一、背景需求:
20251114 课题中期指导,本学期共有3个大、3个小课题立项

前期做了上下学期资料批量的课题档案袋,刚开始有很多的问题——日期格式必须换成年月日的文本格式。文本占位符字母写错等。
【办公类-89-01】20250103用“课题阶段资料模版“批量制作“7个课题档案袋“ https://mp.csdn.net/mp_blog/creation/editor/144920339
https://mp.csdn.net/mp_blog/creation/editor/144920339
本次继续修改代码,完善档案袋内容。
二、收集信息
1、从证书网上下载证书,做好文件命名
2、从课题上报网站下载申请书,做好文件命名

3、把信息贴入去年做好的模版里,把日期信息修改掉
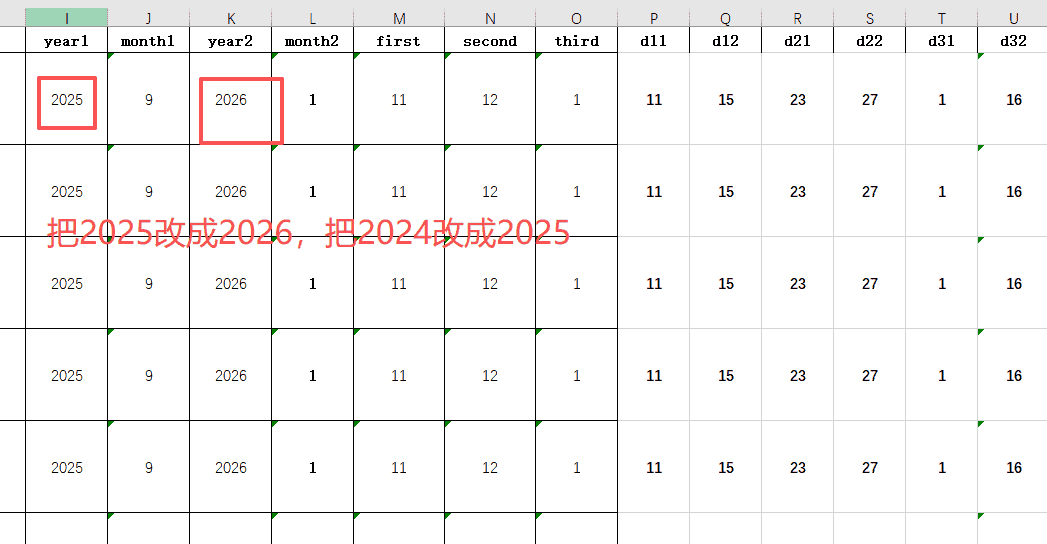
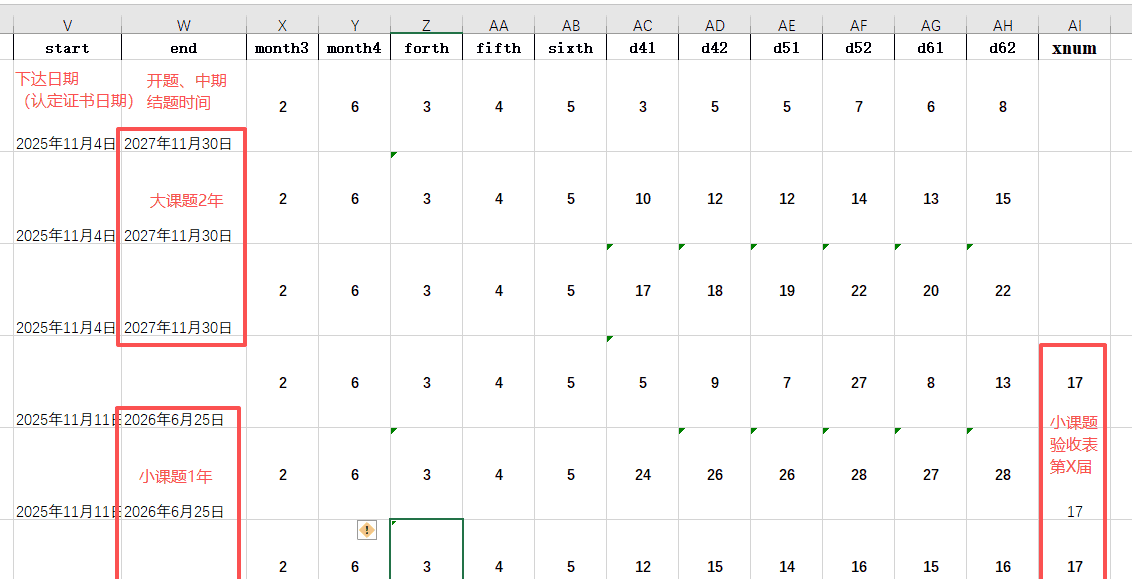
补全新信息
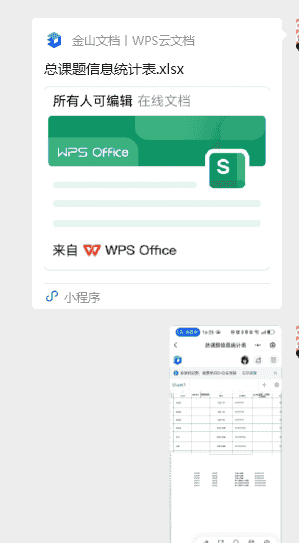
共享文档,请课题负责人写组室成员和组室
填完后下载
三、代码修改
主要修改内容
1、文本占位符修改:部分模版的字母写错。
2、区级一般课题最后加一个“09结题报告“、区级小课题最后加09验收表。
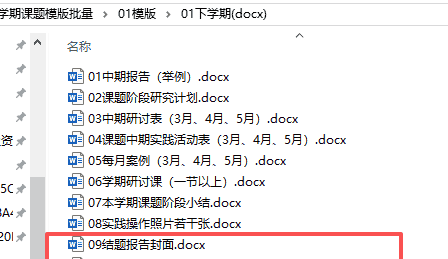
3、验收表需要修改每次的届次“上次是16届, 本次是17届”
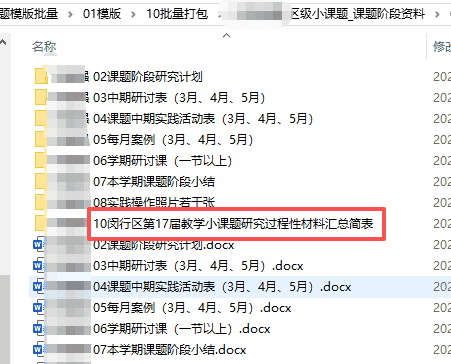
4、把下载的申请书、立项证书,按照文件名的姓名复制到指定的文件夹里


代码展示
为了实现同名的申请书WORD和立项书图片的转移,用豆包写了无数次(将路径都上传,才能让豆包理解意图。)
'''
根据课题组成员名单制作课题阶段资料(上下学期)的个人模版(包含个人的课题信息),
将立项书图片和申请书WORD放入指定文件夹
大课题有结题报告,小课题有验收表
Deepseek、阿夏
2025年11月15日
'''
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
import xlrd
from docx.shared import Inches
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
import shutil
print('----1、第一次新WORD制作--------')
# 基础路径(使用原始字符串避免转义问题)
base_path = r'C:Usersjg2yXRZOneDrive桌面2025111上下学期课题模版批量1模版'
print(f"基础路径: {base_path}")
# 配置参数(集中管理,便于修改)
# 1. 文件源目录(图片和WORD分开存储)
path=r'C:Usersjg2yXRZOneDrive桌面2025111上下学期课题模版批量0立项书图片和表格'
IMG_SOURCE_DIR = path+r'2立项书' # 图片源目录(01立项书文件夹)
WORD_SOURCE_DIR = path+r'1申请书' # WORD源目录(02课题认定书文件夹)
# 2. 目标模版文件名(需与“01x学期(docx)”文件夹中的模版名完全一致)
IMG_TARGET_TPL = '02课题认定书(已下载图片).docx' # 图片对应的模版(01申请书)
WORD_TARGET_TPL = '01课题申请书(已下载WORD).docx' # WORD对应的模版(02认定书)
# 3. 图片尺寸
IMG_WIDTH = Inches(18)
IMG_HEIGHT = Inches(27)
SEMESTERS = ['上', '下'] # 学期列表
def get_target_file(teacher_name, source_dir, file_suffix):
"""根据教师姓名查找指定类型文件(图片/WORD)"""
for file in os.listdir(source_dir):
if teacher_name in file and file.lower().endswith(file_suffix):
return os.path.join(source_dir, file)
return None
def insert_image_to_docx(docx_path, img_path, width, height):
"""将图片插入到docx末尾,居中对齐"""
try:
doc = DocxTemplate(docx_path)
para = doc.docx.add_paragraph() if len(doc.docx.paragraphs) == 0 else doc.docx.paragraphs[-1]
run = para.add_run()
run.add_picture(img_path, width=width, height=height)
para.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save(docx_path)
print(f"✅ 图片插入成功:{os.path.basename(docx_path)}")
return True
except Exception as e:
print(f"❌ 图片插入失败:{str(e)}")
return False
def delete_level3_docx(docx_path, folder_desc):
"""删除3级文件夹内的原docx(标注文件夹类型)"""
try:
if os.path.exists(docx_path) and docx_path.endswith('.docx'):
os.remove(docx_path)
print(f"✅ 已删除{folder_desc}3级文件夹原docx:{os.path.basename(docx_path)}")
return True
except Exception as e:
print(f"❌ 删除{folder_desc}3级文件夹原docx失败:{str(e)}")
return False
def copy_file_to_target_folder(teacher_name, source_dir, target_level3_dir, file_type, folder_desc):
"""
复制文件到对应3级文件夹(01/02分类)
:param folder_desc: 文件夹描述(“01立项书”/“02课题认定书”)
"""
# 定义文件后缀和描述
if file_type == 'img':
suffix = ('.jpg', '.png')
file_type_desc = '图片'
else:
suffix = ('.docx', '.doc')
file_type_desc = 'WORD文件'
# 查找文件
file_path = get_target_file(teacher_name, source_dir, suffix)
if not file_path:
print(f"❌ 未找到{teacher_name}的{file_type_desc}({folder_desc}源目录:{source_dir})")
return False
# 复制到对应3级文件夹
file_dest = os.path.join(target_level3_dir, os.path.basename(file_path))
try:
shutil.copy2(file_path, file_dest)
print(f"✅ {folder_desc}的{file_type_desc}复制成功:{os.path.basename(file_dest)}(存入对应3级文件夹)")
return True
except Exception as e:
print(f"❌ {folder_desc}的{file_type_desc}复制失败:{str(e)}")
return False
# 1. 读取课题信息统计表
excel_path = os.path.join(base_path, '总课题信息统计表.xlsx')
if not os.path.exists(excel_path):
print(f"❌ 课题信息统计表不存在:{excel_path}")
exit()
try:
workbook = xlrd.open_workbook(excel_path)
sheet = workbook.sheet_by_index(0)
print(f"✅ 成功读取统计表,共{sheet.nrows-1}个课题")
except Exception as e:
print(f"❌ 读取统计表失败:{str(e)}")
exit()
# 2. 遍历上下学期处理课题
for semester in SEMESTERS:
print(f"
===== 处理【{semester}学期】=====")
semester_template_dir = os.path.join(base_path, f'01{semester}学期(docx)')
if not os.path.exists(semester_template_dir):
print(f"❌ 学期模版文件夹不存在:{semester_template_dir}")
continue
# 获取所有docx模版
template_files = []
for root, _, files in os.walk(semester_template_dir):
for file in files:
if file.endswith('.docx'):
template_files.append((file, os.path.join(root, file)))
if len(template_files) == 0:
print(f"❌ {semester}学期无docx模版")
continue
print(f"✅ 找到{len(template_files)}个docx模版")
# 3. 遍历每个课题
for row_idx in range(1, sheet.nrows):
row_data = sheet.row_values(row_idx, start_colx=4, end_colx=11)
valid_days = [cell for cell in row_data if cell is not None and str(cell).strip() != '']
print(f"
----- 处理第{row_idx}行课题(有效天数:{len(valid_days)})-----")
# 读取课题核心信息
try:
df = pd.read_excel(excel_path)
project = df.iloc[row_idx-1]
proj_num = project['num']
teacher_name = str(project['name']).strip()
proj_type = str(project['item']).strip()
except Exception as e:
print(f"❌ 读取课题{row_idx}信息失败:{str(e)}")
continue
if teacher_name in ['nan', '']:
print(f"❌ 课题{row_idx}无主持人,跳过")
continue
print(f"课题主持人:{teacher_name}(类型:{proj_type})")
# 4. 遍历每个模版生成文件(分01申请书和02认定书处理)
# 4. 遍历每个模版生成文件(分01申请书和02认定书处理)
for tpl_name, tpl_path in template_files:
print(f"
处理模版:{tpl_name}")
# 小课题跳过指定模版
if proj_type != '区级一般':
if (semester == '上' and tpl_name == '03开题报告(例举).docx') or
(semester == '下' and tpl_name == '01中期报告(举例).docx') or
(semester == '下' and tpl_name == '09结题报告封面.docx') :
print(f"⚠️ 小课题跳过模版:{tpl_name}")
continue
elif proj_type != '区级小课题':
if (semester == '下' and tpl_name == '10闵行区第X届教学小课题研究过程性材料汇总简表.docx') :
print(f"⚠️ 区级一般跳过模版:{tpl_name}")
continue
# 构建上下文(保留原所有变量)
context = {
"num": project['num'],
"title": str(project['title']).strip(),
"name": teacher_name,
"member": str(project['member']).strip(),
"item": proj_type,
"number": str(project['number']).strip(),
"group": str(project['group']).strip(),
"master": str(project['master']).strip(),
"year1": project['year1'],
"month1": project['month1'],
"year2": project['year2'],
"month2": project['month2'],
"first": str(project['first']).strip(),
"second": str(project['second']).strip(),
"third": str(project['third']).strip(),
"d11": str(project['d11']).strip(),
"d12": str(project['d12']).strip(),
"d21": str(project['d21']).strip(),
"d22": str(project['d22']).strip(),
"d31": str(project['d31']).strip(),
"d32": str(project['d32']).strip(),
"start": str(project['start']).strip(),
"end": str(project['end']).strip(),
"month3": project['month3'],
"month4": project['month4'],
"forth": str(project['forth']).strip(),
"fifth": str(project['fifth']).strip(),
"sixth": str(project['sixth']).strip(),
"d41": str(project['d41']).strip(),
"d42": str(project['d42']).strip(),
"d51": str(project['d51']).strip(),
"d52": str(project['d52']).strip(),
"d61": str(project['d61']).strip(),
"d62": str(project['d62']).strip(),
"xnum": str(int(project['xnum'])) if pd.notna(project['xnum']) and isinstance(project['xnum'], (int, float)) else "", # 对应表格中的届数(如17)
}
# -------------------------- 核心修改:同步更新3级文件夹名称 --------------------------
# 1. 动态生成新的模版名(用于文件和文件夹)
if tpl_name == '10闵行区第X届教学小课题研究过程性材料汇总简表.docx':
# 替换“X届”为具体届数(如17届)
new_tpl_name = f'10闵行区第{context["xnum"]}届教学小课题研究过程性材料汇总简表.docx'
# 生成3级文件夹名(教师名 + 新模版名(去掉.docx后缀))
level3_folder_name = f'{teacher_name} {new_tpl_name[:-5]}'
else:
# 其他模版保持原逻辑
new_tpl_name = tpl_name
level3_folder_name = f'{teacher_name} {tpl_name[:-5]}'
# 2. 生成文件夹路径(使用新的3级文件夹名)
project_folder = f"{int(proj_num):02d}{teacher_name}_{proj_type}_课题阶段资料"
level2_dir = os.path.join(base_path, '10批量打包', project_folder, f'01{semester}学期') # 2级:学期文件夹(保留原docx)
level3_dir = os.path.join(level2_dir, level3_folder_name) # 3级:使用新文件夹名
os.makedirs(level3_dir, exist_ok=True)
os.makedirs(level2_dir, exist_ok=True)
# 3. 生成docx路径(使用新文件名)
target_docx_level3 = os.path.join(level3_dir, f'{teacher_name} {new_tpl_name}')
target_docx_level2 = os.path.join(level2_dir, f'{teacher_name} {new_tpl_name}')
# 渲染保存docx(后续逻辑不变)
try:
tpl = DocxTemplate(tpl_path)
tpl.render(context)
tpl.save(target_docx_level3)
tpl.save(target_docx_level2)
print(f"✅ 生成docx:3级文件夹({os.path.basename(target_docx_level3)})、2级文件夹({os.path.basename(target_docx_level2)})")
except Exception as e:
print(f"❌ 生成docx失败:{str(e)}")
continue
# 5. 分模版处理文件存储(01申请书存图片,02认定书存WORD)
# 5.1 处理01课题申请书:复制图片到对应3级文件夹
if tpl_name == IMG_TARGET_TPL:
print(f"
📷 处理{teacher_name}的01课题申请书(需存入图片)")
# 复制图片到01申请书的3级文件夹
img_copy_ok = copy_file_to_target_folder(
teacher_name=teacher_name,
source_dir=IMG_SOURCE_DIR,
target_level3_dir=level3_dir,
file_type='img',
folder_desc="01立项书"
)
# 图片复制成功则删除该文件夹原docx
if img_copy_ok:
delete_level3_docx(target_docx_level3, "01课题申请书")
# 5.2 处理02课题认定书:复制WORD到对应3级文件夹
elif tpl_name == WORD_TARGET_TPL:
print(f"
📄 处理{teacher_name}的02课题认定书(需存入WORD)")
# 复制WORD到02认定书的3级文件夹
word_copy_ok = copy_file_to_target_folder(
teacher_name=teacher_name,
source_dir=WORD_SOURCE_DIR,
target_level3_dir=level3_dir,
file_type='word',
folder_desc="02课题认定书"
)
# WORD复制成功则删除该文件夹原docx
if word_copy_ok:
delete_level3_docx(target_docx_level3, "02课题认定书")
# 6. 批量打包
print(f"
===== 开始打包ZIP ======")
zip_source_dir = os.path.join(base_path, '10批量打包')
zip_target_dir = os.path.join(base_path, '11rar')
os.makedirs(zip_target_dir, exist_ok=True)
if os.path.exists(zip_source_dir):
for folder_name in os.listdir(zip_source_dir):
folder_path = os.path.join(zip_source_dir, folder_name)
if os.path.isdir(folder_path):
zip_path = os.path.join(zip_target_dir, folder_name)
try:
shutil.make_archive(zip_path, 'zip', folder_path)
print(f"✅ 打包成功:{folder_name}.zip")
except Exception as e:
print(f"❌ 打包失败{folder_name}:{str(e)}")
else:
print(f"❌ 打包源文件夹不存在:{zip_source_dir}")
print(f"
===== 所有操作完成!=====")
time.sleep(15)
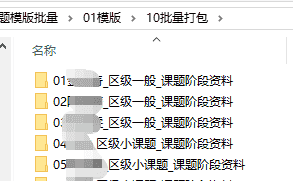
“区级一般课题阶段资料”的内容(有中期报告、开题报告、结题报告)
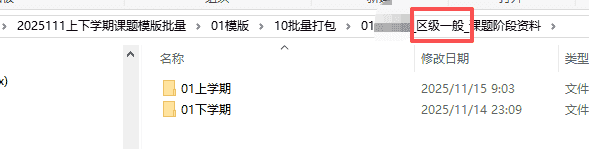
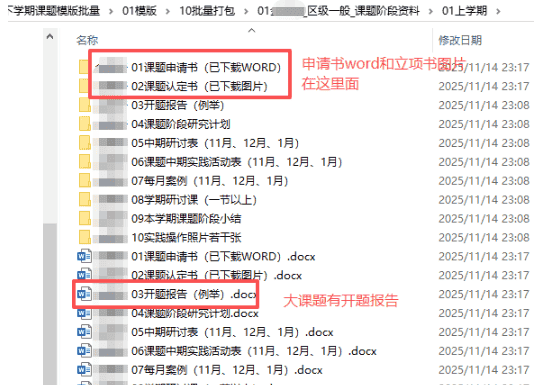
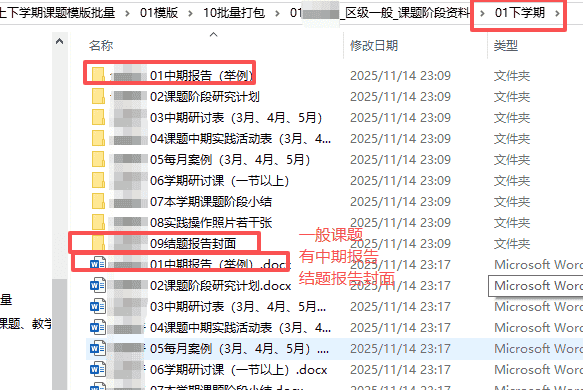
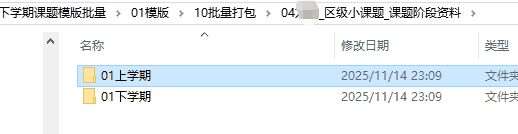
“区级小课题阶段资料”的内容(没有有中期报告、开题报告、结题报告,但有小课题验收表)
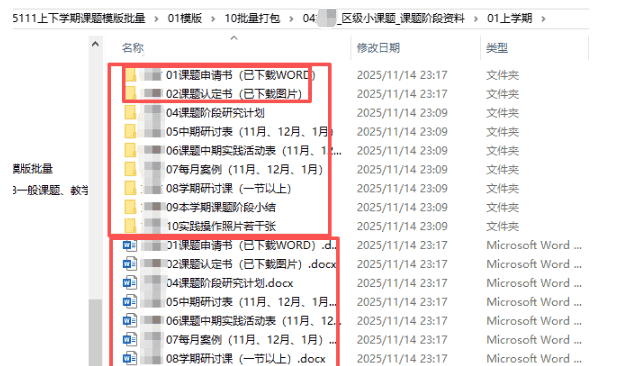
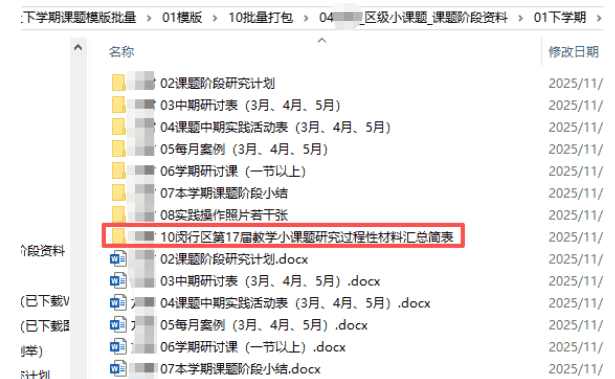
解析:
1、文本占位符,就是把各个WORD模版里面的基本信息,都做成占位符,便于批量写入个人信息


2、通过模版制作,可以提升基本信息的正确性,在1月上学期资料收集、6月下学期资料收集时,检查者就不用为了这些细枝末节的小问题,反复提示负责人修改,毕竟他们只是偶尔做一个课题,不需要去记忆这些小细节的写法。更多的精力应该用在研究实践过程中。
成果应用
在生成文件夹的同时,还做了rar文件,便于发送
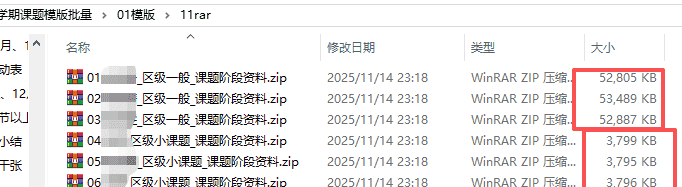
模版的话,文字大小都差不多。
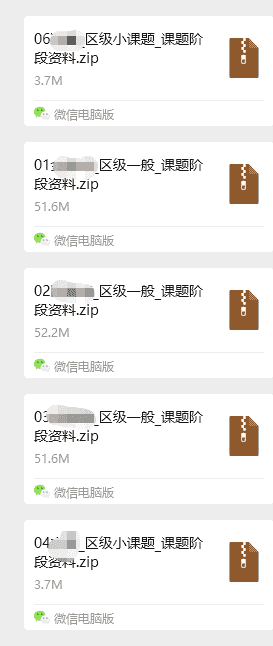
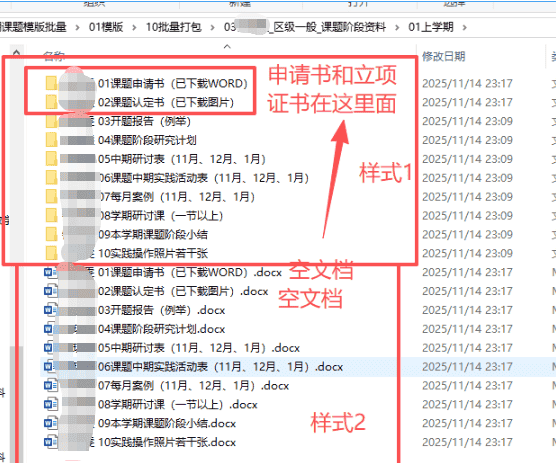

五、后续思考
因为普通老师不怎么想写课题。本次课题都是组长再写,这次的课题资料批量模版很受组长们欢迎。
我希望他们能开发出更多文本占位符的批量需求。让编程更好服务更多教师、幼儿、家长。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











