
大家本地部署DeepSeek残血版本的大模型,第一需求就是可以自己独立用,不会由于服务器繁忙,而用不了。第二需求就是想建立个人知识库,让这个推理模型更好用,可以用上自己的大量私人资料。目前建立个人知识库的最简单方案就是DeepSeek R1 + Ollama + Open-WebUI套装。这个建立简单是超级简单,但是用起来并不是很好用,总之是,理想很丰满,现实很骨感。实践下来,发现并不太好用。
关于如何安装DeepSeek R1 + Ollama + Open-WebUI套装,请参见之前的文章:
本地化部署32B版本残血DeepSeek R1模型?实践证明,没啥大用!
下面简单说一下如何建立个人知识库,并在推理的时候使用。
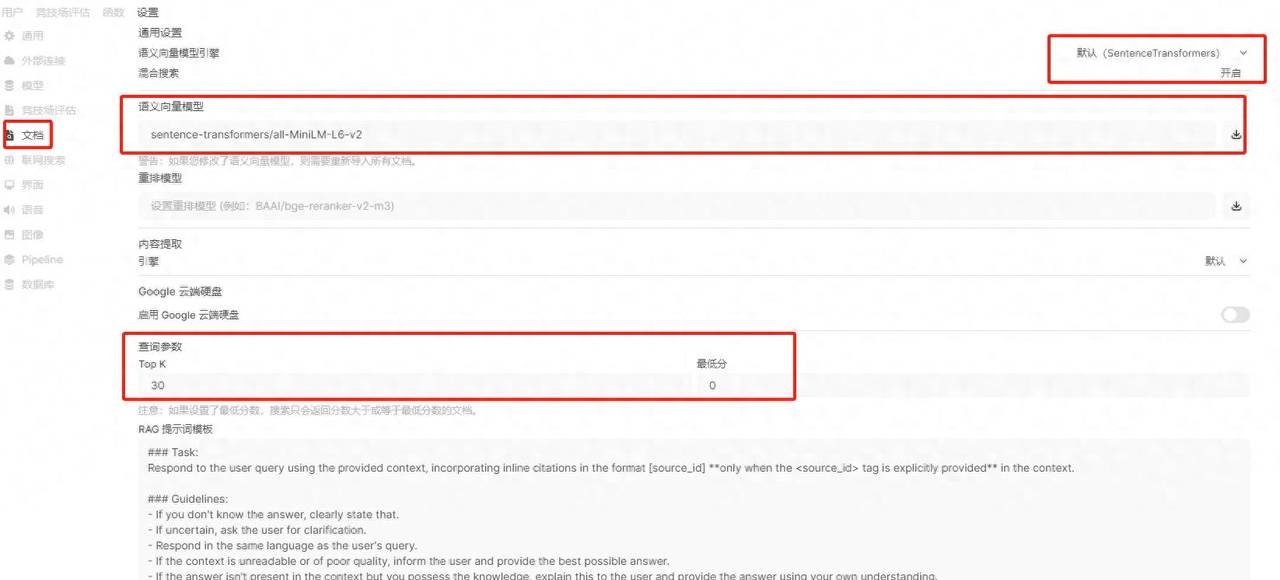
设置语义向量模型
这个第一步超级重大,否则上传文件时候会失败。
设置方法:管理员面板 -》 设置 -》文档
具体设置如下图所示:
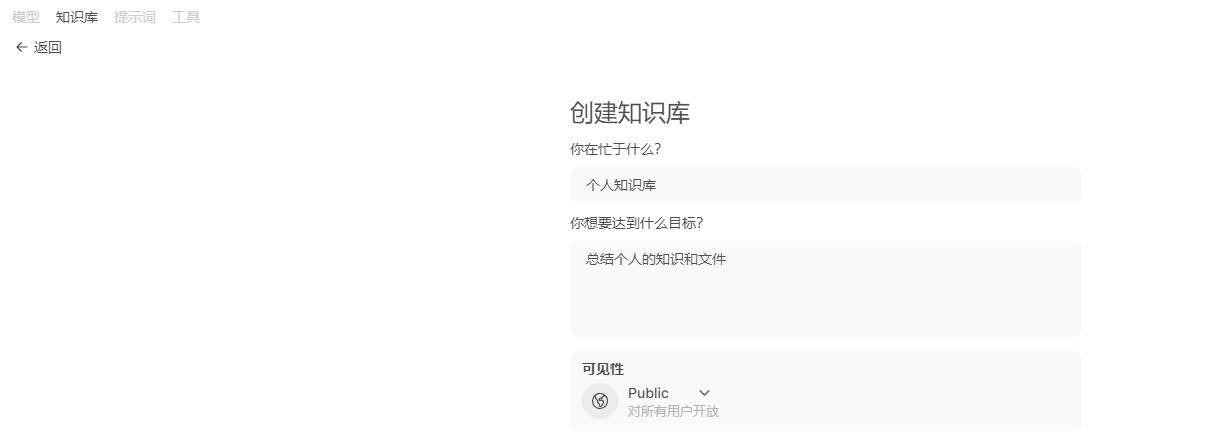
创建知识库
创建方法:工作空间-》知识库-》新建
上传文件到个人知识库
可以上传文件,文件夹等等。
创建新的私有模型
创建方法:工作空间-》模型-》新建
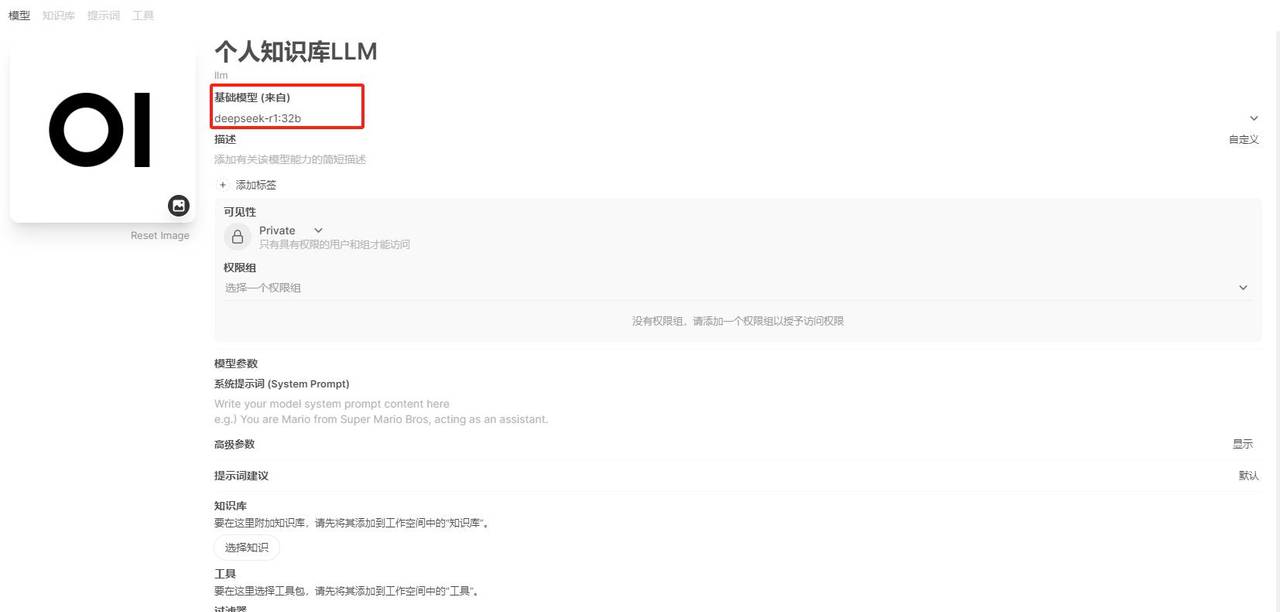
这一步注意需要选择之前部署的基础模型为 deepseek-r1:32b。
选择知识
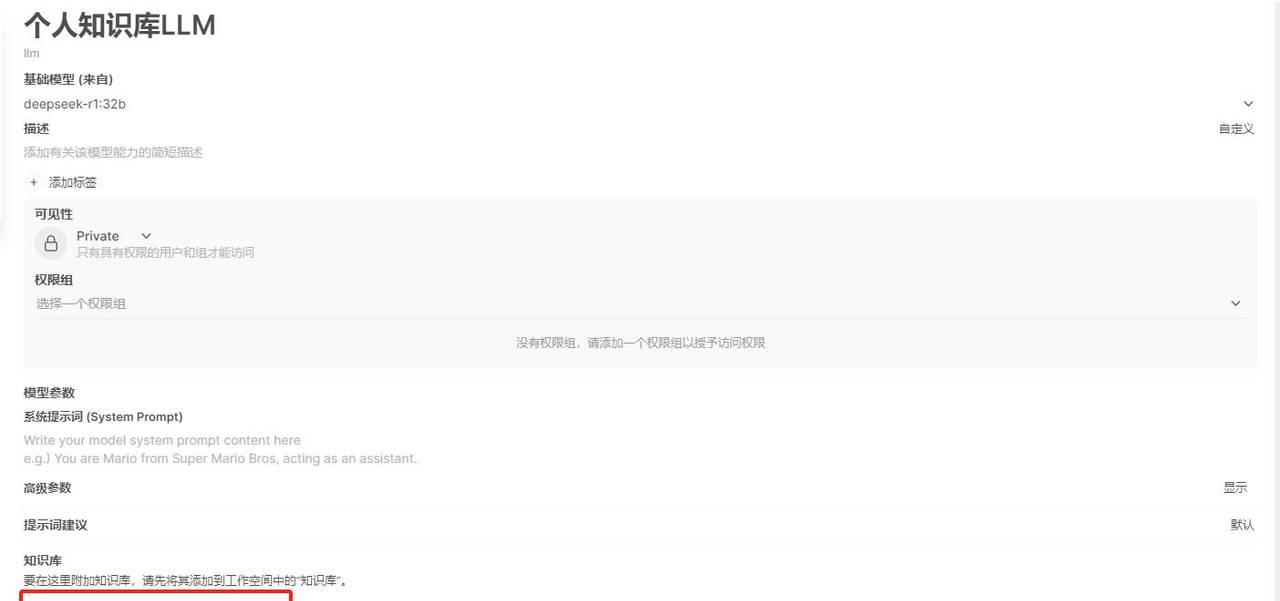
选择刚才创建的知识到知识库中。
最后添加一下描述之类的设置就可以保存了。
选择个人知识库LLM进行推理
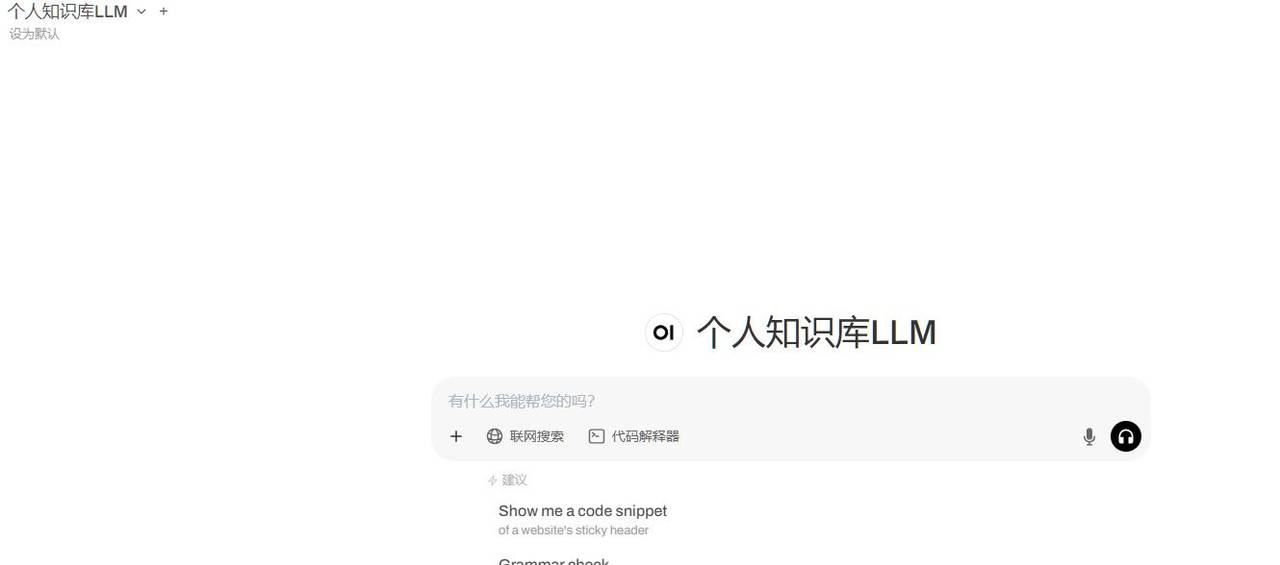
好了,我们可以使用我们自己的个人知识库进行推理了。
我尝试了一下,效果并不太好。
由于它的工作原理是:
Open WebUI 的个人知识库主要基于 检索增强生成(Retrieval-Augmented Generation, RAG) 技术,并结合本地化的文档管理与向量数据库实现知识整合。其核心原理是通过将用户提供的文档内容进行分割、嵌入(Embedding)和存储,在用户提问时检索相关上下文片段,再结合大语言模型(LLM)生成更精准的答案。
它的文本分割的局限性:若分割策略不当(如块大小或重叠不足),可能导致上下文断裂,影响检索准确性。语义匹配偏差:向量检索依赖嵌入模型的质量,若模型对专业术语或特定领域语义捕捉不足,可能返回不相关片段。本质上,他是先从个人资料库找几篇相关资料,然后读取分析,再进行推理解答。由于分割的不好,它不能全局信息,也不能同时使用所有私有知识库的信息,融会贯通来思考,总之,和我们预想的不太一样。大家可以自己尝试一下就能理解了。
总结:
理想很丰满,现实很骨感,这个个人知识库可用但是不太好用!
如果需要好用,可能需要更专业的工具或定制化开发,这些可能是小白用户没法自己搞定的。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录






我交钱直接用满血的
多少钱?
dify会更好吗?
还没试过,有空试一下
这和deepseek有什么关系,它又不是embedding模型,chunks是embedding模型的能力,包括空间向量维度,提示RAG,如果chunks已经到瓶颈,换embedding模型和向量数据库,再结合rerank模型。
嗯,打算换一个试试
楼主说的没错,本地ai知识库,首先是知识库文件向量化问题,找一个对中文好的才行,第二低阶ai大模型,像是deepseek-r1-14b,它都不一定读懂你的话,再让它从找到的片段组织和推理,再让它最后回答你,这中间几道转换,很难得到你想要的答案。我目前用cherry studio 连接硅基流动的满血r1模型还不错。
本质上是从你海量本地知识库中提取几个小段,然后deepseek,只能根据这几个小段结合它自身知识分析,关键是deepseek对你的知识库不了解,就靠这点信息回答落差肯定大。除非微调门槛降下来,让deepseek真正学会你知识库知识。RAG从地层上讲有缺陷
不是嵌入环节,是蒸馏版本做知识库不行,主要是读取文件不准确,很多胡说八道
你咋知道的?
直接调用腾讯云api,671b满血,cherry studio建立私有知识库
本地部署,目前只能算是个玩具,根本不能实用。万元以上的电脑才勉强够用。
CPU: i9-11900K 3.5GHZ x 16核内存:64GGPU: RTX3090 24G显存OS: Ubuntu 22硬盘:固态 10T我这配置可不只1万啊
牛逼能跑32B的显卡得过万了吧
感觉这个瓶颈在嵌入式模型那一环
很有可能,打算换个嵌入式模型试试
你要文本向量化配合 maxkb 或者 rag,anything llm,向量化要用其他嵌入式的模型来处理文本,你这就是部署了个聊天功能
你自己搞过吗?效果怎么样?
搭建知识库要用rag,试试dify+deepseek
你试了吗?我周末打算试试
这个模型是需要训练的,不是你给完个人知识库就马上能用的,需要你在多轮会话中不断的训练,让AI学会你的诉求,这样才越用越好用!
要用对中文更友好的嵌入模型,然后主模型也得好一点。个人电脑再怎么弄都是过家家,还是用开发平台上的服务比较好。我用百度的开发平台上传孩子的政史地教材电子版做RAG,回答的准确率还是可以的。反正新注册多少会送一点。验证完就不需要了。也不花什么钱。
我换个嵌入模型试试
RAG是会占用输入tokens,资料库大了会卡,或者干脆就超出模型最大输入tokens。
可以本地知识库+在线api
可以的,这样还简单
很有意义的探索,我也是有这个疑问,期待楼主继续专研
谢谢,有空再接着研究。
就是rag嘛,可以试试别的rag框架,提高文档质量
有空试试
感谢共享。我刚想搞一个同样的需求。如果后续你有其他测试,能共享就太好了。
好的,有新的尝试就来更新
ollama模型上下文长度默认2K,效果很差,改成32K再试试吧
这个我好像改了