从零开始理解Embedding,深入探索向量检索技术
搜索结果变得更“懂人话”了。用户问一句“如何重置密码?”,系统不再只看有没有“重置”“密码”这两个词,而是能把含义接近的文档排到前面,命中率明显上来了。这种改善不是一夜之间的奇迹,而是把文字变成数字向量后,靠向量之间的类似度去比对的结果。
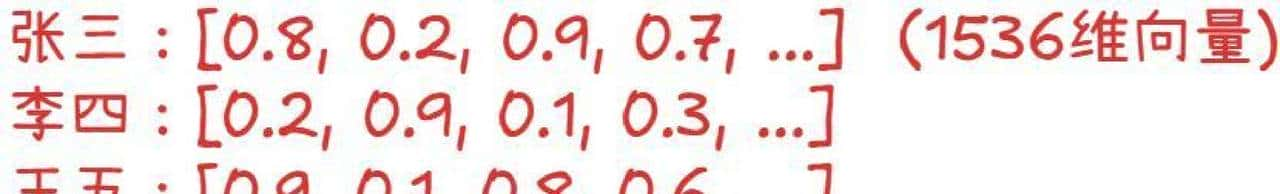
举个现场例子:一个用户用比较口语化的话问“我忘了登录密码,怎么改回来?”,传统关键词检索可能找不到含有“忘了”“改回来”这种说法的文档;但把问题和知识库里的每条文档都做成向量后,语义相近的文档会在向量空间里靠得很近,检索出来的相关度就高。用户体验上能直接看到能解决问题的步骤,而不用去拆词或试着换不同关键词。看起来简单,背后流程却涉及好几步:把文本编码成向量、计算类似度、在海量向量里做近邻搜索、再把结果排序返回给用户。
许多人会问,计算机怎么判断两段话像不像呢?最笨的方法是字符串匹配,就是看字符或词有没有重合,适合准确匹配但对同义、语序变化、长短差别很敏感。这种方式在面对日常语言时会漏许多。正确的办法是先把语言转成数值表明——向量,然后用向量之间的距离或角度来判断类似度。换句话说,不是比文字表面,而是比意义。

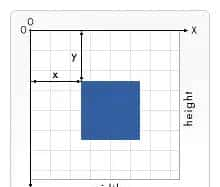
把文字变成向量的过程,想象成给每个人做一张档案卡。传统档案上写姓名、地址这些字段,向量档案是一串数字,每一位数字代表某种语义特征。两个人如果兴趣、职业类似,他们的档案数字排列会很接近。向量的几个核心特性可以这么理解:第一,语义信息被压缩到了固定长度的一串数里;第二,类似的文本对应相近的点;第三,这种表明可以直接用于计算和排序。听着像概念化的东西,实际运用起来相当直接。
为什么会出现 768 维、1536 维这种数字?维度是模型表明能力和计算成本之间的权衡。维度低了,表达能力不足,容易把不同意思的句子压得太近;维度高了,能捕捉更多细微差别,但存储和计算开销增加。把每一维想象成捕捉一种语义信号:列如一个维度可能对应“关于软件操作”的程度,另一个可能对应“是否含有疑问语气”,多个维度组合起来就能区分出细微的语义差异。具体选多少维,一般看数据量、任务复杂度和算力预算,常见值就是像 768、1536 这种能在效果和资源间找到平衡的点。
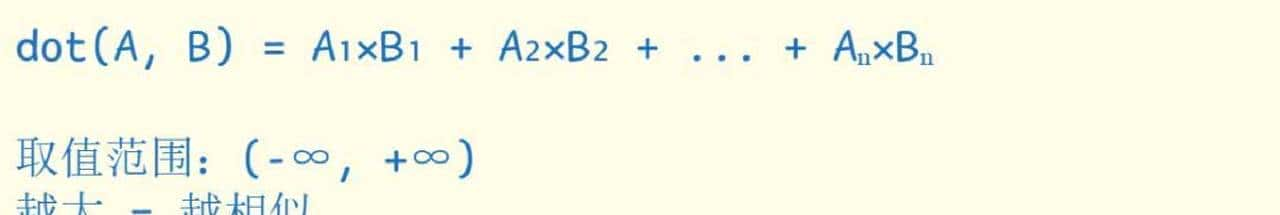
说到类似度,常用的几种度量方式各有场景。余弦类似度适合大多数文本类似度评估,由于它关注向量方向,公式是 cos(a,b) = (a·b) / (|a||b|)。用中文解释就是把两个向量的点积除以各自长度的乘积,得到一个-1到1之间的数,越接近1代表越类似。欧氏距离更适合衡量真实空间距离或用于聚类分析,关注的是绝对差异;点积则常用于计算资源受限时的快速筛选,计算量较小,能做初步过滤。工程上往往是先用点积或一些粗排方法快速筛掉大部分文档,再用余弦做精排。
向量是怎么训练出来的?简单说,就是让模型学会把语义相近的句子放到相近的位置。常见的方法有对比学习,把一对语义接近的文本当成正例,非相近的当作负例,训练模型拉近正例向量、推远负例向量。有时会结合有标签的数据做监督微调,让向量更符合检索或分类任务的需要。训练过程还会用到大规模的语料库,以覆盖更多语言现象和用法。

在工程实操层面,要面对的一个大问题是规模。你手里有 100 万条文档的向量,暴力搜索意味着对每个查询都把它跟 100 万个向量逐个比对,代价不低。解决办法是用向量数据库和近似最近邻(ANN)算法,像 HNSW、PQ 这些技术可以在精度和速度间做折中。向量数据库负责索引、存储和检索,还支持批量更新和持久化,能把检索延迟从几秒降到几十毫秒。工程团队一般把检索分成两层:先粗排用快速索引拿到候选,再精排用更准确的类似度或上下文模型排序,这样既快又稳。
把这种技术应用到实际产品里,能产生好几类效果:检索更贴近用户意图,推荐系统能基于内容和语义做匹配,文档排序更合用。举个细节:当知识库里有多篇回答同一问题但表述不同的文档时,向量检索能把最贴近用户口吻和语义意图的那篇放前面,这比只靠关键词权重大自然得多。工程上还常把向量检索和传统关键词检索结合,互补地提升召回和准确率。

从早先的关键词检索到目前的向量语义检索,这条路看起来像是从表面搬到骨子里。实现过程里会碰到模型大小、维度选择、类似度度量、索引结构这些技术点,每一个都影响最终的体验。现实里,工程师会在效果和成本之间来回调试,找到最适合自己场景的配置。我记得有人做对比实验,把同一批查询在关键词检索和向量检索上做对比,向量方案在用户真实问题上的命中率和用户满意度都能看到可测的提升。场景不同,落地细节也不一样,但思路是一致的:把语言的意义变成数字,让机器能用“距离”去理解类似性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...









