后端那边实际上只回了一个 List,代码里就几行注解,业务逻辑几乎没动。前端最后拿到的,是一个包含所有设备二维码图片的 ZIP 包;下载、并发抓图、压缩、响应这些事儿,全被一个开源库给干掉了。
说白了,以前做这类下载功能,得写一堆和流打交道的样板代码。设置响应头、控制输入输出流、处理并发抓取、搞压缩、处理超时重试、捕获各种异常,动辄就是好几百行。项目里这种重复活多得很,哪儿一不小心就出问题。Linyuzai 在 GitHub 上开源的 Concept-Download 就是为了解决这种痛点。它宣称靠注解就能覆盖 SpringBoot 常见的下载场景,听着有点狠,但用起来的确 把许多麻烦活给抽离了。
举个具体的用法。产品里要导出设备二维码,后端只返回 List。在 Device 类里,把表明二维码地址的字段打上 @SourceObject,把用于生成文件名的方法打上 @SourceName。库会并发去请求这些 URL,把拿到的图片收集起来,边抓边压,最后把所有图片打成一个 ZIP 发回前端。业务代码层面除了返回对象,基本不用管下载和打包这些细节,代码干净、职责分得清。

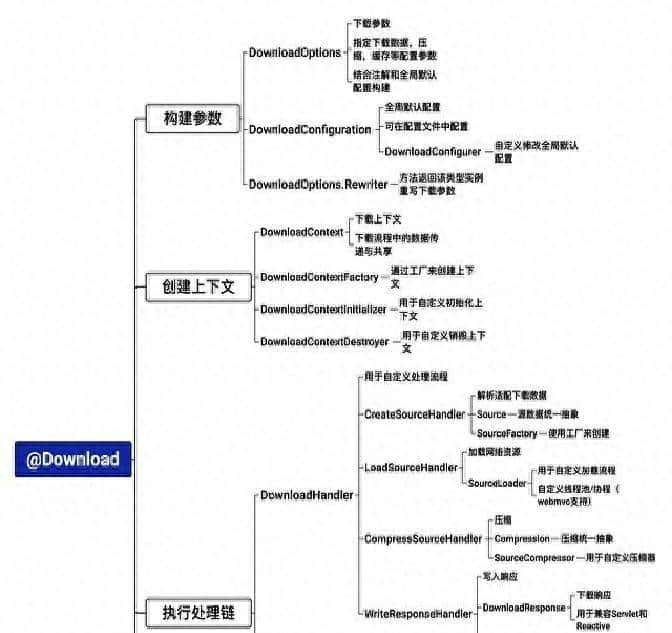
内部实现也不是把所有逻辑塞到一个大函数里,而是把流程拆成一环一环的小处理器,库里叫 DownloadHandler。每个 Handler 负责一小块事:解析哪些是资源、把资源加载成统一接口、必要时做转换、最后交给压缩器。像装配线一样,想插个额外步骤(列如给图片加水印),只要写个新的 Handler 插进去,不用去动原有代码。这种设计让扩展和维护都方便得多。
资源在内部被抽象成统一的概念——Source。不管是真实的磁盘文件、返回 File 对象、远程 HTTP 图片,还是内存里的字节流,最后都变成 Source 接口的一种实现。再配套一个 SourceFactory,根据输入自动识别并创建对应的 Source。需要支持别的协议(FTP、S3 等),只要新增一个 Factory 就行,业务层代码不用改。这个工厂式的处理,把协议细节封起来,让上层少操心。
兼容性上也下了功夫。库既能跑在传统的 WebMVC 环境,也能适配反应式的 WebFlux。WebFlux 的麻烦点在于非阻塞 IO 要跟老的阻塞式输出流结合。作者用 FluxSink 把 OutputStream 包起来,把阻塞写变成响应式的数据流。结果是原来的写流代码基本照用,但在 WebFlux 下能以流式输出的方式工作,这招挺实在。
处理各种来源的时候,库思考到并发抓取和内存占用问题。解析数据源那一步会根据注解和对象结构识别哪些字段或方法是需要当作下载项。加载资源时底层把不同来源统一成 Source 暴露的输入流,压缩模块只关心输入流集合,不用管来源类型。压缩过程采用流式压缩,边读边写,不用先把所有东西缓存到磁盘或内存里,这样能节省资源。并发抓取时会有并发数限制、超时和重试策略,出问题的资源不会把整个任务拖垮,失败信息会被收集,必要时返回部分失败的提示或只把可用资源打包返回。这些边角料想清楚写好,体验才顺畅。
从开发体验看头疼的地方被搬走了。业务代码只要告知框架“我要导出这些东西、这些字段是来源、这个方法生成名称”,具体怎么并发下载、怎么压缩、怎么写响应都交给库。结果是项目里的样板代码少了几十行、几百行,代码更清爽,出问题的概率也降了,开发者能把时间用到更该干的业务上。
要扩展能力也简单。想支持新资源类型就写个 SourceFactory;要在流程里插入额外处理,就实现一个 DownloadHandler;要调整压缩或并发策略,换掉相应实现就能生效。设计上把关键点做成可插拔的接口,而不是把配置硬编码在框架里。
项目里少了那些繁琐的 IO 代码后,接口实现看起来就像说明书那样直白:标注好来源、返回对象,ZIP 就能出来。对于常常要把各种资源打包下载的场景,这种做法把重复劳动聚焦处理,开发的注意力可以更聚焦在业务本身上。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...