泰坦尼克号获救预测案例可谓是十分经典的一个案例了,信任大家都看过《泰坦尼克号》电影,船上有各种各样的人,最后能获救的肯定跟某些人的特性有关,例如,小孩和妇女先走,富人可能活下去的几率更高等等。学机器学习已经有些日子了,我目前尝试用我所学的知识再结合他人的做法来训练模型对泰坦尼克号上人的获救几率进行预测。
一、观察数据
每当我们拿到数据时,我们需要先观察数据,对数据一些重大性进行分析,结合我们的生活经验和所学知识提取出明显重大的特征,再省略掉一些对我们预测结果不重大的特征。
1.1数据描述
通过pandas提取出数据之后,使用head(5)方法将数据集的前面5条数据打印出来。

从上方数据描述可以观察得出该数据集一共有12列属性:
PassangerId:乘客编号,Survived:是否存活,Pclass:乘客类别,Name:乘客姓名,Sex:乘客性别,Age:乘客年龄,SibSp:乘客有多少个亲人在船上,Parch:乘客在船上老人和小孩的个数,Ticket:船票号,Fare:船票费用,Cabin:船舱位,Embarked:上船码头
初步分析得我们所要预测的目标值为Survived是否存活,对目标值影响较为重大的特征有Pclass,Sex,Age,SibSp,Parch,Fare,Embarked。
1.2填充缺失值
根据数据集得知,Age作为重大的特征,但是其中包含了许多缺失值,我们需要把重大特征中的缺失值用合适的值填充上,才能保证预测数据的准确性。
对于Age特征,我们采用取中位数填充的方法:
titanic[ Age ] = titanic[ Age ].fillna(titanic[ Age ].median())
对于Embarked属性,我们采用取多的那一类填充的方法(并且把特征的属性值从字符型改到数值型更方便我们进行操作):
print(titanic[ Embarked ].unique())
max_value = 0;
count = 0;
for i in titanic[ Embarked ].unique():
tem = titanic.value_counts(titanic[ Embarked ] == i)
print(tem)
if len(tem) > 1 and count < tem[1] :
count = tem[1]
max_value = i
print(max_value)
titanic[ Embarked ] = titanic[ Embarked ].fillna(max_value)
titanic.loc[titanic[ Embarked ] == S , Embarked ] = 0
titanic.loc[titanic[ Embarked ] == C , Embarked ] = 1
titanic.loc[titanic[ Embarked ] == Q , Embarked ] = 2
二、使用多种模型进行预测
我们已经学过了随机森林,线性回归,逻辑回归等算法。在此我们分别使用三种算法尝试预测船上人员是否获救。
2.1线性回归

2.2逻辑回归

2.3随机森林
一般随机森林的预测效果是最好的,我们重点观察随机森林的预测效果
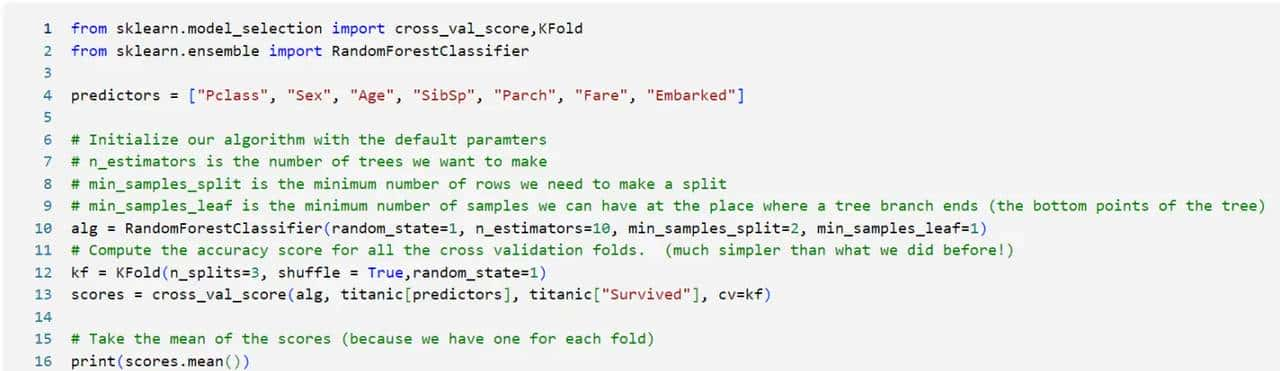
随机森林的预测准确度是跟参数有关的,我们一般会花大量的时间在调参上

我们可以看到,调完参数后我们将准确度提高到了0.8215,由此可见,随机森林调参这一步骤是十分重大的
三、评估特征重大性及创建特征
此时我们对于这个预测的准确度还是不够满意,我们该怎么办呢?我们可以再分析没有用上的特征,通过对特征重大性的评估来添加或依据它们创建出新的重大特征。
3.1创建新特征
一般,有些特征类似时我们可以将它们合并成一个新的特征,例如这里的Parch和SibSp特征,我们可以将它们合并成一个FamilySize特征,用家庭大小来总结在船上家庭成员个数和老小的个数。
我们玄学地猜想一下,名字对于是否获救有没有重大性呢?按照常识来说应该是没有影响的,但是我们得科学分析这些数据才能下定结论它是否对于预测结果有影响。
所以我们可以设想一下,名字的长度对于预测结果有影响,我们创建一个名字长度特征NameLength:
titanic[“NameLength”] = titanic[“Name”].apply(lambda x: len(x))
我们觉得与其说名字对于预测结果有影响,不如说是姓氏对预测结果有影响,毕竟同名的人很少。

3.2评估特征重大性
分析特征重大性:
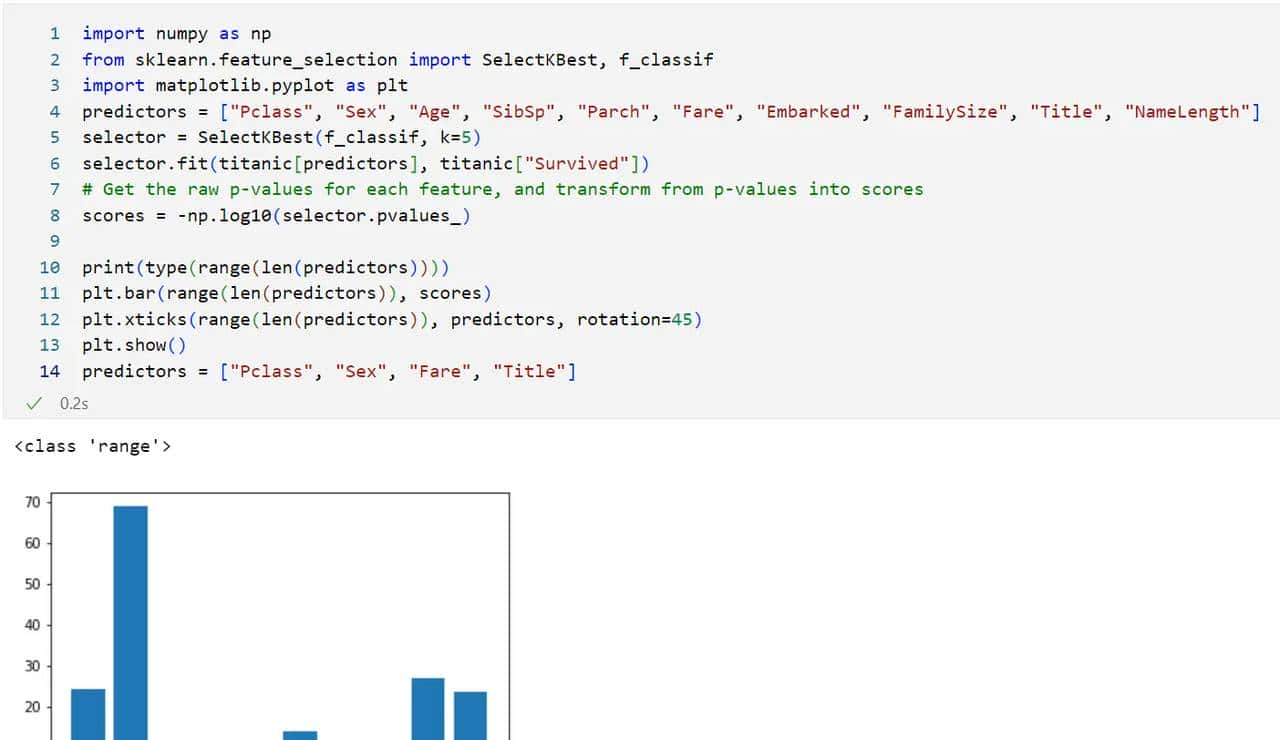
通过画出直方图,我们可以很清晰地看出各特征对于预测结果地重大性,出乎意料的是,名字长度和姓氏居然对预测结果十分重大!!!所以从数据科学的角度来看,我们不能完全靠我们的常识,更要通过分析数据才能下定结论。
四、集成算法
在上面,我们都每次预测都只用了单个分类器,我们尝试下使用多个分类器集成预测会不会有更好的结果呢?
这里我们集成梯度增强算法+逻辑回归算法来预测。
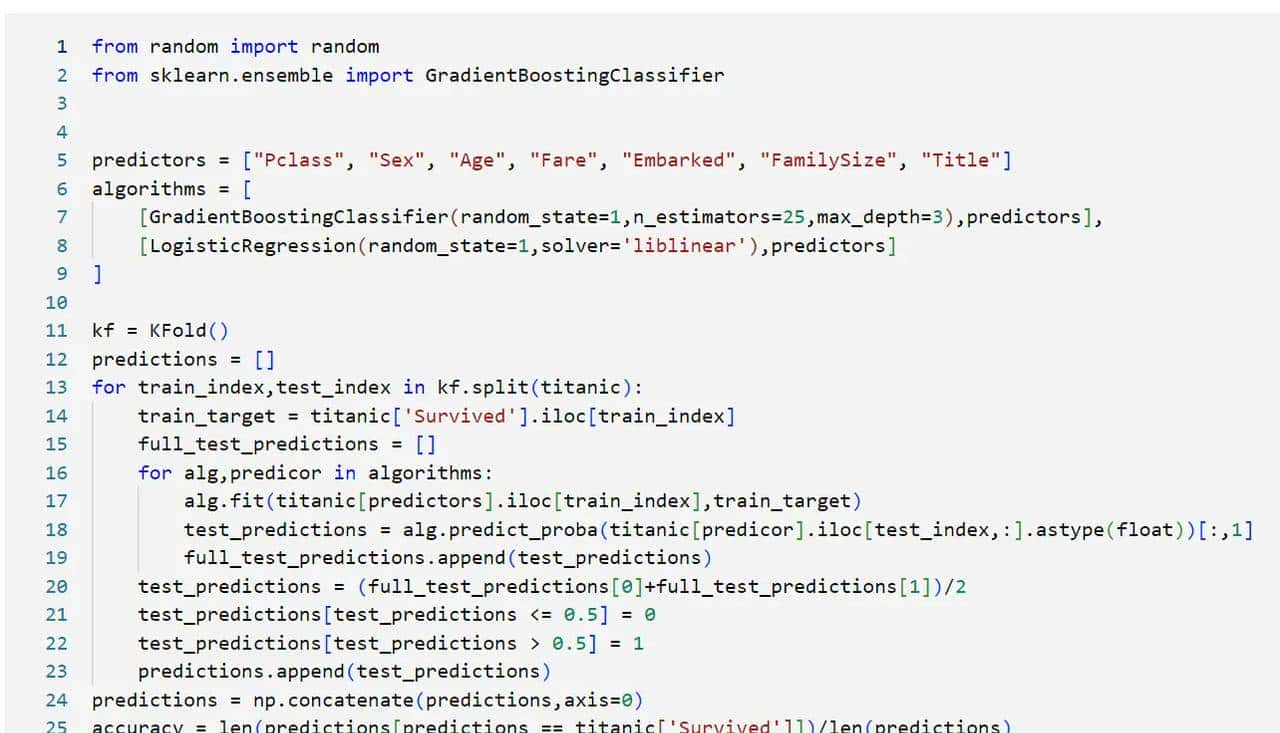
通过调整各分类器预测结果所占比例,我们可以得到:

“`代码测试“`
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











