
Mysql模拟插入百万级数据与简单的查找优化(个人学习记录)
在我们平时Web的个人学习过程中,常常接触到的都是个位数级别的小数据,但是在实际业务中我们需要接触的处理的数据会比我们个人学习过程中大好几个数量级,今天就来讲一下如何向Mysql插入100万数据供日后学习,以及一个简单的查找优化
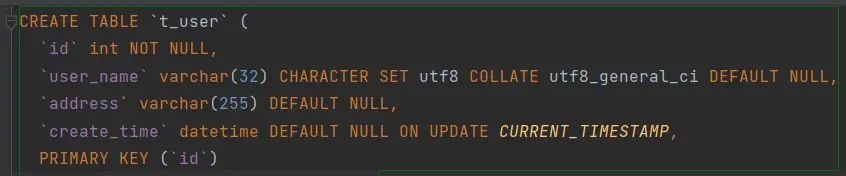
第一,我们先创建一个表t_user
接着我们写一个存储过程,向表t_user中插入1000000条数据

在这个代码片段中,我们先是创建了存储过程user_insert,然后使用了一个简单的while循环执行100万次向表中输出数据,然后进行了调用

数据插入完毕后,我们先执行一下语句来看看效果,这里为了凸显出效率的具体变化我们就不使用desc来查看了
SELECT * FROM t_user WHERE user_name= test1000000

可以看到在实际业务中即使100万这么微小的数据量都要花费214ms的时间,如果将数据量往上继续增长,查找时间将会变得超级长
那么我们该如何减少查找时间呢
我们先来看一下MySQL语句是怎么执行的
MySQL是典型的 C/S架构(客户端/服务器架构),客户端进程向服务端进程发送一段文本(MySQL指令),服务器进程进行语句处理,然后执行并返回结果。

执行一条SQL语句第一会在服务器与客户端之间建立连接,然后对SQL语句进行解析(在MySQL8.0中删除了命中查询缓存返回数据的操作),解析会进行如下操作
词法分析。
把一条完整的SQL语句打碎成一个个单词,列如,MySQL会把SELECT识别成查询语句;把字符串t_user识别成“表名 t_user”;把字符串user_name识别成“列 user_name”。语法分析。语法分析器会根据语法规则,生成解析树,从而判断SQL 语句是否满足语法,列如单引号是否闭合,关键词拼写是否正确等。构建语法树。

执行SQL语句
预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表的所有列。
优化阶段:基于查询成本的思考, 查询优化器会选择成本最小的执行计划;
执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端。
最后由存储引擎(InnoDB,MyISAM,Memory等)处理数据
而关于存储引擎我们又有
(1) Memory
Memory存储引擎,以前也称堆引擎,它将所有数据存储在RAM内存中,以便快速访问。特点:
把数据放在内存里面,读写的速度很快。但是,数据库重启或者崩溃,数据会全部消失;
只适合做临时表。
(2) MylSAM
应用范围比较小,表级锁限制了读/写性能,因此在Web和数据仓库配置中,一般用于只读或以读为主的工作。特点:
支持表级别的锁(插入和更新会锁表),不支持事务;
拥有较高的插入(insert)和查询(select)速度;
存储了表的行数(count速度更快)。
(3) InnoDB
MySQL 5.7及更新版中的默认存储引擎。InnoDB是事务安全(兼容ACID),它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁和Oracle风格的一致非锁读提高了多用户并发性。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性,InnoDB还支持外键引用完整性约束。特点:
支持事务,支持外键,因此数据的完整性、一致性更高;
支持行级别的锁和表级别的锁;
支持读写并发,写不阻塞读(MVCC);
特殊的索引存放方式,可以减少IO,提升査询效率。
总的来说就是
(1)对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
(2)如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
(3)如果需要一个用于查询的临时表,可以选择Memory。
在数据库中我们可以使用如下语句来查看每个表所使用的存储引擎
select table_schema,table_name,engine from information_schema.tables where table_schema not in ( sys , mysql , information_schema , performance_schema );

存储引擎查到了,接下来我们对存储引擎进行修改,以下是修改的语法
alter table 表名 engine 存储引擎名
接下来我们简单的对刚刚的查找进行优化
第一,假设t_user是查询为主的表,对查询性能比较高,那么我们就可以根据需求将存储引擎修改为MyISAM

然后我们再度执行之前的语句

发现只用了105ms,相比214ms显著提升了效率
我们发现WHERE条件中我们只需要对user_name进行检查,那么我们就创建索引

然后执行语句

通过索引我们又将105ms缩减到了15ms,执行效率进一步提升,在实际业务中我们面对更加复杂的语句还可以使用复合索引来进行优化
通过这简单的几步我们将一个需要花费214ms来执行的功能缩减到了15ms
参考资料:
MySQL海量数据优化(理论+实战) 吊打面试官:https://blog.csdn.net/Trouvailless/article/details/124890861
专项攻克——MySQL语句与底层原理解析:https://blog.csdn.net/qq_18683559/article/details/93221224
MySQL存储引擎查看和修改的方法:https://blog.csdn.net/LuRenJiang/article/details/106250092
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











