基于视觉 Transformer、Hugging Face 和 TensorFlow 的语义分割
本教程主要的目的是:微调 SegFormer 模型变体,用于对地理空间数据进行语义分割。
本教程演示了如何利用视觉 Transformer 在地理空间数据上微调语义分割架构,以执行土地覆盖语义分割任务。具体来说,我们将通过从 Hugging Face 获取发布的版本来利用 SegFormer 模型变体。
SegFormer 基于一种称为“混合 Transformer”的层次化架构作为其编码器,并使用轻量级 MLP 和上采样器作为其解码器。这种设计在语义分割方面(截至 2021 年在 ADE20K 基准数据集上的性能与模型效率对比)取得了最先进的性能和效率。尽管更新的架构在此基准数据集上表现优于 SegFormer,但 SegFormer 与 Hugging Face Transformer 的易用性使其成为本教程实施的良好候选者。
有关 SegFormer 架构的更多细节,请参阅其初始出版物:SegFormer:基于 Transformer 的简单高效语义分割设计。

我们将从 Hugging Face Transformer 获取预训练的 SegFormer 模型,并使用来自 Radiant Earth MLHub 的公开地理空间数据和标签进行微调。
注意:本教程改编自以下代码:
TensorFlow 团队提供的分割官方教程
Hugging Face 任务指南中的分割部分
# 安装必要的Python库
# 安装transformers库,版本4.31.0,用于自然语言处理任务(如BERT、GPT等模型)
# 注意:!!是Jupyter Notebook中执行系统命令的特殊语法,等效于在终端运行
!!pip install transformers==4.31.0
# 安装rasterio库,版本1.3.8,用于处理栅格/地理空间数据(如GeoTIFF文件)
# -q 参数表示安静模式,减少安装过程中的输出信息
!pip install -q rasterio==1.3.8
# 安装geopandas库,版本0.13.2,用于处理地理空间矢量数据(扩展pandas功能)
!pip install -q geopandas==0.13.2
# 安装radiant_mlhub库,用于访问地球观测和遥感数据集
# 注释中提供了官方文档链接:https://mlhub.earth/
!pip install -q radiant_mlhub
# 安装tensorflow_io库,版本0.32.0,为TensorFlow提供额外的I/O操作支持(特别是地理空间数据格式)
!pip install tensorflow_io==0.32.0
# 导入必要的Python库和模块
# 标准库导入:操作系统接口、文件路径匹配、压缩文件处理、JSON数据处理
import os # 操作系统接口,提供文件和目录操作
import glob # 文件路径匹配,支持通配符查找文件
import tarfile # 用于解压.tar文件(常用于数据集压缩包)
import json # 用于JSON格式数据的读写和解析
from pathlib import Path # 面向对象的文件路径操作,替代传统的os.path
# 图像处理库
from PIL import Image # Python Imaging Library,图像处理核心库
# 科学计算库
import numpy as np # 数值计算库,提供多维数组和数学函数
# 地理空间数据相关库
from radiant_mlhub import Dataset, Collection # 地球观测数据平台访问接口
import pandas as pd # 数据分析库,用于处理表格数据和地理空间属性数据
# Google Colab环境特定
from google.colab import drive # 挂载Google Drive云存储
# TensorFlow深度学习框架
import tensorflow as tf # 主框架,用于构建和训练神经网络
import tensorflow_io as tfio # TensorFlow I/O扩展,提供地理空间数据格式支持
from tensorflow.keras import backend # Keras后端接口,用于底层操作
# 地理空间数据处理
import rasterio # 专业栅格数据处理库(如卫星影像)
# 图像变换
from skimage.transform import resize # SciKit-Image的缩放功能,用于调整图像大小
# Hugging Face预训练模型
from transformers import TFSegformerForSemanticSegmentation # 基于Segformer的语义分割模型(TensorFlow版本)
挂载谷歌驱动器以访问我们生成的输入和输出。
# 设置文件夹路径(区分Google Colab环境和本地环境)
# 检测当前是否在Google Colab环境中运行
# get_ipython()函数获取当前IPython实例,如果在Colab中会包含'google.colab'字符串
if 'google.colab' in str(get_ipython()):
# ============================================
# Google Colab云端环境配置
# ============================================
# 挂载Google Drive云存储到Colab虚拟机
# 执行后会要求输入授权码,将云端存储挂载到/content/gdrive目录
drive.mount('/content/gdrive')
# 设置处理后数据的存储目录(指向Google Drive)
# 通常用于存放预处理的训练数据、模型输出等
processed_outputs_dir = '/content/gdrive/My Drive/tf-eo-devseed-2-processed-outputs/'
# 设置用户输出目录(指向Google Drive)
# 用于存放用户自定义输出,如预测结果、中间文件等
user_outputs_dir = '/content/gdrive/My Drive/tf-eo-devseed-2-user_outputs_dir'
# 如果用户输出目录不存在,则创建该目录
if not os.path.exists(user_outputs_dir):
os.makedirs(user_outputs_dir) # 创建目录(包括任何必要的父目录)
# 提示当前运行环境
print('Running on Colab')
else:
# ============================================
# 本地环境配置(非Colab环境)
# ============================================
# 设置处理后数据的存储目录(本地路径)
# os.path.abspath() 获取绝对路径,"./"表示当前目录
processed_outputs_dir = os.path.abspath("./data/tf-eo-devseed-2-processed-outputs")
# 设置用户输出目录(本地路径)
user_outputs_dir = os.path.abspath('./tf-eo-devseed-2-user_outputs_dir')
# 如果用户输出目录不存在,则创建该目录
if not os.path.exists(user_outputs_dir):
# 创建用户输出目录
os.makedirs(user_outputs_dir)
# 创建处理后数据目录
os.makedirs(processed_outputs_dir)
# 提示当前运行环境并显示数据存储路径
print(f'Not running on Colab, data needs to be downloaded locally at {os.path.abspath(processed_outputs_dir)}')
# 注意:这段代码结束后,两个变量将被定义:
# 1. processed_outputs_dir - 预处理数据的存储路径
# 2. user_outputs_dir - 用户输出文件的存储路径
Mounted at /content/gdrive
Running on Colab
# 设置预处理数据使用标志
# 控制是否使用已预处理的数据输出,还是重新生成
use_preprocessed_outputs = True # 设为True表示使用预处理的输出数据,False表示重新生成
# 以下代码被注释掉,原意是切换到用户输出目录以写入数据
# 我们将其注释掉,以便在没有mlhub API密钥的情况下也能训练模型
# 取消注释这行将改变当前工作目录到用户输出目录
# %cd $user_outputs_dir
# 重要提示:如果你想使用预处理的输出数据,请取消下面这行的注释
# 然后跳过标记有"# Skip if using preprocessed outputs"注释的代码单元格
# 这行代码将当前工作目录切换到预处理输出数据目录
%cd $processed_outputs_dir
# 实际执行的命令:使用IPython魔术命令%cd切换到processed_outputs_dir目录
# $processed_outputs_dir是之前定义的变量,包含预处理数据的存储路径
加载用于微调的地理空间数据
在本示例中,我们将使用 LandCoverNet 南美数据集,该数据集包含 Sentinel-1、Sentinel-2 和 Landsat 8 影像以及土地覆盖标签。这些数据量非常大,因此我们将创建并使用,为演示目的,真彩色(红、绿、蓝)Landsat 8 影像的子集。除本次演示外,我们鼓励尝试使用其他影像数据集。
# 配置Radiant Earth MLHub访问(仅在需要重新处理数据时使用)
# 如果使用预处理好的输出数据,则无需执行此配置
# 以下代码被注释掉,因为它仅在需要从MLHub下载原始数据时才需要
# !mlhub configure
# 这行命令会在终端运行"mlhub configure",引导用户配置API密钥
# 使用前需要在 https://mlhub.earth/ 注册账号并获取API密钥
# 查看可用的输入数据(探索数据集)
# 以下代码也被注释,因为当前使用预处理数据,不需要重新下载
# ds = Dataset.fetch('ref_landcovernet_sa_v1') # 从MLHub获取指定数据集
# for c in ds.collections: # 遍历数据集中的所有数据集合
# print(c.id) # 打印每个数据集合的ID
APIKeyNotFound Traceback (most recent call last)
in <cell line: 2>()
1 # Check the available input data
—-> 2 ds = Dataset.fetch(‘ref_landcovernet_sa_v1’)
3 for c in ds.collections:
4 print(c.id)
/usr/local/lib/python3.10/dist-packages/radiant_mlhub/models/dataset.py in fetch(cls, dataset_id_or_doi, api_key, profile)
237 “””
238 return cls(
–> 239 **client.get_dataset(dataset_id_or_doi, api_key=api_key, profile=profile),
240 api_key=api_key,
241 profile=profile,
/usr/local/lib/python3.10/dist-packages/radiant_mlhub/client/datasets.py in get_dataset(dataset_id_or_doi, api_key, profile)
257 return get_dataset_by_doi(dataset_id_or_doi, api_key=api_key, profile=profile)
258 else:
–> 259 return get_dataset_by_id(dataset_id_or_doi, api_key=api_key, profile=profile)
260
261
/usr/local/lib/python3.10/dist-packages/radiant_mlhub/client/datasets.py in get_dataset_by_id(dataset_id, api_key, profile)
222 dataset : dict
223 “””
–> 224 session = get_session(api_key=api_key, profile=profile)
225 try:
226 return cast(Dict[str, Any], session.get(f’datasets/{dataset_id}').json())
/usr/local/lib/python3.10/dist-packages/radiant_mlhub/session.py in get_session(api_key, profile)
263
264 except APIKeyNotFound:
–> 265 raise APIKeyNotFound(‘Could not resolve an API key from arguments, the environment, or a config file.’) from None
APIKeyNotFound: Could not resolve an API key from arguments, the environment, or a config file.
下一个代码块将演示如何使用 Radiant Earth 的 Python API 从其平台下载输入数据。
# 跳过此单元格(如果使用预处理输出)
# 此部分代码用于从Radiant Earth MLHub获取原始数据集并处理
# 定义要下载的数据集集合ID
collections = [
'ref_landcovernet_sa_v1_source_landsat_8', # Landsat 8卫星影像数据源
'ref_landcovernet_sa_v1_labels' # 对应的标签数据(土地覆盖分类)
]
def download(collection_id):
"""下载指定集合的数据并解压
参数:
collection_id (str): 数据集合的唯一标识符
"""
print(f'Downloading {collection_id}...') # 显示下载进度
collection = Collection.fetch(collection_id) # 从MLHub获取集合元数据
path = collection.download('.') # 下载压缩包到当前目录,返回文件路径
# 解压.tar.gz文件
tar = tarfile.open(path, "r:gz") # 打开gzip压缩的tar文件
tar.extractall() # 解压所有文件到当前目录
tar.close() # 关闭tar文件
os.remove(path) # 删除压缩包以节省空间
def resolve_path(base, path):
"""解析相对路径为绝对路径
参数:
base (str): 基础目录
path (str): 相对路径
返回:
Path对象: 解析后的绝对路径
"""
return Path(os.path.join(base, path)).resolve() # 拼接路径并解析为绝对路径
def load_df(collection_id):
"""加载数据集合并创建数据框
参数:
collection_id (str): 数据集合ID
返回:
pd.DataFrame: 包含所有数据文件信息的数据框
"""
# 加载集合元数据
collection = json.load(open(f'{collection_id}/collection.json', 'r'))
rows = [] # 存储所有数据行
item_links = [] # 存储所有项目链接
# 遍历集合链接,找到所有数据项目
for link in collection['links']:
if link['rel'] != 'item': # 只处理类型为'item'的链接(数据项)
continue
item_links.append(link['href']) # 添加项目链接
# 处理每个数据项目
for item_link in item_links:
item_path = f'{collection_id}/{item_link}' # 项目JSON文件路径
current_path = os.path.dirname(item_path) # 当前项目所在目录
item = json.load(open(item_path, 'r')) # 加载项目元数据
# 提取瓦片ID(从项目ID中提取最后一部分)
tile_id = item['id'].split('_')[-1]
# 处理项目中的资产(数据文件)
for asset_key, asset in item['assets'].items():
rows.append([
tile_id, # 瓦片标识符
None, # 日期时间(标签数据没有)
None, # 卫星平台(标签数据没有)
asset_key, # 资产类型(如'labels')
str(resolve_path(current_path, asset['href'])) # 文件绝对路径
])
# 处理源数据链接(卫星影像数据)
for link in item['links']:
if link['rel'] != 'source': # 只处理源数据链接
continue
link_path = resolve_path(current_path, link['href']) # 源数据元数据文件路径
source_path = os.path.dirname(link_path) # 源数据所在目录
try:
source_item = json.load(open(link_path, 'r')) # 加载源数据元数据
except FileNotFoundError:
continue # 如果文件不存在则跳过
# 从元数据中提取信息
datetime = source_item['properties']['datetime'] # 影像获取时间
satellite_platform = source_item['collection'].split('_')[-1] # 卫星平台
# 处理源数据中的资产(影像波段文件)
for asset_key, asset in source_item['assets'].items():
rows.append([
tile_id, # 瓦片ID
datetime, # 影像获取时间
satellite_platform, # 卫星平台(Landsat-8)
asset_key, # 波段名称(如'B1', 'B2'等)
str(resolve_path(source_path, asset['href'])) # 波段文件路径
])
# 创建数据框
return pd.DataFrame(rows, columns=[
'tile_id', # 瓦片ID
'datetime', # 影像获取时间
'satellite_platform', # 卫星平台
'asset', # 资产类型/波段
'file_path' # 文件路径
])
# 根据标志决定执行流程
if use_preprocessed_outputs == True:
print("Using pre-processed outputs") # 使用预处理数据,跳过下载
else:
# 注意:这里有一个逻辑错误,应该显示不同的消息
print("Using pre-processed outputs") # 应该是"Downloading raw data..."
# 下载所有数据集合
for c in collections:
download(c)
# 加载标签数据到数据框(注释状态,实际执行时需要取消注释)
# df = load_df('ref_landcovernet_sa_v1_labels')
为 SegFormer 预处理数据
为准备训练和评估数据集,我们:
将数据划分为训练集、验证集和测试集。从 Landsat 8 输入数据中生成真彩色(红、绿、蓝)图像。将图像瓦片从 256×256 调整为 512×512,以配合 SegFormer 模型变体使用。使用在预训练 SegFormer 期间使用的均值和标准差对图像进行归一化。获取具有整数类值的图像标签。将预处理结果保存到本地目录。
# 设置TensorFlow数据加载和预处理参数
# AUTO = tf.data.AUTOTUNE
# 让TensorFlow自动优化数据加载的并行度,根据系统资源自动设置最佳值
AUTO = tf.data.AUTOTUNE
# BATCH_SIZE = 4
# 设置批量大小,即每次训练时输入模型的样本数量
# 较小的批量大小适合GPU内存有限的情况,但可能影响训练稳定性
BATCH_SIZE = 4
# image_size = 512
# 定义输入图像的尺寸(宽度和高度,正方形)
# 512x512像素是语义分割任务的常用尺寸,平衡细节和计算效率
image_size = 512
# 图像标准化参数(ImageNet数据集统计值)
# 这些值来自大型图像数据集ImageNet的统计,用于标准化输入图像
mean = tf.constant([0.485, 0.456, 0.406]) # RGB通道的均值
std = tf.constant([0.229, 0.224, 0.225]) # RGB通道的标准差
# 根据预处理标志选择不同的数据处理路径
if use_preprocessed_outputs == True:
print("Using pre-processed outputs")
# 如果使用预处理输出,直接加载已处理好的数据文件
# 这里应该有相应的数据加载代码(可能在其他单元格中)
else:
# 如果使用原始数据,从LandSat 8数据集中收集所有样本
# p = Path('ref_landcovernet_sa_v1_source_landsat_8/')
# 创建Path对象指向Landsat 8数据源目录
p = Path('ref_landcovernet_sa_v1_source_landsat_8/')
# subdirs = [f for f in p.iterdir() if f.is_dir()]
# 遍历目录,获取所有子目录(每个子目录对应一个数据样本)
subdirs = [f for f in p.iterdir() if f.is_dir()]
# print(len(subdirs)) # Number of samples. Should be 34229.
# 打印样本数量,应该是34229个
# 这个数字来自数据集文档,用于验证数据是否完整下载
print(len(subdirs)) # 输出样本数量,预期值:34229
# 定义用于运行预处理步骤的函数
def compile_dataset(impath, dataset_split):
"""
编译数据集:将原始Landsat 8 TIFF图像和标签转换为PNG格式
参数:
impath (str): 输入图像路径(包含B02, B03, B04等波段文件)
dataset_split (str): 数据集划分标识(如'train', 'val', 'test')
"""
# ==================== 1. 创建输出目录 ====================
# 创建用于存储RGB图像和标签图像的目录
dirs = [
f"ref_landcovernet_sa_v1_rgb_images_png_512_{dataset_split}", # RGB图像目录
f"ref_landcovernet_sa_v1_label_images_png_512_{dataset_split}" # 标签图像目录
]
for d in dirs:
if not os.path.exists(d): # 检查目录是否存在
os.makedirs(d) # 创建目录(包括父目录)
# ==================== 2. 生成RGB真彩色图像 ====================
# Landsat 8波段说明:
# B02: 蓝色波段 (0.45-0.51 µm) - 对应蓝色
# B03: 绿色波段 (0.53-0.59 µm) - 对应绿色
# B04: 红色波段 (0.64-0.67 µm) - 对应红色
# 读取红色波段(B04)并调整维度顺序 (C, H, W) -> (H, W, C)
r = rasterio.open(f"{impath}/B04.tif").read().transpose(1, 2, 0)
# 读取绿色波段(B03)
g = rasterio.open(f"{impath}/B03.tif").read().transpose(1, 2, 0)
# 读取蓝色波段(B02)
b = rasterio.open(f"{impath}/B02.tif").read().transpose(1, 2, 0)
# 堆叠三个波段创建RGB图像,并转换为0-255的uint8格式
# 注意:原始Landsat数据是16位,这里做了归一化和类型转换
rgb = (np.dstack((r, g, b)) * 255.999).astype(np.uint8)
# ==================== 3. 调整图像尺寸 ====================
# 将图像从256x256调整到512x512,以适应SegFormer模型输入要求
# 参数说明:
# - order=0: 最近邻插值(避免引入新的像素值,适合标签图像)
# - preserve_range=True: 保持原始数值范围
# - anti_aliasing=False: 禁用抗锯齿(防止边缘模糊)
resized_rgb_image = resize(rgb,
(image_size, image_size),
order=0,
preserve_range=True,
anti_aliasing=False)
# ==================== 4. 保存RGB图像 ====================
# 将numpy数组转换为PIL Image对象
rgb_im = Image.fromarray(resized_rgb_image)
# 从路径中提取图像ID(如:'100KM_123_456')
im_id = impath.split('/')[1]
# 保存为PNG格式
rgb_im.save(f"ref_landcovernet_sa_v1_rgb_images_png_512_{dataset_split}/{im_id}.png", "PNG")
# 注:TIFF保存方式被注释掉了
# tiff.imsave(f"ref_landcovernet_sa_v1_rgb_images_fl_t_{dataset_split}/{im_id}.tif", rgb)
# ==================== 5. 处理标签图像 ====================
# 构建标签文件路径:将'source_landsat_8'替换为'labels'
maskpath = impath.replace("source_landsat_8", "labels")
maskpath = maskpath[:-9] # 移除时间戳部分(如'_20180101')
# 标签文件路径
mask_file = f"{maskpath}/labels.tif"
# 读取标签图像并调整维度顺序
mask_image = rasterio.open(f"{mask_file}").read().transpose(1, 2, 0)
# 获取标签图像的第一个通道(假设标签是单通道的)
# 原始形状: (H, W, 1) -> 处理后形状: (H, W)
mask_image = mask_image[:, :, 0]
# 调整标签图像尺寸(使用最近邻插值保持整数标签值)
resized_mask_image = resize(mask_image,
(image_size, image_size),
order=0,
preserve_range=True,
anti_aliasing=False).astype('uint8')
# ==================== 6. 保存标签图像 ====================
# 转换为PIL Image对象
mask_image = Image.fromarray(resized_mask_image)
# 保存为PNG格式
mask_image.save(f"ref_landcovernet_sa_v1_label_images_png_512_{dataset_split}/{im_id}.png", "PNG")
划分数据
因为我们有 34229 个数据点可以处理,让我们先在子集上练习。
1000 个样本用于开始训练
200 个用于验证
1000 个用于测试
# 定义数据分区处理函数
def partition(part_string, part_start, part_end):
"""
批量处理数据分区:将指定范围内的样本编译到特定数据集中
参数:
part_string (str): 数据集分区名称(如'train', 'val', 'test')
part_start (int): 起始索引(包含)
part_end (int): 结束索引(不包含)
"""
i = 0 # 计数器,用于跟踪处理的样本数量
# 遍历指定范围内的所有子目录(每个子目录是一个数据样本)
for s in subdirs[part_start:part_end]:
# 调用compile_dataset函数处理每个样本
# str(s): 将Path对象转换为字符串路径
# part_string: 指定数据集分区(决定输出目录)
compile_dataset(str(s), part_string)
i = i + 1 # 增加计数器
return # 函数返回(无返回值)
# 根据预处理标志决定执行路径
if use_preprocessed_outputs == True:
print("Using pre-processed outputs")
# 如果使用预处理数据,跳过分区处理步骤
# 直接加载已处理好的数据文件
else:
# 如果使用原始数据,执行数据集分区处理
print("开始数据分区处理...")
# ==================== 1. 训练集分区 ====================
# 处理索引0-999的样本,共1000个样本作为训练集
print("处理训练集 (0-1000)...")
partition("train", 0, 1000)
print("训练集处理完成")
# ==================== 2. 验证集分区 ====================
# 处理索引1001-1200的样本,共200个样本作为验证集
print("处理验证集 (1001-1201)...")
partition("val", 1001, 1201) # 注意:实际处理1001-1200(Python切片不包含结束索引)
print("验证集处理完成")
# ==================== 3. 测试集分区 ====================
# 处理索引1202-2201的样本,共1000个样本作为测试集
print("处理测试集 (1202-2202)...")
partition("test", 1202, 2202) # 实际处理1202-2201
print("测试集处理完成")
print(f"数据分区处理完成!")
print(f"总计处理样本数: {1000 + 200 + 1000} = 2202个")
为每个分区构建数据加载器
我们现在使用上述工具来准备数据集对象,包括 prefetch() ,以提高性能。
既然数据已经被划分,我们将使用 prefetch() 将分割部分编译成 tf.data.Dataset ,以提高效率(有关此方法的更多内容,请在此处阅读)。
# ==================== 1. 图像标准化函数 ====================
def normalize(input_image):
"""标准化图像:使用SegFormer预训练时的均值方差"""
# 将图像转换为float32类型(TensorFlow标准)
input_image = tf.image.convert_image_dtype(input_image, tf.float32)
# 标准化:(x - mean) / std
# tf.maximum(std, backend.epsilon()) 防止除零
input_image = (input_image - mean) / tf.maximum(std, backend.epsilon())
return input_image
# ==================== 2. 数据加载函数 ====================
def load(image_file, mask_file):
"""加载图像和标签为Tensor"""
# 读取图像文件
image = tf.io.read_file(image_file)
# 解码PNG图像(原始代码注释了TIFF解码)
# image = tfio.experimental.image.decode_tiff(image)
image = tf.io.decode_png(image)
# 读取标签文件
mask = tf.io.read_file(mask_file)
mask = tf.io.decode_png(mask)
# 转换为float32类型
input_image = tf.cast(image, tf.float32)
mask_image = tf.cast(mask, tf.float32)
# 调整图像尺寸到512x512(虽然已经是512,但确保尺寸统一)
input_image = tf.image.resize(input_image, (image_size, image_size))
# 调整标签尺寸(使用最近邻插值,避免产生新类别)
input_mask = tf.image.resize(
mask_image,
(image_size, image_size),
method="nearest", # 最近邻插值,保持整数标签
antialias=False, # 禁用抗锯齿
)
# 标准化图像
input_image = normalize(input_image)
# 转置图像:从(height, width, channels)到(channels, height, width)
# 这是PyTorch格式,有些模型需要这种格式
input_image = tf.transpose(input_image, (2, 0, 1))
# 重塑标签张量形状
reshaped_input_mask = tf.reshape(input_mask, (512, 512, 1))
# 返回字典格式,与Hugging Face transformers库兼容
return {
"pixel_values": input_image, # 图像数据
"labels": tf.squeeze(reshaped_input_mask) # 标签数据(移除维度1)
}
# ==================== 3. 创建数据集路径列表 ====================
# 训练集:获取所有训练图像和标签的路径
train_images = glob.glob('ref_landcovernet_sa_v1_rgb_images_png_512_train//*.*')
train_labels = glob.glob('ref_landcovernet_sa_v1_label_images_png_512_train//*.*')
# 创建原始数据集(路径对)
train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
# 验证集
val_images = glob.glob('ref_landcovernet_sa_v1_rgb_images_png_512_val//*.*')
val_labels = glob.glob('ref_landcovernet_sa_v1_label_images_png_512_val//*.*')
val_ds = tf.data.Dataset.from_tensor_slices((val_images, val_labels))
# 测试集
test_images = glob.glob('ref_landcovernet_sa_v1_rgb_images_png_512_test//*.*')
test_labels = glob.glob('ref_landcovernet_sa_v1_label_images_png_512_test//*.*')
test_ds = tf.data.Dataset.from_tensor_slices((test_images, test_labels))
# ==================== 4. 构建数据管道 ====================
# 训练集数据处理管道
train_ds = (
train_ds
.map(load, num_parallel_calls=AUTO) # 并行加载和预处理数据
.batch(BATCH_SIZE) # 批处理
.prefetch(AUTO) # 预取数据,隐藏I/O延迟
)
# 验证集数据处理管道
val_ds = (
val_ds
.map(load, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
# 测试集数据处理管道
test_ds = (
test_ds
.map(load, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
print(train_ds.element_spec)
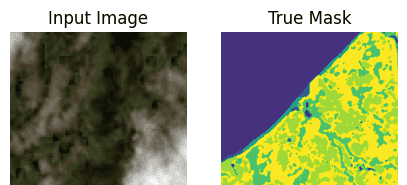
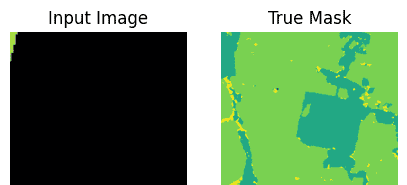
可视化数据集
import matplotlib.pyplot as plt
def display(display_list):
plt.figure(figsize=(5, 5))
title = ["Input Image", "True Mask", "Predicted Mask"]
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i + 1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis("off")
plt.show()
for samples in train_ds.take(10):
sample_image, sample_mask = samples["pixel_values"][0], samples["labels"][0]
#print(sample_image.shape, sample_mask.shape)
sample_image = tf.transpose(sample_image, (1, 2, 0))
sample_mask = tf.expand_dims(sample_mask, -1)
#print(sample_image.shape, sample_mask.shape, tf.unique(tf.reshape(sample_mask,[-1])))
display([sample_image, sample_mask])








从 Hugging Face 加载预训练的 SegFormer 检查点
现在,我们将选择一个预训练的 SegFormer 模型变体并从 Hugging Face Transformers 中加载它。存在几种 SegFormer 模型变体,例如 MiT-B0 和 MiT-B5。所有变体的检查点都可以
[在这里访问
什么是 Hugging Face?
Keras 和 TensorFlow 有几种流行的选项可以获取 CNN、RNN、Transformer 等各种深度学习模型。每种都有其优缺点以及不同程度的维护和支持:
1.Huggingface Models 是所有机器学习框架中开源模型最大的仓库。有超过 1000 个 Keras 模型可供下载。然而,大多数使用 Huggingface 的社区发布的模型都是 Pytorch 的(Pytorch 模型超过 100,000 个)。其中一些模型由社区发布,未经审核,这意味着它们可能维护得更多或更少。Keras 团队发布了超过 100 个模型:https://huggingface.co/keras-io。
2.Tensorflow Image Models 是由一位开源贡献者 Martins Bruveris 维护的项目,他是 Onfido 的高级应用科学家。可用模型列表见此处,并来源于原始论文的实现。这些可用模型来自深度学习的基本发展,包括 ResNet,一种使用残差连接高效学习特征的卷积神经网络(CNN),使得能够构建更深的网络,以及更近期的模型如 Pyramid Vision Transformer。每个模型都会针对 GPU 内存需求和图像吞吐量进行性能分析,这是训练速度的一个衡量指标。
3.Keras Applications 由 Keras 团队维护。它托管了一系列重要的模型及其基准测试,并具有独特功能,例如能够加载带有内置图像预处理功能的模型,以支持 Channel first 或 Channel last 格式的输入。虽然它不支持基于 Transformer 的模型,但它支持 ConvNeXt,一种受到视觉 Transformer �启发现代设计的 CNN 架构,其性能与近期的视觉 Transformer 模型如 SWIN Transformer 相当。
我们将使用 Hugging Face 来演示如何获取、加载和比较模型推理,因为 Hugging Face 提供了最易于使用且支持最好的 API 来获取和使用深度学习模型。此外,许多由 Keras 团队发布的模型都包含相应的 jupyter notebook 教程,详细演示了它们的使用方法。
# ==================== 1. 模型检查点设置 ====================
# 指定预训练模型的名称/路径
model_checkpoint = "nvidia/mit-b0"
# 说明:
# - "nvidia/" 表示模型由NVIDIA发布
# - "mit-b0" 是SegFormer模型的变体,b0是最小版本(轻量级)
# - 其他可用版本: mit-b1, mit-b2, mit-b3, mit-b4, mit-b5(逐渐增大)
# ==================== 2. 类别标签映射 ====================
# 类别定义来自LandCoverNet SA数据集文档:
# https://radiantearth.blob.core.windows.net/mlhub/landcovernet_sa/Documentation.pdf
# ID到标签名称的映射(数字ID -> 字符串标签)
id2label = {
0: "Background", # 背景(未分类)
1: "water", # 水体(河流、湖泊、海洋等)
2: "artificial_bare_ground", # 人造裸地(建筑工地、道路等)
3: "natural_bare_ground", # 自然裸地(沙漠、岩石等)
4: "permanent_snow_ice", # 永久冰雪(冰川、雪原)
5: "woody_vegetation", # 木本植被(森林、灌木丛)
6: "cultivated_vegetation", # 栽培植被(农田、果园)
7: "semi_natural_vegetation" # 半自然植被(草原、湿地植被)
}
# 标签名称到ID的映射(反向映射)
# 使用字典推导式创建,将id2label的键值对反转
label2id = {label: id for id, label in id2label.items()}
# 计算类别总数
num_labels = len(id2label) # 值为8(包含背景类)
# ==================== 3. 模型加载 ====================
model = TFSegformerForSemanticSegmentation.from_pretrained(
model_checkpoint, # 预训练模型标识
num_labels=num_labels, # 指定分割类别数(8类)
id2label=id2label, # ID到标签的映射
label2id=label2id, # 标签到ID的映射
ignore_mismatched_sizes=True, # 忽略输出层尺寸不匹配
)
您可能会看到一条警告,指出某些权重未被初始化并且正在创建新的权重。这是完全正常的,因为我们正在使用一个与预训练所用数据集具有不同类别结构的自定义数据集对模型进行微调。
TFSegformerForSemanticSegmentation 为我们的自定义数据集附加了一个唯一的解码器头,使用相关参数。
编译模型
现在我们将编译模型,同时选择我们的优化器和学习率。
lr = 0.001
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
model.compile(optimizer=optimizer)
值得注意的是,你将看到没有定义损失函数。原因在于 SegFormer 网络的前向传播过程会在提供的标签和图像上实现损失计算。从该过程,模型返回一个结构化的 dataclass 对象,该对象随后用于在训练过程中指导模型。
现在模型已经编译完成,我们将添加一些回调函数以监控训练过程中的信息,然后使用 fit() 方法执行模型训练。
预测回调以监控训练进度
这个回调使我们能够在训练过程中可视化模型的中间预测进展。它参考了这个教程。
# ==================== 1. 导入必要的库 ====================
from IPython.display import clear_output
# clear_output: 用于清除Jupyter Notebook单元格的输出,实现动态更新
# ==================== 2. 创建预测掩码函数 ====================
def create_mask(pred_mask):
"""
将模型的原始输出转换为类别掩码
参数:
pred_mask: 模型原始输出,形状为(batch_size, num_classes, height, width)
返回:
单样本的预测掩码,形状为(height, width, 1)
"""
# 1. 沿类别维度取argmax,获得每个像素的预测类别
# 输入形状: (batch_size, 8, 512, 512)
# 输出形状: (batch_size, 512, 512)
pred_mask = tf.math.argmax(pred_mask, axis=1)
# 2. 在最后一个维度扩展,添加通道维度
# 形状变为: (batch_size, 512, 512, 1)
pred_mask = tf.expand_dims(pred_mask, -1)
# 3. 返回批次中的第一个样本
# 返回形状: (512, 512, 1)
return pred_mask[0]
# ==================== 3. 可视化预测结果函数 ====================
def show_predictions(dataset=None, num=1):
"""
显示模型预测结果的可视化
参数:
dataset: TensorFlow数据集,包含图像和标签
num: 要显示样本数量
"""
if dataset:
# 情况1: 从数据集中获取样本进行预测
for sample in dataset.take(num):
# 从样本中提取图像和真实标签
images, masks = sample["pixel_values"], sample["labels"]
# 扩展标签维度,添加通道维度
# 形状: (batch_size, 512, 512) -> (batch_size, 512, 512, 1)
masks = tf.expand_dims(masks, -1)
# 模型预测(获取原始logits)
pred_masks = model.predict(images).logits
# pred_masks形状: (batch_size, 8, 512, 512)
# 将图像从通道优先格式转置为通道最后格式,便于显示
# 原始: (batch_size, 3, 512, 512) -> 目标: (batch_size, 512, 512, 3)
images = tf.transpose(images, (0, 2, 3, 1))
# 显示图像、真实标签和预测结果
display([
images[0], # 原始图像
masks[0], # 真实标签
create_mask(pred_masks) # 预测结果
])
else:
# 情况2: 使用全局定义的样本图像进行预测
# 假设sample_image和sample_mask已在外部定义
display([
sample_image, # 样本图像
sample_mask, # 样本真实标签
create_mask(model.predict(tf.expand_dims(sample_image, 0))) # 预测
])
# ==================== 4. 训练回调类 ====================
class DisplayCallback(tf.keras.callbacks.Callback):
"""
自定义训练回调,在每个epoch结束时显示预测结果
继承自tf.keras.callbacks.Callback,可以集成到Keras训练流程中
"""
def __init__(self, dataset, **kwargs):
"""
初始化回调
参数:
dataset: 用于展示预测的数据集
**kwargs: 传递给父类的其他参数
"""
super().__init__(**kwargs) # 调用父类初始化
self.dataset = dataset # 存储数据集引用
def on_epoch_end(self, epoch, logs=None):
"""
每个epoch结束时自动调用的方法
参数:
epoch: 当前epoch索引(从0开始)
logs: 包含训练指标的字典
"""
# 1. 清除之前的输出,实现动态更新效果
clear_output(wait=True)
# 2. 显示当前模型的预测结果
show_predictions(self.dataset)
# 3. 打印epoch信息
print("
Sample Prediction after epoch {}
".format(epoch + 1))
# 注意: epoch从0开始,所以显示时加1
训练模型
# 查看训练历史
print("训练历史可用键:", history.history.keys())
# 通常包括: ['loss', 'accuracy', 'val_loss', 'val_accuracy']
# 绘制训练曲线
import matplotlib.pyplot as plt
def plot_training_history(history):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# 损失曲线
ax1.plot(history.history['loss'], label='训练损失')
ax1.plot(history.history['val_loss'], label='验证损失')
ax1.set_title('模型损失')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.legend()
# 准确率曲线
ax2.plot(history.history['accuracy'], label='训练准确率')
ax2.plot(history.history['val_accuracy'], label='验证准确率')
ax2.set_title('模型准确率')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
ax2.legend()
plt.tight_layout()
plt.show()
plot_training_history(history)
推理
show_predictions(test_ds, 10)


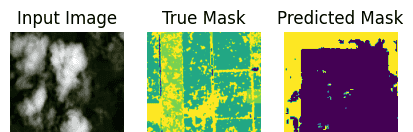





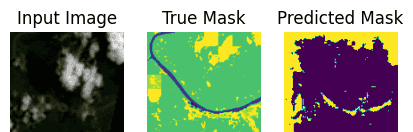

结论
这是一段关于使用 SegFormer 架构通过 Vision Transformers 进行自定义语义分割任务的简要介绍。
进一步实验中,建议您:
在预处理中添加数据增强,以探索其对模型准确性和鲁棒性的影响。从更大的 SegFormer 模型检查点加载并微调模型。将微调后的模型分享到 Hugging Face Hub,供他人尝试。这可以通过 model.push_to_hub(“your-username/your-awesome-model”) 完成。然后,您可以使用 TFSegformerForSemanticSegmentation.from_pretrained(“your-username/your-awesome-model” 加载该模型。这是一个端到端的示例。还有一个回调可以允许您在模型微调过程中将模型检查点推送到 Hugging Face Hub。它是 PushToHubCallback Keras 回调。示例在这里,这里是该回调的使用示例。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...