
在当今高并发、大数据量背景下,数据库性能优化成为衡量后端工程师技术深度的重大标准。本文将系统介绍SQL性能调优的完整方法论,通过真实案例展示如何精准定位并解决性能瓶颈。
一、数据库性能优化体系全景
SQL优化并非孤立存在,而是数据库性能优化金字塔的顶端部分。理解这个层级结构有助于建立全局优化视野:
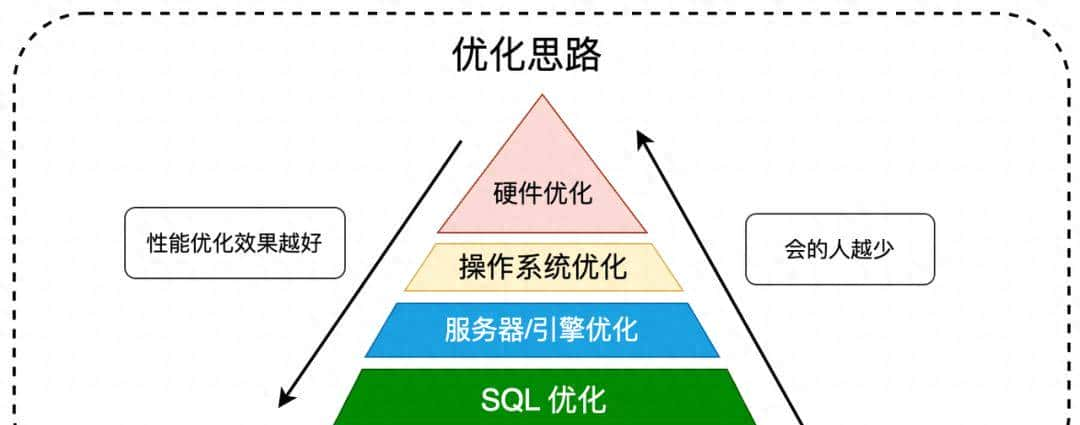
优化层级分析
- 硬件层优化:最基础的优化手段,包括CPU升级、内存扩容、SSD硬盘替换等
- 系统层优化:操作系统内核参数调优,如网络缓冲区、文件句柄限制等
- 数据库软件层优化:DBMS本身配置调优,如MySQL的InnoDB参数调整
- 应用层SQL优化:开发者最可控、ROI最高的优化层面
SQL优化的核心目标
- 最小化磁盘I/O:避免全表扫描,促进索引命中,理想状态是实现覆盖索引
- 最小化CPU与内存开销:优化排序、分组、去重等计算密集型操作
二、性能诊断的核心工具:EXPLAIN深度解析
EXPLAIN是SQL性能分析的”听诊器”,任何不掌握此工具的后端工程师其数据库技能都是不完整的。
关键执行计划字段解读
-- 示例:分析排序分页查询的执行计划
EXPLAIN
SELECT * FROM tx_user.user
ORDER BY uid DESC
LIMIT 5;执行计划中需要重点关注以下字段:
|
字段 |
说明 |
优化意义 |
|
type |
访问类型,性能顺序:system > const > eq_ref > ref > range > index > ALL |
ALL表明全表扫描,必须优化 |
|
key |
实际使用的索引 |
NULL表明未使用索引 |
|
rows |
预估扫描行数 |
数值越小越好 |
|
filtered |
WHERE条件过滤百分比 |
值越高说明索引选择性越好 |
优化迭代流程
SQL优化是一个持续的”分析-假设-验证”过程:
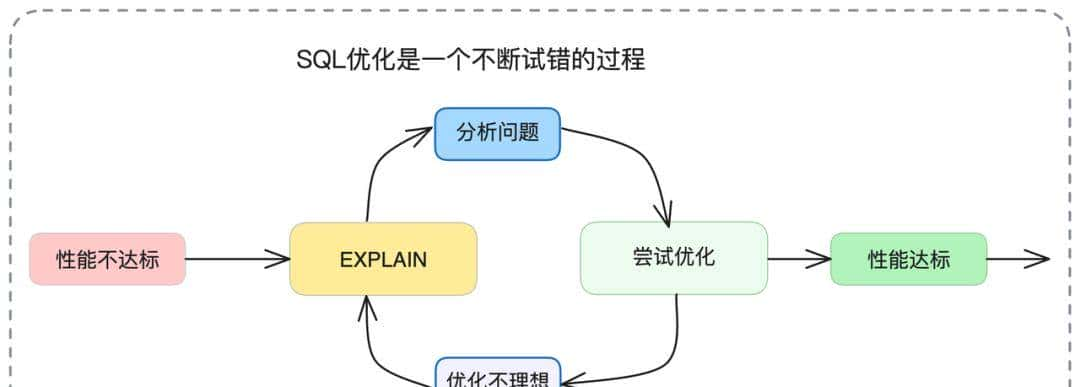
三、索引设计艺术与最佳实践
索引设计原则
- 高频查询条件优先:为WHERE子句中的高频谓词列建立索引
- 排序操作优化:为ORDER BY排序列建立索引,利用B+树有序性
- 关联查询必备:JOIN操作的关联字段必须建立索引
- 高区分度优先:选择基数(唯一值数量)高的列作为索引
大表DDL操作风险管理
对海量表执行ALTER TABLE等操作存在锁表风险,需要采用安全方案:
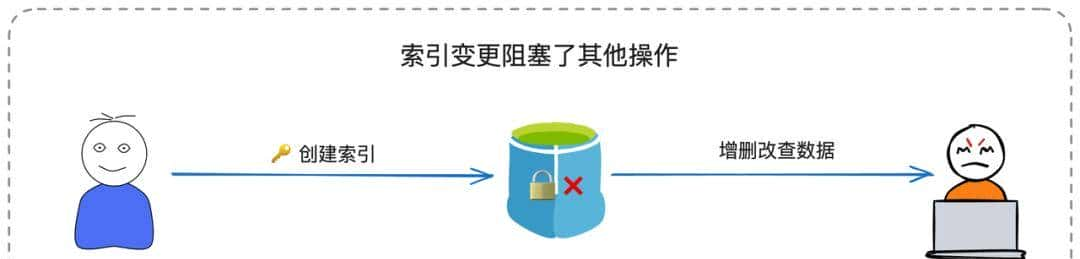
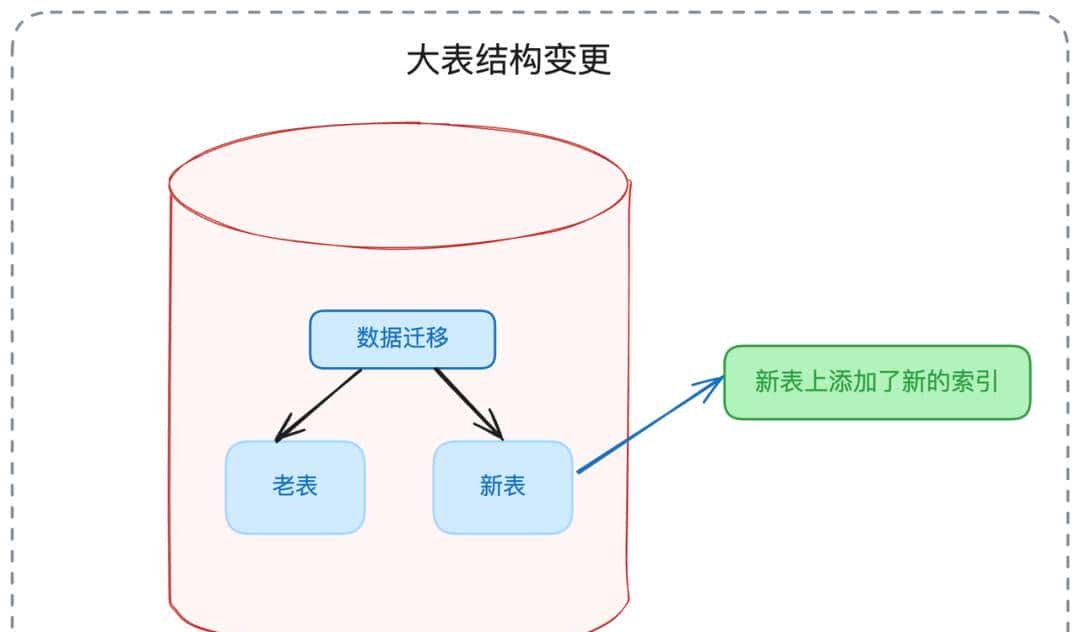
推荐方案:影子表模式(在线DDL)
- 创建与原表结构一样的影子表,预先完成DDL变更
- 全量数据拷贝至影子表
- 增量数据实时同步
- 原子性表名切换
四、实战案例深度剖析
案例1:覆盖索引消除回表
问题场景
SELECT * FROM orders WHERE user_id = 123 AND status = 'active';业务实际只需要order_id, amount, create_time三列,但使用SELECT *导致回表查询。
优化方案
-- 创建覆盖索引
CREATE INDEX idx_user_status ON orders(user_id, status, order_id, amount, create_time);
-- 优化查询语句
SELECT order_id, amount, create_time
FROM orders
WHERE user_id = 123 AND status = 'active';效果:查询耗时从100ms降至1ms以内,避免回表操作。
案例2:索引有序性优化排序
问题场景
SELECT * FROM user_actions
WHERE user_id = 456
ORDER BY action_time DESC
LIMIT 10;随着用户数据量增长,filesort成为性能瓶颈。
优化方案
-- 创建联合索引
CREATE INDEX idx_user_action_time ON user_actions(user_id, action_time DESC);原理:B+树索引在user_id一样时,天然按action_time有序排列,直接避免排序操作。
案例3:COUNT(*)优化策略
问题背景
InnoDB的SELECT COUNT(*)需要全表扫描,性能随数据量线性下降。
解决方案对比
|
方案 |
适用场景 |
优缺点 |
|
近似值 |
可接受估算值 |
使用EXPLAIN的rows字段,快速但不够准确 |
|
外部计数器 |
需要准确值 |
使用Redis维护计数,需解决数据一致性问题 |
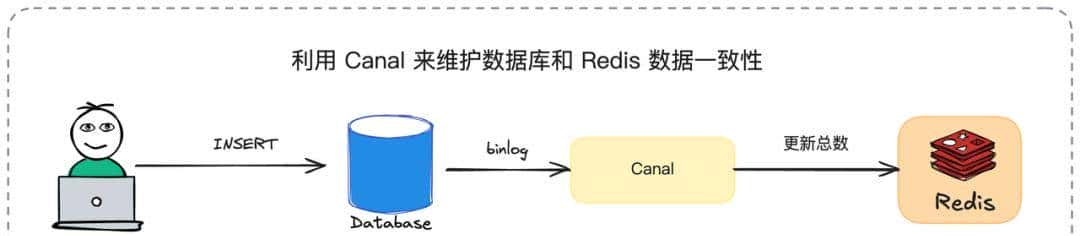
推荐架构:业务代码操作数据库 + Binlog订阅异步更新计数器,保证最终一致性。
案例4:WHERE与HAVING的正确使用
问题SQL
SELECT user_id, COUNT(*) as order_count
FROM orders
GROUP BY user_id
HAVING create_time > '2024-01-01'; -- 错误:HAVING中使用普通条件优化后SQL
SELECT user_id, COUNT(*) as order_count
FROM orders
WHERE create_time > '2024-01-01' -- 正确:WHERE中过滤
GROUP BY user_id;
性能提升:40%查询时间优化,因在分组前大幅减少数据处理量。
案例5:深度分页性能优化
问题场景
SELECT * FROM products
ORDER BY id DESC
LIMIT 10000, 20; -- 深度分页性能差优化方案:游标分页
SELECT * FROM products
WHERE id < last_seen_id -- 基于上一页最后ID
ORDER BY id DESC
LIMIT 20;原理:避免OFFSET的大规模扫描,保持稳定查询性能。
五、面试展现技巧
回答策略
当被问及”如何做性能优化”时,采用结构化回答:
- 监控发现:通过慢查询日志定位问题SQL
- 诊断分析:使用EXPLAIN分析执行计划
- 方案实施:索引优化/SQL重写/架构调整
- 效果验证:性能测试和数据对比
案例准备要点
- 选择有显著优化效果的真实案例
- 准备优化前后的具体数据对比
- 深入理解每个优化决策的底层原理
- 预判可能的深入技术追问
六、总结
SQL性能调优是一项需要系统方法论和实践经验结合的技能。通过掌握EXPLAIN工具、理解索引原理、熟悉常见优化模式,能够有效解决大多数数据库性能问题。在技术面试中,通过精心准备的实战案例和结构化表达,可以充分展现技术深度和解决问题的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录












收藏了,感谢分享