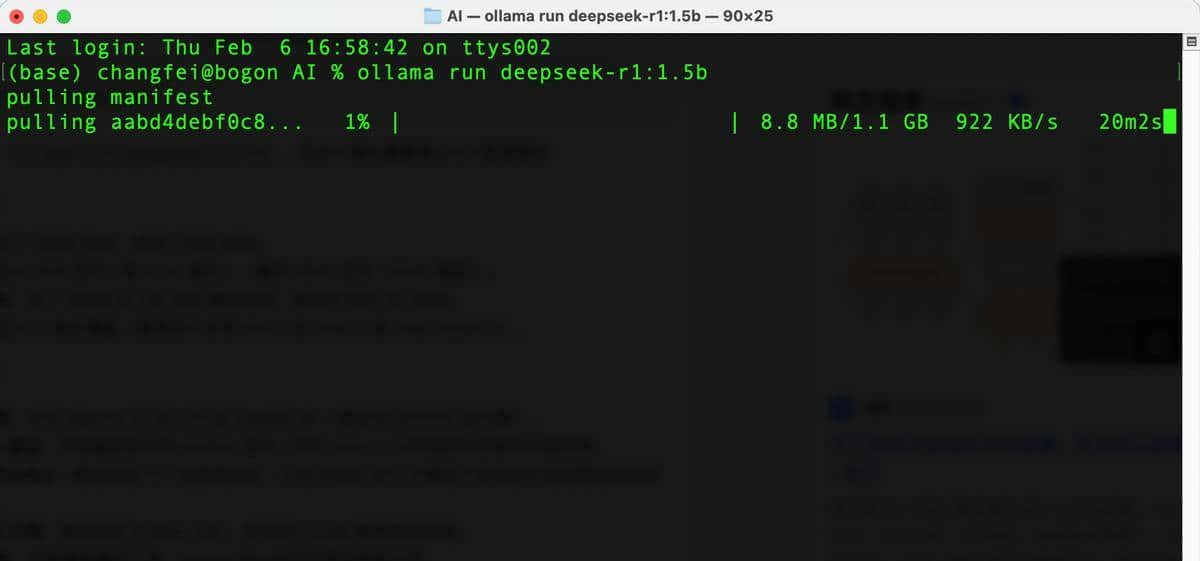
模型文件拉取过程示意图
3. 验证安装
查看已安装模型
ollama list
运行测试对话
ollama run deepseek-r1:7b> 你好,请介绍一下你自己。
预期输出:
我是 DeepSeek-R1,一个专注于自然语言处理的人工智能模型…
三、配置可视化界面
方案一:Cherry Studio(推荐)
安装客户端
从 GitHub Release 下载最新版。
Releases · CherryHQ/cherry-studio · GitHub
配置模型
- API 地址:http://localhost:11434/v1模型名称:deepseek-r1:7b(与下载版本一致)启用 GPU 加速:在设置中勾选 CUDA 选项(需已安装 GPU 驱动)。

Cherry Studio 配置界面示例
Cherry Studio 运行界面

与 DeepSeek R1 模型的对话示例
方案二:Open WebUI(Docker 部署)
- 安装 Docker
- Windows/macOS:下载 Docker Desktop。Linux:
curl -fsSL https://get.docker.com | shsudo usermod -aG docker $USER
- 启动 Open WebUI 容器
- 非 GPU 环境:
docker run -d -p 3000:8080 -v ollama-webui:/app/backend/data –name ollama-webui –restart always ghcr.io/open-webui/open-webui:main
- GPU 环境(需已安装 NVIDIA Container Toolkit):
docker run -d -p 3000:8080 –gpus all -v ollama-webui:/app/backend/data –name ollama-webui –restart always ghcr.io/open-webui/open-webui:cuda
- 访问界面
打开浏览器,输入 http://localhost:3000,登录后选择 deepseek-r1 模型即可使用。
四、高级配置与优化
1. 量化模型
- 适用场景:显存不足时降低资源占用。
- 下载命令:
ollama run deepseek-r1:7b-q4 # 4-bit 量化版
2. 多 GPU 并行
- 启动参数:
CUDA_VISIBLE_DEVICES=0,1 ollama run deepseek-r1:16b # 指定 GPU 0 和 1
3. 自定义 Prompt 模板
在 ~/.ollama/config.json 中添加:
{
“model”: “deepseek-r1:7b”,
“prompt_template”: “你是一个助手,请以专业且简洁的方式回答:{{.Prompt}}”
}
五、故障排除
|
问题现象 |
解决方案 |
|
模型下载失败 |
检查网络连接,使用 proxychains 或更换镜像源。 |
|
GPU 未识别 |
确认已安装 CUDA 驱动,运行 nvidia-smi 验证。 |
|
内存不足 |
换用更小模型或启用量化(如 7b-q8)。 |
|
API 端口冲突 |
修改 Ollama 端口:ollama serve –port 11435 |
六、注意事项
- 模型合规性:确保遵守 DeepSeek 模型的许可协议,禁止商用未授权版本。
- 资源监控:使用 htop(Linux)或 Task Manager(Windows)监控资源占用。
- 数据安全:若通过公网访问,提议配置 HTTPS 和身份验证(如 Open WebUI 的密码保护)。
通过本文档,您应能顺利完成 DeepSeek 模型的本地部署与优化。如有其他问题,可参考 Ollama 官方文档 或提交 Issue 至社区论坛。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录










收藏了,感谢分享