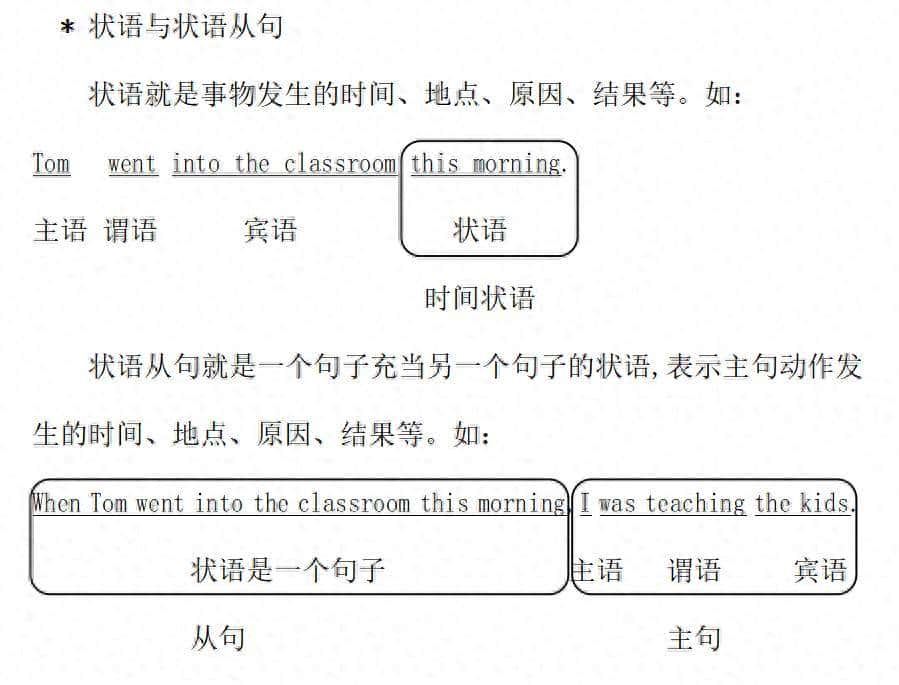
摘要:无需服务器、不用装 Hadoop 集群!本文教你用 Docker 在个人电脑上 10 分钟搭建一个完整的 Spark + Jupyter 大数据实验环境。你将能直接编写 PySpark 代码、读取 CSV/JSON 数据、执行分布式计算——这一切都在浏览器中完成,适合学习、测试与原型验证。
一、为什么用 Docker 搭建大数据环境?
传统方式安装 Spark 需要:
配置 Java 环境设置 Scala、Hadoop 依赖调整内存参数、解决版本冲突……
而 Docker 让这一切变得像“点外卖”一样简单:
隔离性:环境独立,不影响本机系统一致性:团队共享同一镜像,避免“在我机器上能跑”轻量化:无需虚拟机,资源占用低
💡 对初学者而言,Docker 是进入大数据世界的“最佳跳板”。
二、准备工作:只需三样东西
一台电脑(Windows / macOS / Linux 均可)已安装 Docker Desktop10 分钟空闲时间
✅ 验证安装:终端输入
,看到版本号即成功。
docker --version
三、核心思路:我们到底要搭什么?
我们要启动一个容器,里面包含:
Apache Spark 3.5+(含 PySpark)Jupyter Notebook(支持 Python 交互式编程)预装常用库:pandas, matplotlib, findspark
最终效果:打开浏览器 → 写 PySpark 代码 → 立即看到结果!
四、动手实操:四步搞定环境搭建
第一步:拉取官方 Spark 镜像(带 Jupyter)
我们使用社区维护良好的
jupyter/pyspark-notebook
docker pull jupyter/pyspark-notebook:latest📌 注:该镜像基于 Ubuntu,已预装 Spark、Python、Jupyter 及常用数据分析库。
第二步:创建本地工作目录(用于存放数据和代码)
mkdir ~/my-spark-lab
cd ~/my-spark-lab
echo "user_id,event_type,timestamp" > sample.csv
echo "1001,click,1700000000" >> sample.csv
echo "1002,buy,1700000100" >> sample.csv这一步创建了一个简单的 CSV 文件,后续可在 Spark 中读取它。
第三步:启动容器(关键命令)
docker run -p 8888:8888
-v $(pwd):/home/jovyan/work
--name spark-lab
-e JUPYTER_ENABLE_LAB=yes
jupyter/pyspark-notebook参数说明:
-p 8888:8888
-v $(pwd):/home/jovyan/work
--name spark-lab
-e JUPYTER_ENABLE_LAB=yes
第四步:访问 JupyterLab 并开始编码
启动后,终端会输出一行类似:
http://127.0.0.1:8888/lab?token=abc123def456...复制整个 URL 到浏览器打开进入后,点击左侧
work
sample.csv
✅ 恭喜!你的大数据实验环境已就绪!
五、第一个 PySpark 程序:读取 CSV 并统计事件类型
在 JupyterLab 中新建一个 Notebook,输入以下代码:
import findspark
findspark.init() # 自动定位 Spark 安装路径
from pyspark.sql import SparkSession
# 创建 Spark 会话(单机模式)
spark = SparkSession.builder
.appName("MyFirstSparkApp")
.master("local[*]")
.getOrCreate()
# 读取本地 CSV(注意路径是容器内的 /home/jovyan/work/)
df = spark.read.option("header", "true").csv("work/sample.csv")
# 显示数据
df.show()
# 统计每种事件的数量
df.groupBy("event_type").count().show()
# 停止会话
spark.stop()运行后,你将看到:
1+-------+-----+
2|user_id|event_type| timestamp|
3+-------+-----+
4| 1001| click|1700000000|
5| 1002| buy|170000100|
6+-------+-----+
7
8+------------+-----+
9|event_type |count|
10+------------+-----+
11| click| 1|
12| buy| 1|
13+------------+-----+✅ 这就是最简版的“大数据 ETL + 聚合分析”!
六、进阶建议:如何扩展这个环境?
| 需求 | 解决方案 |
|---|---|
| 处理更大文件 | 把真实日志放入 |
| 可视化分析 | 在 Notebook 中直接用 |
| 连接 Hive / Kafka | 使用更复杂的 Docker Compose 编排多服务(下期内容) |
| 持久化 Spark UI | 添加 |
七、常见问题排查
Q:打不开 Jupyter 页面?
A:检查 Docker 是否运行;复制完整的 token URL(不要手动输)
Q:提示 “No module named ‘pyspark’”?
A:确保使用的是
jupyter/pyspark-notebook
Q:想用 Windows 路径?
A:将
-v $(pwd):...
-v C:my-spark-lab:/home/jovyan/work
八、结语:小环境,大可能
这个轻量级实验环境虽小,却具备完整的大数据处理能力:
支持 DataFrame API(类似 pandas,但可扩展至集群)可无缝迁移到生产环境(只需改
.master("yarn")
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...