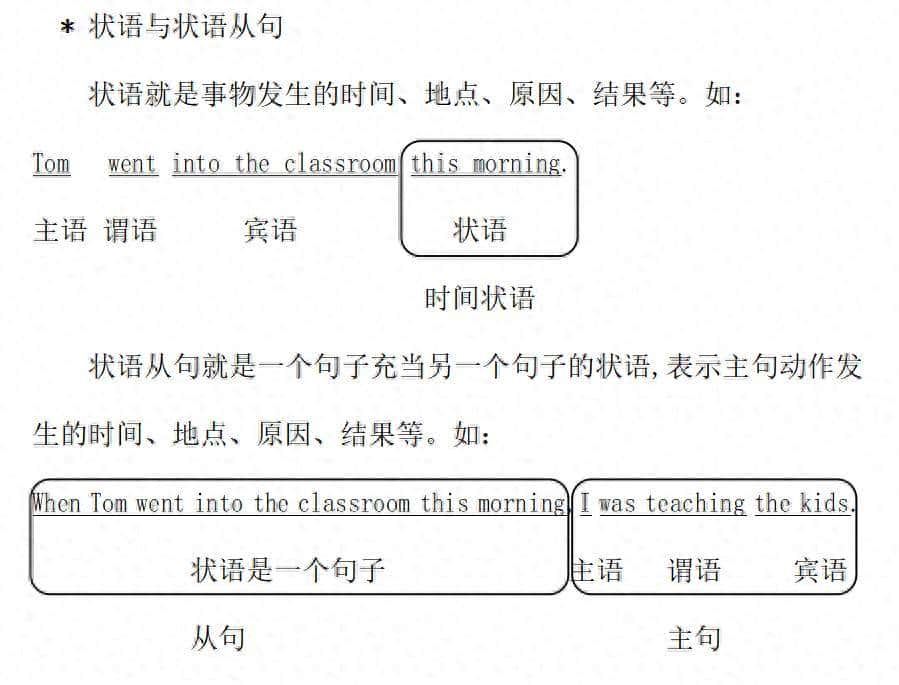
需求描述
有一大一小两个dataframe。
其中 df_big 是每个股票每天的若干个日数据,行索引为 [股票代码,交易日期] 的两层。
In[37]: df_big.shape
Out[37]: (90772, 6)
In[38]: df_big.head()
Out[38]:
close pct_chge ... cap turn_rate
symbol tdate ...
000006.SZ 20100104 11.12 -1.8535 ... 563987.787344 1.242116
20100105 10.80 -2.8777 ... 547757.922960 2.588797
20100106 10.83 0.2778 ... 549279.472746 2.728014
20100107 10.74 -0.8310 ... 544714.823388 2.015962
20100108 11.00 2.4209 ... 557901.588200 1.769723
[5 rows x 6 columns]
df_small 是某债券的每天日收益,行索引是 [交易日期]的一层
In[29]: df_small.head()
Out[29]:
yield
20100104 0.000048
20100105 0.000092
20100106 0.000423
20100107 0.000050
20100108 0.000076
目前想在 df_big 中的每个股票的数据中,都增加一列 df_small [ yield ] 的内容,并按交易日期对齐。
同时由于数据比较多,希望使用效率能高一些。
麻烦的地方是,由于有的股票上市晚,每个股票的数据行数不统一。
talk is cheap,show me the codes
方法1:用循环硬算
In[49]:
from time import time
t1 = time()
df_big= pd.read_pickle(r"d:df_big.pkl")
_, trad_date_big = zip(*df_big.index)
yield_0 = []
df_small= pd.read_pickle(r"d:df_small.pkl")
df_small_dict = {}
trad_data_small = df_small.index.values
yield_1 = df_small["yield"].values
for d, y in zip(trad_data_small, yield_1):
df_small_dict[str(d)] = y
for d in trad_date_big:
yield_0.append(df_small_dict.get(str(d), -1.0))
df_big["yield_0"] = yield_0
t2 = time()
print(f 用时 {t2-t1} 秒 )
print(df_big.tail(10))
Out[49]:
用时 0.17649459838867188 秒
close pct_chge ... turn_rate yield_0
symbol tdate...
601999.SH 20100719 11.03 0.3640 ... 1.083451 0.000063
20100720 11.28 2.2665 ... 1.129400 0.000080
20100721 11.00 -2.4823 ... 1.108417 0.000072
20100722 11.27 2.4545 ... 0.881257 0.000072
20100723 11.48 1.8634 ... 1.147836 0.000072
20100726 11.65 1.4808 ... 0.884288 0.000073
20100727 11.37 -2.4034 ... 0.495699 0.000073
20100728 11.96 5.1891 ... 1.310141 0.000072
20100729 11.87 -0.7525 ... 1.337995 0.000074
20100730 11.83 -0.3370 ... 0.877386 0.000072
[10 rows x 7 columns]
方法2:采用 pandas.merge_ordered()
from time import time
t1 = time()
df_big= pd.read_pickle(r"d:df_big.pkl")
df_small= pd.read_pickle(r"d:df_small.pkl")
df_big = df_big.reset_index()
df_small = df_small.reset_index()
df_all = pd.merge_ordered(df_big, df_small, left_on= TRADE_DT , right_on= index )
df_all2 = df_all.sort_values(by=[ S_INFO_WINDCODE , TRADE_DT ]).reset_index(drop=True)
t2 = time()
print(f 用时 {t2-t1} 秒 )
print(df_big.tail(10))
用时 0.1884779930114746 秒
S_INFO_WINDCODE TRADE_DT ... index S_DQ_CLOSE_y
90762 601999.SH 20100719 ... 20100719 0.000063
90763 601999.SH 20100720 ... 20100720 0.000080
90764 601999.SH 20100721 ... 20100721 0.000072
90765 601999.SH 20100722 ... 20100722 0.000072
90766 601999.SH 20100723 ... 20100723 0.000072
90767 601999.SH 20100726 ... 20100726 0.000073
90768 601999.SH 20100727 ... 20100727 0.000073
90769 601999.SH 20100728 ... 20100728 0.000072
90770 601999.SH 20100729 ... 20100729 0.000074
90771 601999.SH 20100730 ... 20100730 0.000072
[10 rows x 10 columns]
嗯,方法2用时差不多,关键是代码简单干脆,言简意赅。。。。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...