
第一打开b站,F12进入开发者模式
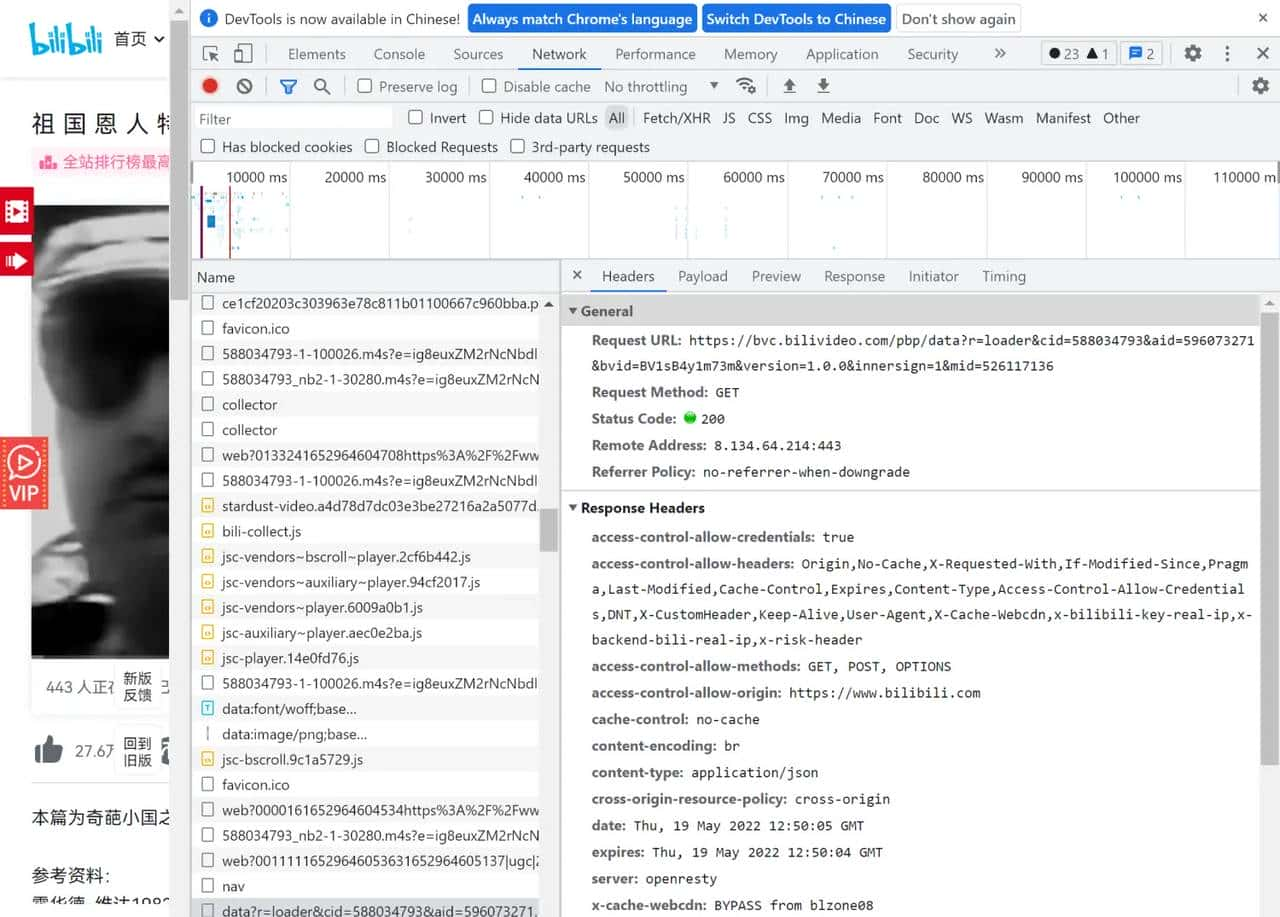
由于B站的弹幕都是储存在xml文件格式
找到对应的cid
将cid588034793连接到下面的网址
http://comment.bilibili.com/.xml
http://comment.bilibili.com/588034793.xml
加载就可看到弹幕的信息
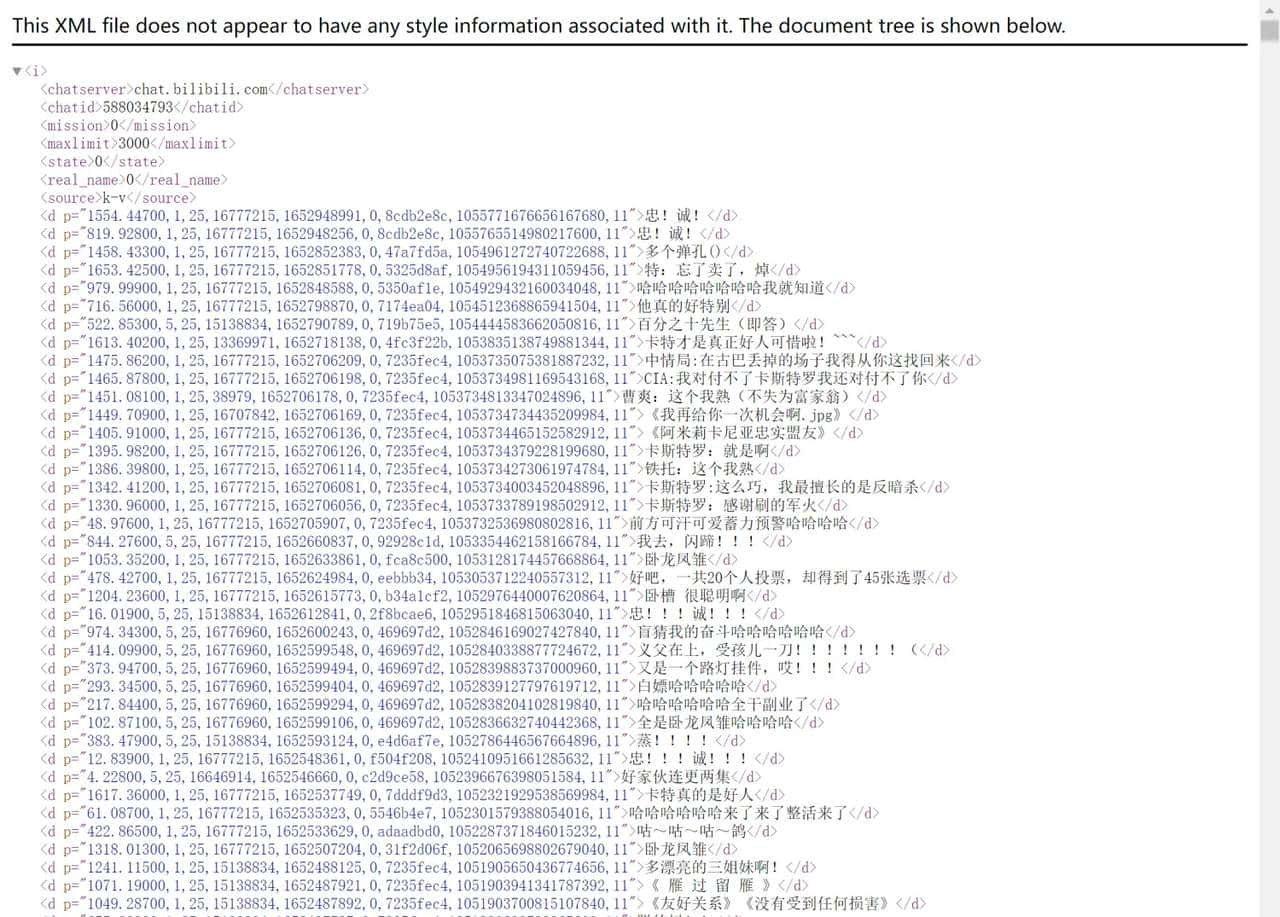
接着请求发送
使用request模拟浏览器请求发送获取弹幕
我直接把accept到useragent全部复制!
放到headers上
url = f https://comment.bilibili.com/588034793.xml
headers = { accept : */* ,
accept-encoding : gzip, deflate, br ,
accept-language : zh-CN,zh;q=0.9 ,
origin : https://www.bilibili.com ,
referer : https://www.bilibili.com/video/BV1sB4y1m73m?spm_id_from=333.337.search-card.all.click ,
sec-ch-ua : " Not A;Brand";v="99", "Chromium";v="99", "Google
Chrome";v="99" ,
sec-ch-ua-mobile : ?0 ,
sec-ch-ua-platform : "Windows" ,
sec-fetch-dest : empty ,
sec-fetch-mode : cors ,
sec-fetch-site : cross-site ,
user-agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 }
resp = requests.get(url, headers=headers)
#打印一下
print(resp.text)

得到一堆乱码
所以要更改网页编码方式
调用apparent_encoding方法获取requests模块的编码方式再重新赋值
resp.encoding = resp.apparent_encoding
#再打印一下
print(resp.text)
就能看到自己认识的中文了
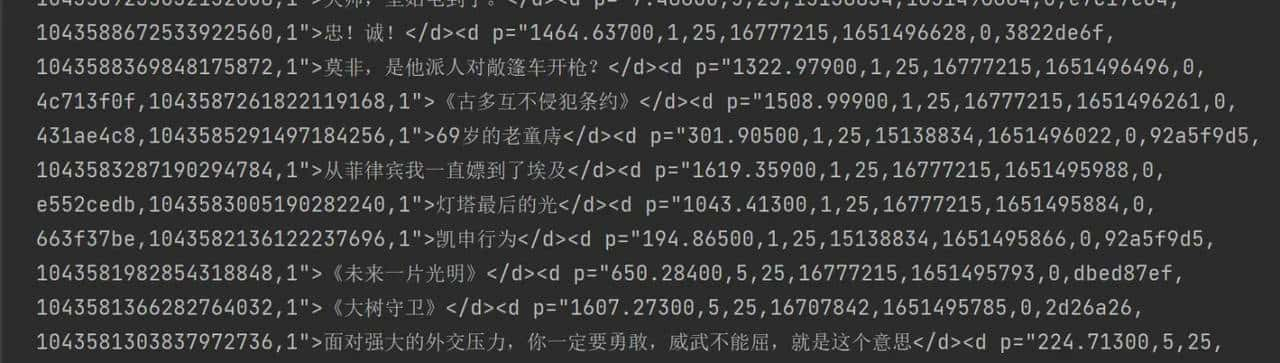
我们可以看到每一条信息字段都是以<d p= 到 </d>
实际上这是网页的标签
我们要提取出文字就需要利用正则表达式
在每个字段中只有<d p= > </d>是永恒不变的
所以我们只需要对没有规律的数字和文字利用正则表达式提取
.*?代表匹配0到无数次的字符,括号表明需要提取的内容文字
# 所以创建一个列表获取所有评论内容
ccomment = re.findall( <d p=".*?">(.*?)</d> , resp.text)
#再打印一下
print(comment)

可以看到数据都被提取出来了
接下来保存数据
创建一个csv文件
comment_path = 小约翰可汗B站弹幕.csv
if os.path.exists(comment_path):
os.remove(comment_path)
for item in comment:
with open(comment_path, a , encoding= utf-8 )as fin:
fin.write(item +
)
#以换行符进行保存
print( -------------弹幕获取完毕!------------- )
在目录上就可看到csv数据

新创建了一个py文件
读取csv文件
一开始列没有名字于是将列改名为弹幕
进行探索性分析
import numpy as np
import pandas as pd
df = pd.read_table(r C:Users86135Desktopgggpachong小约翰可汗B站弹幕.csv ,names=[ 弹幕 ])
df.shape
df.info()
df.isnull().sum()
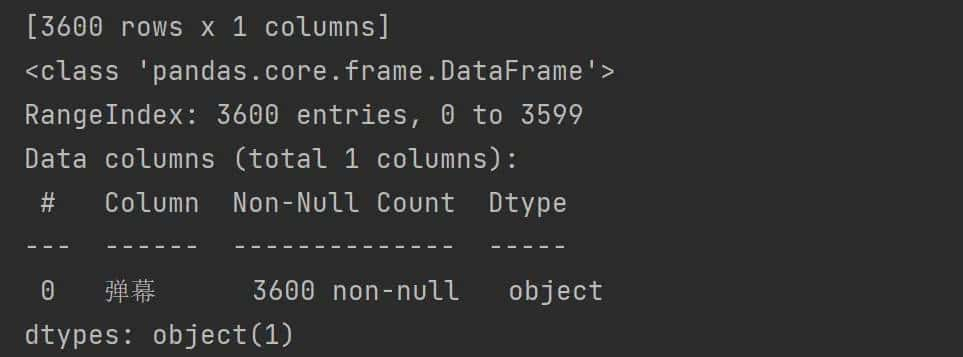
总共有3600条弹幕并且没有缺失值
导入可视化包
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#将弹幕数据清洗去空格化
a=
for i in df.弹幕:
for j in i:
j=j.strip()
a+=j
#字体
font=r"C:WindowsFontsmsyh.ttc"
#词云参数格式
wc = WordCloud(font_path=font,width=1600, height=1200
, mode= RGBA , background_color="white").generate(text=a)
# 显示词云
# 创建画布
plt.figure(figsize=(8,5))
plt.imshow(wc, interpolation= bilinear ) #图片模糊度,插值算法
#关闭坐标轴
plt.axis( off )
# wc.to_file( 词云.png ) #如果想要保存成图片,要放在plt.show()之前
plt.show()
就可以看到正方形的词云了


不想看到方正词云想来点不同的样式
导入两包
from PIL import Image
from wordcloud import WordCloud, ImageColorGenerator
# 图片转换为矩阵
mask = np.array(Image.open(r"C:Users86135Desktoppython数据清洗【案例】群聊关键字检测分析dog.jpg"))
mask.shape
wc = WordCloud(font_path="simhei.ttf",mask=mask,mode= RGBA , background_color=None).generate(text=a)
# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors) #重置词云图的颜色
# 显示词云
plt.figure(figsize=(10,6),dpi=80)
plt.imshow(wc, interpolation= bilinear ) #图片模糊度,插值算法
plt.axis( off )
wc.to_file( 狗狗词云图.png )
plt.show()

就可以看到狗狗词云啦
而且词云还跟狗挺搭的
#如果想要手动对中文文章切分可以使用jieba包
import jieba
jieba.load_userdict(r C:Users86135Desktopgggpachong小约翰可汗B站弹幕.csv )
#以jieba方式分词
for i in df.弹幕:
for j in i:
j=j.strip()
b+= .join(jieba.cut(j))
#设置去除没有意义的词列如还有,啊,只有什么的
#stopwords要自己创建
with open("stopwords.txt",mode= r ,encoding= utf-8-sig ) as file:
stopwords = file.read().splitlines()
wc = WordCloud(font_path="simhei.ttf"
,mask=mask,mode= RGBA
,stopwords=stopwords
,margin=8
,random_state=420
,background_color="white").generate(text=a)
# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors) #重置词云图的颜色
# 显示词云
plt.figure(figsize=(10,6),dpi=120)
plt.imshow(wc, interpolation= bilinear ) #图片模糊度(双线性),插值算法
plt.axis( off )
wc.to_file( 词云图.png )
plt.show()
最后出来的图就是出现比较正常的词啦

可以看出最大的词语是忠诚,如果不知道为什么是这个词的话可以去b站看看他的视频
具体代码是这些
爬虫:
import requests
import re, os
url = f https://comment.bilibili.com/588034793.xml
headers = { accept : */* ,
accept-encoding : gzip, deflate, br ,
accept-language : zh-CN,zh;q=0.9 ,
origin : https://www.bilibili.com ,
referer : https://www.bilibili.com/video/BV1sB4y1m73m?spm_id_from=333.337.search-card.all.click ,
sec-ch-ua : " Not A;Brand";v="99", "Chromium";v="99", "Google
Chrome";v="99" ,
sec-ch-ua-mobile : ?0 ,
sec-ch-ua-platform : "Windows" ,
sec-fetch-dest : empty ,
sec-fetch-mode : cors ,
sec-fetch-site : cross-site ,
user-agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 }
resp = requests.get(url, headers=headers)
#print(resp.text)
# 调用.encoding属性获取requests模块的编码方式
# 调用.apparent_encoding属性获取网页编码方式
# 将网页编码方式赋值给response.encoding
resp.encoding = resp.apparent_encoding
comment = re.findall( <d p=".*?">(.*?)</d> , resp.text)
comment_path = 小约翰可汗B站弹幕.csv
if os.path.exists(comment_path):
os.remove(comment_path)
for item in comment:
with open(comment_path, a , encoding= utf-8 )as fin:
fin.write(item +
)
print( -------------弹幕获取完毕!------------- )
词云:
from PIL import Image
from wordcloud import WordCloud, ImageColorGenerator
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import jieba
df = pd.read_table(r C:Users86135Desktopgggpachong小约翰可汗B站弹幕.csv ,names=[ 弹幕 ])
df.shape
df.info()
df.isnull().sum()
#将弹幕数据清洗去空格化
a=
for i in df.弹幕:
for j in i:
j=j.strip()
a+=j
#字体
font=r"C:WindowsFontsmsyh.ttc"
#词云参数格式
wc = WordCloud(font_path=font,width=1600, height=1200
, mode= RGBA , background_color="white").generate(text=a)
# 显示词云
# 创建画布
plt.figure(figsize=(8,5))
plt.imshow(wc, interpolation= bilinear ) #图片模糊度,插值算法
#关闭坐标轴
plt.axis( off )
#wc.to_file( 词云.png ) #如果想要保存成图片,要放在plt.show()之前
#plt.show()
# 图片转换为矩阵
mask = np.array(Image.open(r"C:Users86135Desktoppython数据清洗【案例】群聊关键字检测分析dog.jpg"))
mask.shape
wc = WordCloud(font_path="simhei.ttf",mask=mask,mode= RGBA , background_color=None).generate(text=a)
# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors) #重置词云图的颜色
# 显示词云
plt.figure(figsize=(10,6),dpi=80)
plt.imshow(wc, interpolation= bilinear ) #图片模糊度,插值算法
plt.axis( off )
wc.to_file( 狗狗词云图.png )
plt.show()
#如果想要手动对中文文章切分可以使用jieba包
jieba.load_userdict(r C:Users86135Desktopgggpachong小约翰可汗B站弹幕.csv )
b =
#以jieba方式分词
for i in df.弹幕:
for j in i:
j=j.strip()
b+= .join(jieba.cut(j))
#设置去除没有意义的词列如还有,啊,只有什么的
with open("stopwords.txt",mode= r ,encoding= utf-8-sig ) as file:
stopwords = file.read().splitlines()
wc = WordCloud(font_path="simhei.ttf"
,mask=mask,mode= RGBA
,stopwords=stopwords
,margin=8
,random_state=420
,background_color="white").generate(text=b)
# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors) #重置词云图的颜色
# 显示词云
plt.figure(figsize=(10,6),dpi=120)
plt.imshow(wc, interpolation= bilinear ) #图片模糊度(双线性),插值算法
plt.axis( off )
wc.to_file( 词云图.png )
plt.show()
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...




