大家好,我是谦!
在当今高并发、大流量的互联网应用中,缓存已成为提升系统性能的关键技术。不过,仅仅使用缓存还不够——如何高效地操作缓存数据往往决定着系统的最终性能表现。本文将深入探讨Redis中四种强劲的批量查询技术,协助你的应用性能提升一个数量级。
为什么批量操作如此重大?
在传统单命令操作中,客户端每次发送一个请求,Redis服务器接收后执行并返回结果。这种模式在高并发场景下存在明显瓶颈:
批量执行命令带来三大核心优势:
- 极大提升执行效率:减少网络往返时间(RTT),显著降低延迟
- 简化客户端逻辑:将多个操作封装为单一操作,代码更简洁易维护
- 提升事务性能:确保一组命令在同一时间段内执行,保证原子性
四大批量查询技术详解
1. 字符串MGET命令:简单直接的批量获取
MGET命令是Redis中最直接的批量查询方式,用于一次性获取多个字符串键的值。
命令格式:
MGET key1 key2 ... keyN
Spring Boot示例:
// 设置值
redisTemplate.opsForValue().set("a", "value1");
redisTemplate.opsForValue().set("b", "value2");
redisTemplate.opsForValue().set("c", "value3");
// 批量获取
List<String> keys = Arrays.asList("a", "b", "c", "d"); // 键d不存在
List<String> values = redisTemplate.opsForValue().multiGet(keys);
// 返回结果: ["value1", "value2", "value3", null]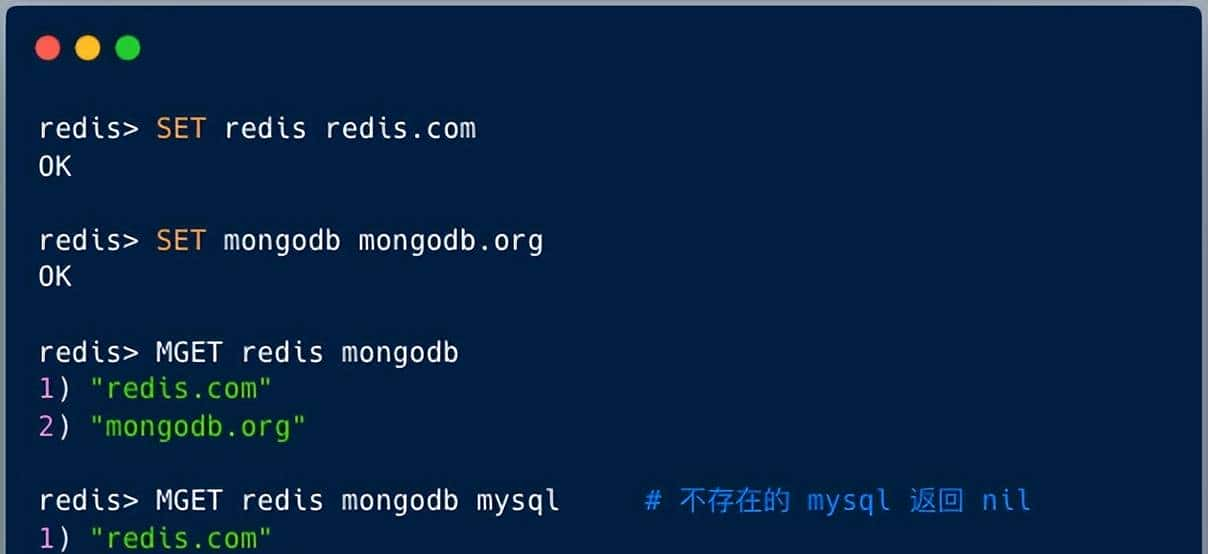
适用场景:需要一次性获取多个简单字符串值的场景,如用户基本信息、配置项等。
2. 哈希表HMGET命令:结构化数据的批量查询
对于哈希数据类型,HMGET命令可以批量获取指定字段的值,超级适合处理对象属性。
命令格式:
HMGET key field1 field2 ... fieldN
Spring Boot示例:
// 设置哈希值
redisTemplate.opsForHash().put("myhashkey", "field1", "value1");
redisTemplate.opsForHash().put("myhashkey", "field2", "value2");
redisTemplate.opsForHash().put("myhashkey", "field3", "value3");
// 批量获取字段值
List<Object> fields = Arrays.asList("field1", "field2", "field3", "field4");
List<Object> values = redisTemplate.opsForHash().multiGet("myhashkey", fields);
// 返回结果: ["value1", "value2", "value3", null]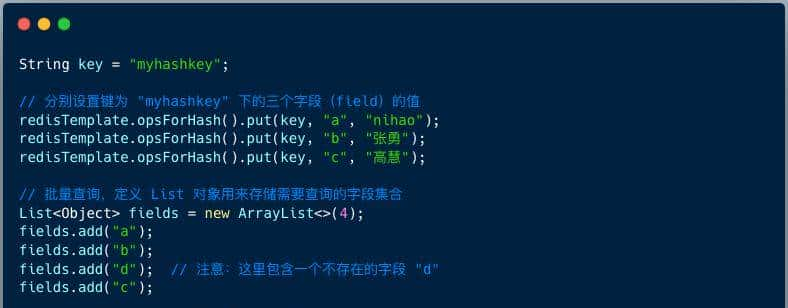
适用场景:处理对象属性、商品信息、用户详情等结构化数据。
3. 管道技术(Pipeline):网络优化的利器
Pipeline是Redis中极为强劲的批量操作技术,它允许客户端一次性发送多个命令到服务器,然后一次性接收所有响应,极大减少网络开销。
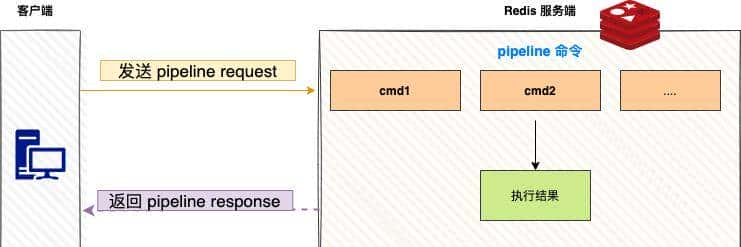
技术原理:
1次pipeline(n条命令) = 1次网络时间 + 执行n条命令时间Spring Boot示例:
List<Object> results = redisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
operations.opsForValue().get("a");
operations.opsForValue().get("b");
operations.opsForValue().get("c");
operations.opsForHash().get("myhashkey", "field1");
operations.opsForHash().get("myhashkey", "field2");
return null;
}
});
// results包含所有命令的执行结果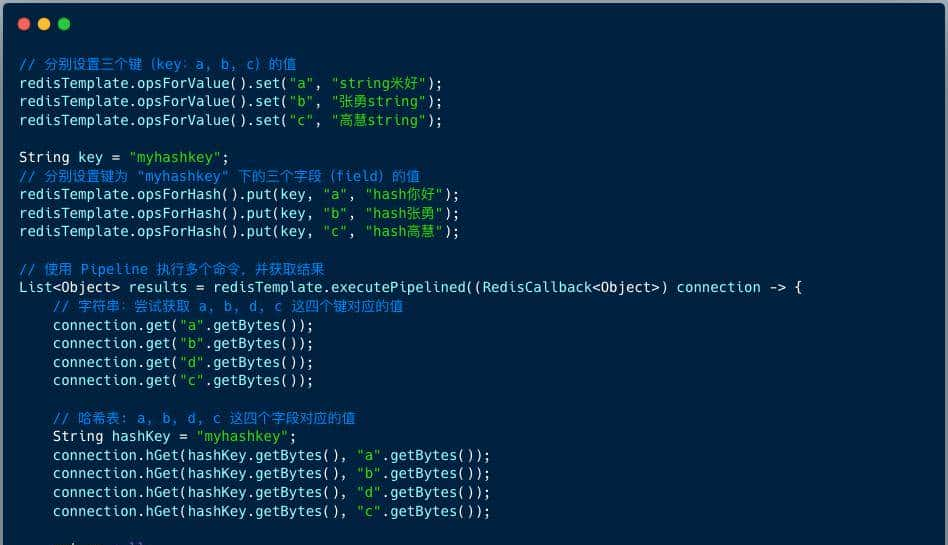
注意事项:
- Redis Cluster中Pipeline可能无法保证原子性
- 不适合有命令依赖关系的场景
- 提议命令数量不要超过500个,避免带宽压力
适用场景:需要执行大量独立命令且对原子性要求不高的场景,如批量数据导入导出、统计计算等。
4. Lua脚本:原子操作的终极解决方案
Lua脚本是Redis中最强劲的批量操作方式,它允许在服务器端原子性地执行多个命令,保证操作的完整性。
执行方式:
- EVAL:直接执行Lua脚本
- EVALSHA:通过脚本SHA1校验和执行已加载的脚本

local value1 = redis.call('GET', KEYS[1])
local value2 = redis.call('GET', KEYS[2])
local value3 = redis.call('HGET', KEYS[3], ARGV[1])
return {value1, value2, value3}
EVALSHA使用步骤:
- 加载脚本获取SHA1校验和:
SCRIPT LOAD "return redis.call('GET', KEYS[1])"返回:
a1104f2250e5dd9fc10c3c681ddb389e7bd4a2cf
- 使用SHA1执行脚本:
EVALSHA a1104f2250e5dd9fc10c3c681ddb389e7bd4a2cf 1 key1

String luaScript = "local result = {} " +
"result[1] = redis.call('GET', KEYS[1]) " +
"result[2] = redis.call('GET', KEYS[2]) " +
"result[3] = redis.call('HGET', KEYS[3], ARGV[1]) " +
"return result";
DefaultRedisScript<List> script = new DefaultRedisScript<>();
script.setScriptText(luaScript);
script.setResultType(List.class);
List<String> keys = Arrays.asList("a", "b", "myhashkey");
List<Object> results = redisTemplate.execute(script, keys, "field1");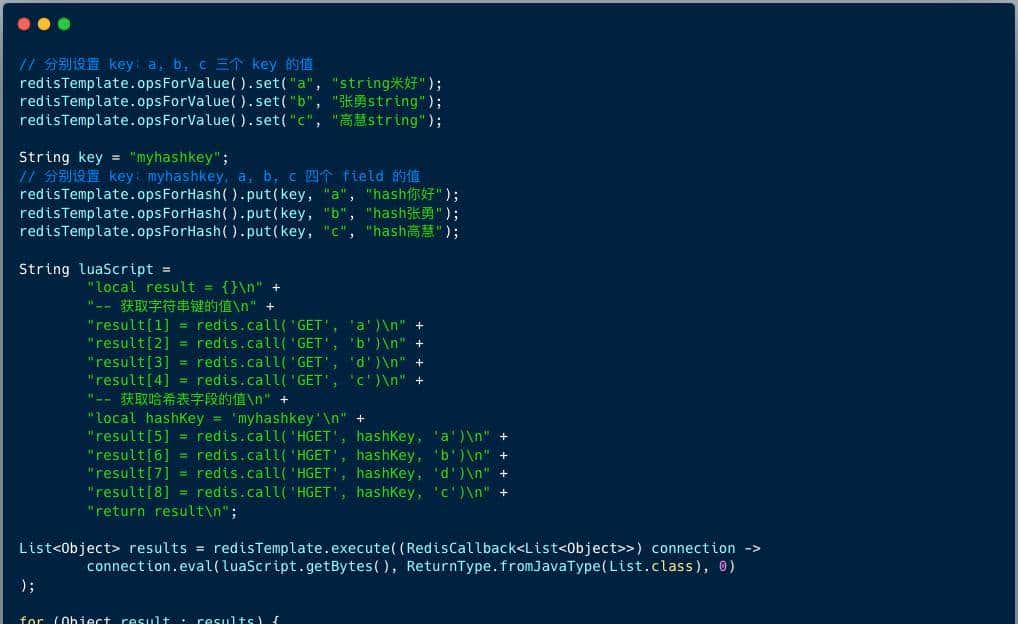
优势:
- 减少网络开销:多个命令一次发送
- 原子操作:所有命令作为一个整体执行
- 脚本复用:脚本存储在Redis中,可被多个客户端复用
缺点:编写和维护相对复杂,需要学习Lua语法。
适用场景:需要原子性执行多个命令的复杂业务逻辑,如库存扣减、订单处理等。
技术选型指南
根据不同的业务场景,选择合适的批量查询技术:
|
技术 |
适用场景 |
优点 |
缺点 |
|
MGET |
批量获取字符串值 |
简单直接 |
仅支持字符串类型 |
|
HMGET |
批量获取哈希字段 |
处理结构化数据 |
仅支持哈希类型 |
|
Pipeline |
大量独立命令 |
减少网络开销 |
不保证原子性 |
|
Lua脚本 |
复杂原子操作 |
保证原子性,减少网络开销 |
编写复杂,需要学习Lua |
实践提议:
- 对于简单批量查询,优先使用MGET/HMGET
- 对于大量独立操作,使用Pipeline提升性能
- 对于需要原子性的复杂操作,选择Lua脚本
- 在Cluster模式下注意数据分片问题
- 控制批量操作的大小,避免单次操作数据量过大
性能优化实战
在实际项目中,合理使用这些技术可以带来显著性能提升。某电商平台在618大促期间,通过将商品详情查询从单命令改为Pipeline批量获取,QPS从原来的5万提升到15万,延迟降低了60%。
另一个社交应用使用Lua脚本实现原子性的用户积分操作,既保证了数据一致性,又将网络开销减少了70%。
结语
Redis批量查询技术是高并发系统优化的关键技能。通过合理运用MGET、HMGET、Pipeline和Lua脚本这四大神器,开发者可以显著提升系统性能,降低延迟,提高用户体验。
需要注意的是,每种技术都有其适用场景和限制,在实际应用中需要根据具体业务需求进行选择和组合使用。技术选型的正确性往往比技术本身的先进性更重大。
希望本文能为你的Redis性能优化之路提供有价值的参考。在这个数据驱动的时代,掌握这些高性能缓存技巧,将使你在高并发场景中游刃有余,打造出真正稳定高效的互联网应用。
本篇分享就到此结束啦!大家下篇见!拜~
点赞关注不迷路!分享了解小技术!走起!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...




