PyTorch简单介绍
PyTorch 是一个基于python语言的开源的机器学习库,主要用于自然语言处理、计算机视觉等领域中的应用开发。它最初由Facebook的人工智能研究团队于2016年推出,并迅速成为学术界和工业界最受欢迎的深度学习框架之一。PyTorch以其灵活性、易用性和动态计算图(Dynamic Computational Graphing)特性而著称。
主要特点
- 动态计算图
- 与TensorFlow等采用静态计算图不同,PyTorch使用“define-by-run”的方式构建神经网络,即网络结构是在运行时定义的。这使得调试更加直观简单,并且超级适合需要灵活改变网络结构的研究工作。
- 易于使用
- PyTorch提供了超级接近Python语法的接口,降低了学习成本,使得开发者可以更快地开始实验和开发。
- 强劲的GPU加速
- PyTorch能够无缝地在CPU和GPU之间切换,利用CUDA技术实现高效的并行计算,极大地提高了训练速度。
- 丰富的工具和库
- 包括torchvision、torchaudio以及torchtext等专门针对图像、音频和文本数据处理的扩展库。
- 社区活跃,拥有大量的预训练模型和第三方库支持。
- 分布式训练
- 支持多GPU训练及分布式训练,便于大规模数据集上的模型训练。
- 与其他库的良好集成
- 可以轻松地与NumPy等科学计算库结合使用,简化了数据处理流程。
核心组件
- Tensors(张量)
- 类似于NumPy的ndarrays,但可以在GPU上运行以加速数值计算。
- Autograd(自动微分)
- 自动求导系统,允许你通过反向传播算法高效地计算梯度,这对于训练神经网络至关重大。
- nn.Module(神经网络模块)
- 构建复杂的神经网络架构的基础类,包含了层(layers)、激活函数(activation functions)等基本组件。
- Optimizer(优化器)
- 提供多种优化算法(如SGD、Adam),用于更新网络权重以最小化损失函数。
示例代码
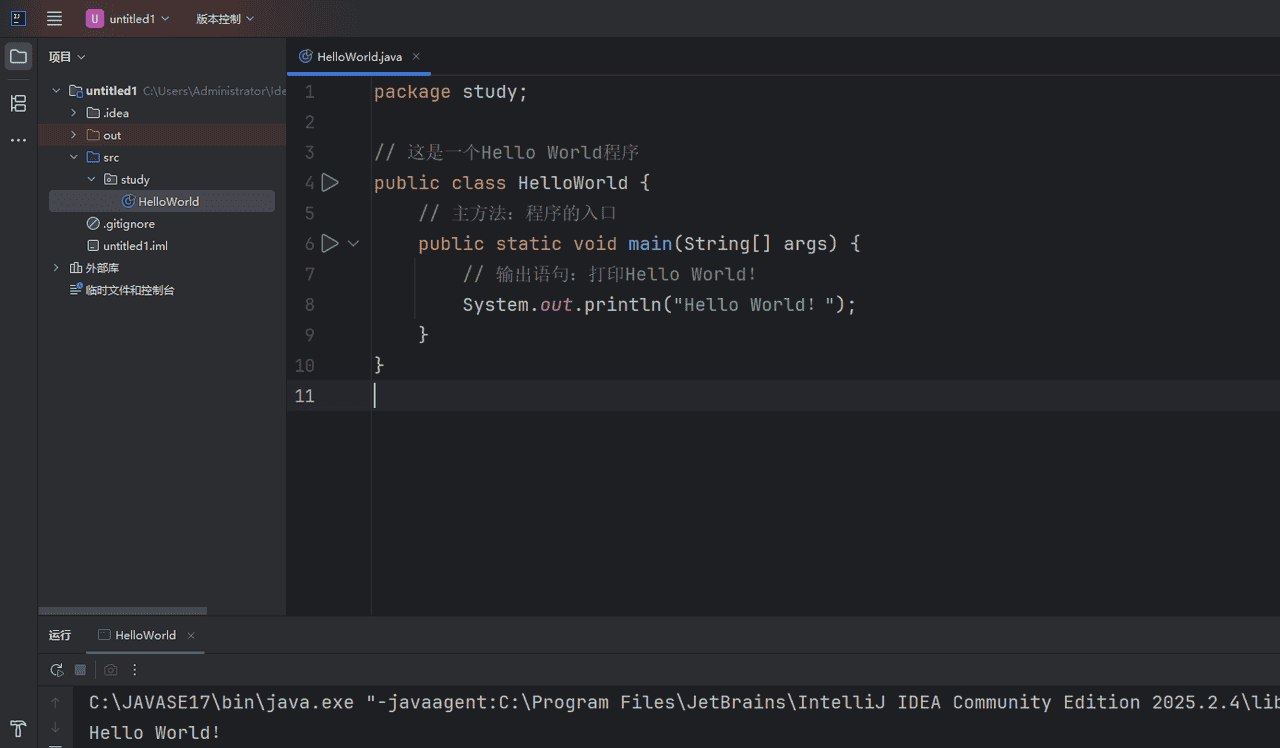
以下是一个简单的例子,展示了如何使用PyTorch创建一个两层全连接神经网络,并对其进行训练:(python)
# 导入必要的 PyTorch 模块
import torch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
# 定义一个两层的神经网络模型
class TwoLayerNet(nn.Module):
def __init__(self, D_in, H, D_out):
"""
初始化函数,定义网络的结构
:param D_in: 输入维度
:param H: 隐藏层维度
:param D_out: 输出维度
"""
super(TwoLayerNet, self).__init__() # 调用父类初始化方法
# 第一层:线性层,输入 D_in,输出 H
self.linear1 = nn.Linear(D_in, H)
# 第二层:线性层,输入 H,输出 D_out
self.linear2 = nn.Linear(H, D_out)
def forward(self, x):
"""
前向传播函数,定义数据在网络中的流动方式
:param x: 输入张量 (batch_size, D_in)
:return: 输出张量 (batch_size, D_out)
"""
# 第一层输出后使用 ReLU 激活函数(这里用 clamp 实现)
h_relu = self.linear1(x).clamp(min=0)
# 第二层输出,不加激活函数(适用于回归任务)
y_pred = self.linear2(h_relu)
return y_pred
# 设置模型参数
D_in = 1000 # 输入特征维度
H = 100 # 隐藏层神经元数量
D_out = 10 # 输出维度(预测目标数量)
batch_size = 64 # 每个批次的样本数量
learning_rate = 1e-4 # 学习率
# 创建随机输入和目标数据(用于演示)
# 输入 x: (batch_size, D_in)
x = torch.randn(batch_size, D_in)
# 目标 y: (batch_size, D_out)
y = torch.randn(batch_size, D_out)
# 实例化模型、损失函数和优化器
# 实例化模型
model = TwoLayerNet(D_in, H, D_out)
# 使用均方误差(MSE)作为损失函数,sum 表明求和而不是取平均
criterion = nn.MSELoss(reduction='sum')
# 使用 Adam 优化器,学习率为 learning_rate
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 开始训练循环
for t in range(500): # 训练 500 次迭代(epoch)
# 前向传播:输入 x,得到预测输出 y_pred
y_pred = model(x)
# 计算损失:预测值 y_pred 和真实值 y 的均方误差
loss = criterion(y_pred, y)
# 每训练 100 次打印一次损失值
if t % 100 == 99:
print(t, loss.item())
# 清空梯度缓存,防止梯度累积
optimizer.zero_grad()
# 反向传播:计算损失函数对模型参数的梯度
loss.backward()
# 使用优化器更新模型参数
optimizer.step()此示例中,我们定义了一个简单的两层前馈神经网络,并使用均方误差作为损失函数,Adam作为优化算法进行了简单的训练过程演示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...