我们把 OpenAI 的 text-embedding-3-small 当作主要测试对象来跑了一轮基线对比,测完之后又把阿里和腾讯的新方案也拉进来做第二轮比拼,准备完整评估吞吐、延迟和花的钱。选型这事儿先放一边再看,得把所有细节拆开来逐条比。
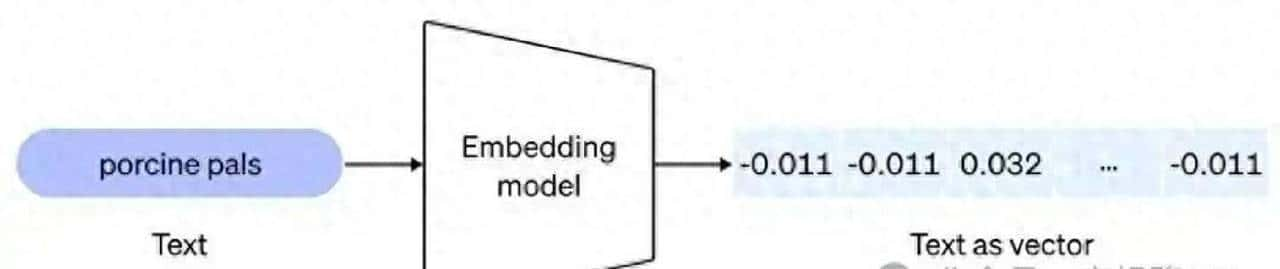
先把要测的东西拆成小项:检索准确率、向量维度、打分延迟、内存占用、批处理吞吐、向量压缩后精度损失和授权成本。数据用的是真实业务样本,既有长文本也有短文本,既覆盖行业术语,也有问答对和各种召回场景,目的是让结果尽量贴近线上真实情况。测评步骤不复杂但狠认真:把同一批数据分别丢给不同模型,先做向量化,再进向量库检索,记录 top-k 命中率、平均查询延迟和模型推理时间,同时统计各模型占用的显存和磁盘空间。数据集这块下了功夫,额外加了几类专门语料,看看模型在垂直领域里表现出啥差别。
社区里常见的通用模型在多数场景下表现稳,但一碰医疗、法律这种专业文本,许多细节词被漏掉。为了解这个问题,我们单独跑了领域测试,拿 BioBERT、LegalBERT 这类专用模型去对照。结果也挺直观:专用模型在专有术语、缩写和长句子语义上更敏感,像是带了放大镜;通用模型在延迟和跨场景泛化上更省心,更容易一套模型顶多个场景用。但是如果要在垂直行业深挖,得准备把专用模型按需调用,路由策略要设计好。
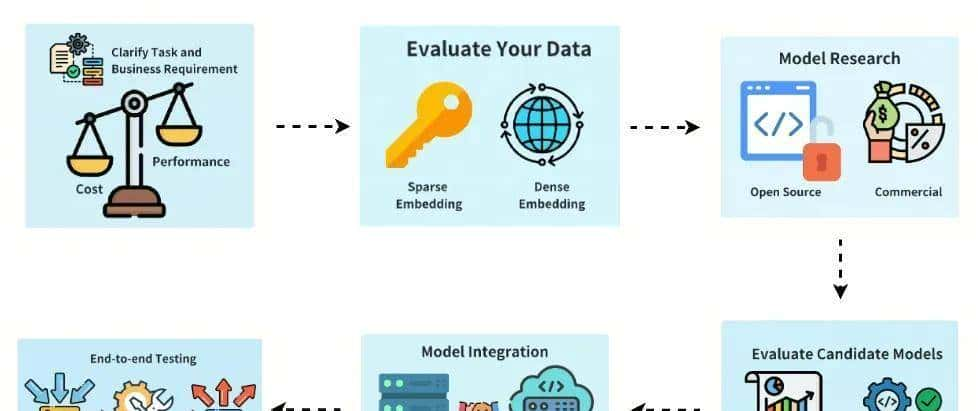
候选名单里有 text-embedding-3-small(1536 维)、阿里的 Qwen3-Embedding、腾讯的 Conan-Embedding-V2。text-embedding-3-small 的特点比较明显:维度适中、推理延迟低、模型体积小,适合对延迟敏感的大规模语义检索。阿里和腾讯的模型在国内生态里更容易接入现有云服务和权限体系,合规、成本上比较友善。这不是只比跑分,得看能不能顺利落地到你现有技术栈里——这点在评估里占比挺大。
数据层面也要摸透。文本的长度分布、实体类型、术语密度、语言风格(口语化还是正式)、有没有拼写错误或中英文混杂,这些都会影响向量化效果。还有会不会有多模态需求:未来要把图片和文本放一起检索的话,模型得能处理多模态,否则就要做一层融合。根据这些特性,你才能决定需不需要预处理、要不要改分词策略、是否要加领域词表或做微调。
社区活跃度和文档支持很关键。我们挑模型时会看 issue 解决速度、是否有成熟 SDK、有没有落地案例参考。模型再牛,遇到卡点没参考资料也得慢吞吞。经验告知我们,社区活跃的模型在碰到兼容性或性能调优时,能省不少时间。
评估指标分成三类:语义质量、系统性能和业务成本。语义质量看召回、准确率、MRR;系统性能看 P99 延迟、吞吐量、内存占用;业务成本看调用费、硬件需求、运维复杂度、授权限制。测的时候把每个模型在这三类上的表现放到一个表里,方便直观比较强项和短板。测试还跑了梯度场景:轻量查询峰值、持续高并发、批量向量构建、向量压缩后的精度回归等。
部署上我们做了两套对比:直接用云上 API 和自托管模型服务。云上调用上线快、维护少,但长期成本和数据隐私得算清楚,又有请求配额限制。自托管能省钱、数据掌控度高,但要预留 GPU、做优化、拉更新,还得建监控和回滚流程。实践里更推荐的做法是先用云服务验证概念,等跑稳了再把表现最好的几款迁到自托管环境做压测。多区域部署还要思考路由、向量库复制和一致性策略。
向量数据库和检索链路也不能马虎。我们用 Milvus 和 Pinecone 做了对照,主要看索引构建速率、查询延迟、以及向量压缩对检索效果的影响。并发上去后,分片和索引类型(像 HNSW、IVF)选择就很关键。缓存策略也要讲究:冷启动用户可以走预热索引,热点数据用内存缓存来降延迟。有位工程师现场说,真正的性能瓶颈常常不是模型本身,而是你把向量库和检索链路调不对。
量化与加速技术也单独测了。每个模型都做了 FP16、INT8 的推理测试,观察精度损失和延迟变化。发现有些模型在 INT8 下召回会明显掉,这时就得决定是先做主动评估再量化。GPU/CPU 的混合部署策略也要先规划,GPU 延迟低但成本高,CPU 在批量处理或非实时向量化场景里性价比不错。
权限和授权问题在评估表里被单独列出。模型授权方式五花八门,有的能完全自托管,有的只能走云 API,还有条款会限制商业用途。合规团队把这些条款逐条过了一遍,避免上线后踩到法律雷区。
测试结束后,团队把结果整理成清单,明确每款模型适合的场景:例如在线低延迟检索优先思考 text-embedding-3-small;垂直行业检索可以思考领域专用模型或对通用模型微调;合规和本地化要求高的情况,阿里或腾讯的方案更容易落地。有同事笑说,选模型跟买车差不多,得看你是要省油的代步车还是能拉货的皮卡。
实施层面已经细化到工程手册:做好 API 层、缓存策略、失败降级逻辑和监控面板,准备回滚预案和定期复审计划。负责人列了时间表:第一周做全量基线测试,第二周到第三周跑长期稳定性测试,第四周开始小流量灰度观测。阿里和腾讯的模型会按同样流程跑第二轮,最后形成可执行的替换方案。
所有测试数据、脚本和测评结果都存进内部仓库,测评报告会在项目系统里持续更新,等第二轮结果齐了再做最终决策。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...