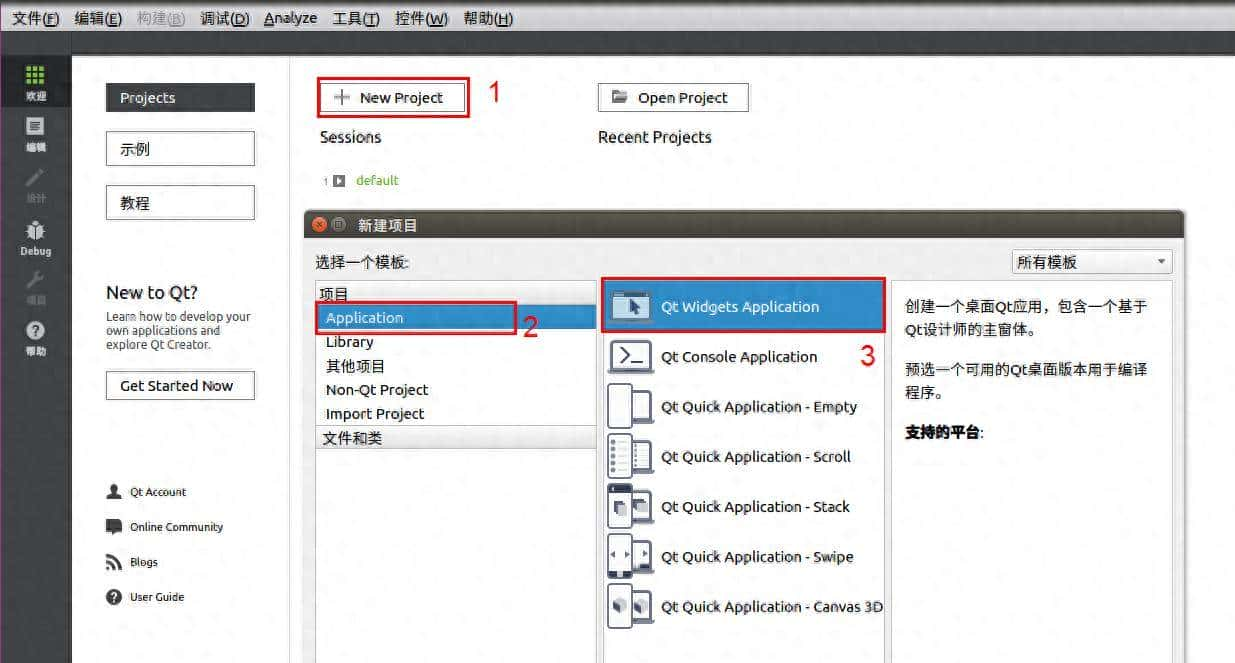
洋码头作为国内知名跨境电商平台,聚焦海外正品直购,商品覆盖美妆护肤、奢侈品、母婴用品等品类,其商品详情数据(如海外直邮信息、关税说明、采购地溯源、版本差异等)对跨境电商比价、正品验证、消费趋势分析等场景具有核心价值。由于平台无公开官方 API,开发者需通过页面解析实现商品详情(
item_get
一、接口基础认知(核心功能与场景)
核心功能洋码头
item_get
item_id
基础信息:商品 ID、标题(含版本 / 规格)、主图(多图)、品牌、类目(如 “美妆个护”“奢侈品包袋”)、详情页 URL价格信息:售价(含税费)、原价、折扣(如 “限时 8 折”)、运费政策(如 “满 299 元包直邮”)、关税说明(是否含税)跨境属性:采购地(如 “美国洛杉矶”)、直邮 / 保税仓标识、物流时效(如 “7-15 天到货”)、报关信息商品特性:规格参数(如 “30ml / 瓶”)、版本说明(如 “美版”“欧版”)、正品认证(如 “品牌授权”“溯源二维码”)交易数据:销量(如 “已售 300+”)、评价数、好评率、库存状态(如 “海外现货”)卖家信息:卖家名称、所在地(如 “美国”)、资质等级(如 “认证买手”)、服务评分
典型应用场景
跨境比价工具:获取 “雅诗兰黛小棕瓶” 的洋码头价格与天猫国际、京东全球购对比,含税费与运费正品验证系统:提取商品采购地、报关信息,验证 “海外直邮” 真实性消费趋势分析:跟踪 “日本面膜” 类目的销量变化、版本偏好(如 “本土版” vs “国际版”)供应链研究:统计某奢侈品品牌的海外采购地分布、物流时效差异
接口特性
跨境专业性:数据包含大量跨境特有字段(采购地、关税、物流时效),需适配海外商品特性非官方性:无公开 API,依赖页面 HTML 解析,动态加载内容多(如库存、实时运费)反爬机制:包含 IP 限制(高频请求封锁)、User-Agent 校验、Cookie 验证(部分价格需登录)、签名参数(动态接口)页面复杂性:详情页嵌套多层 iframe(如商品详情、评价列表),解析难度高于普通电商
二、对接前置准备(环境与 URL 结构)
开发环境
开发语言:Python(推荐,适合快速处理复杂 HTML 与反爬)核心库:
网络请求:
requests
aiohttp
BeautifulSoup
lxml
fake_useragent
proxy_pool
execjs
re
json
商品 ID 与 URL 结构洋码头商品详情页 URL 格式为:
https://www.yangmatou.com/goods/{item_id}.html
item_id
1234567
https://www.yangmatou.com/goods/1234567.html
1234567
页面结构分析通过浏览器开发者工具(F12)分析详情页结构,核心数据位置:
静态数据:标题、主图、基础价格等嵌入主页面 HTML(如
<h1 class="goods-title">
<div class="price-main">
item_id
https://api.yangmatou.com/goods/detail?goodsId={item_id}&sign=xxx
https://detail.yangmatou.com/{item_id}.html
三、接口调用流程(基于页面解析)
以 “获取某进口香水商品详情” 为例,核心流程为URL 构建→主页面解析→iframe 详情提取→动态接口补充→数据结构化:
URL 与请求头构建
目标 URL:
https://www.yangmatou.com/goods/{item_id}.html
item_id
User-Agent
Referer
Cookie
python
运行
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer": "https://www.yangmatou.com/",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Cookie": "user_id=xxx; token=xxx; session_id=xxx" # 登录后从浏览器获取
}主页面静态数据解析从主页面 HTML 中提取基础信息,重点关注跨境特有字段:
| 字段 | 解析方式(CSS 选择器 / XPath) | 示例值 |
|---|---|---|
| 商品标题 | |
“某品牌男士香水 100ml 美版” |
| 主图列表 | |
|
| 售价(含税) | |
“899.00”(元) |
| 原价 | |
“1299.00”(元) |
| 采购地 | |
“美国・纽约” |
| 物流类型 | |
“海外直邮” |
| 卖家名称 | |
“纽约时尚买手” |
iframe 详情页解析(规格参数与详情)商品规格参数、详细介绍常放在独立 iframe 中,需单独请求并解析:
iframe URL 格式:
https://detail.yangmatou.com/{item_id}.html
python
运行
# 请求iframe页面
iframe_url = f"https://detail.yangmatou.com/{item_id}.html"
iframe_html = requests.get(iframe_url, headers=headers).text
iframe_soup = BeautifulSoup(iframe_html, "lxml")
# 提取规格参数(表格形式)
spec_table = iframe_soup.select_one("table.spec-table")
specs = {}
for row in spec_table.select("tr"):
th = row.select_one("th").text.strip()
td = row.select_one("td").text.strip()
specs[th] = td # 如{"规格": "100ml", "版本": "美版", "保质期": "3年"}动态数据补充(AJAX 接口)库存、销量、实时运费等通过带签名的动态接口加载,需破解签名生成逻辑:
库存接口示例:
https://api.yangmatou.com/goods/stock?goodsId={item_id}&sign={sign}
sign
item_id
json
{
"stock": 50, # 总库存
"available": 45, # 可售库存
"salesCount": 320 # 累计销量
}数据整合与结构化合并主页面、iframe、动态接口数据,形成标准化字典,突出跨境特性:
python
运行
standardized_data = {
"item_id": item_id,
"title": title,
"price": {
"current": current_price, # 含税售价
"original": original_price,
"discount": discount, # 折扣信息
"tax_included": True, # 是否含税
"freight": freight # 运费
},
"cross_border": {
"purchase_location": purchase_location, # 采购地
"logistics_type": logistics_type, # 直邮/保税仓
"delivery_time": delivery_time, # 物流时效
"customs_info": customs_info # 报关信息
},
"product": {
"specs": specs, # 规格参数
"version": version, # 版本(如美版)
"expiry_date": expiry_date # 保质期
},
"seller": {
"name": seller_name,
"location": seller_location, # 卖家所在地
"level": seller_level # 资质等级
},
"trade": {
"sales_count": sales_count, # 累计销量
"comment_count": comment_count,
"stock": available_stock
},
"images": image_list,
"url": detail_url
}四、代码实现示例(Python)
以下是
item_get
import requests
import time
import random
import re
import json
import hashlib
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from typing import Dict, List
# 封装好API供应商demo url=https://console.open.onebound.cn/console/?i=Lex
class YangmatouItemApi:
def __init__(self, proxy_pool: List[str] = None, cookie: str = ""):
self.base_url = "https://www.yangmatou.com/goods/{item_id}.html"
self.detail_iframe_url = "https://detail.yangmatou.com/{item_id}.html" # 规格参数iframe
self.stock_api = "https://api.yangmatou.com/goods/stock" # 库存接口
self.freight_api = "https://api.yangmatou.com/goods/freight" # 运费接口
self.ua = UserAgent()
self.proxy_pool = proxy_pool # 代理池列表
self.cookie = cookie # 登录态Cookie
self.secret_key = "xxx" # 从JS逆向获取的签名密钥(需实际破解)
def _get_headers(self) -> Dict[str, str]:
"""生成随机请求头"""
headers = {
"User-Agent": self.ua.random,
"Referer": "https://www.yangmatou.com/",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest" # 动态接口需带此头
}
if self.cookie:
headers["Cookie"] = self.cookie
return headers
def _get_proxy(self) -> Dict[str, str]:
"""随机获取代理"""
if self.proxy_pool and len(self.proxy_pool) > 0:
proxy = random.choice(self.proxy_pool)
return {"http": proxy, "https": proxy}
return None
def _generate_sign(self, params: Dict[str, str]) -> str:
"""生成动态接口签名(需根据实际JS逆向逻辑实现)"""
# 示例:按key排序后拼接+密钥,MD5加密
sorted_params = sorted(params.items(), key=lambda x: x[0])
sign_str = "&".join([f"{k}={v}" for k, v in sorted_params]) + self.secret_key
return hashlib.md5(sign_str.encode()).hexdigest()
def _clean_price(self, price_str: str) -> float:
"""清洗价格字符串"""
if not price_str:
return 0.0
price_str = re.sub(r"[^d.]", "", price_str)
return float(price_str) if price_str else 0.0
def _parse_main_page(self, html: str) -> Dict[str, str]:
"""解析主页面基础信息"""
soup = BeautifulSoup(html, "lxml")
return {
"title": soup.select_one("h1.goods-title")?.text.strip() or "",
"images": [img.get("src") for img in soup.select("div.gallery-main img") if img.get("src")],
"price": {
"current": self._clean_price(soup.select_one("div.price-main .price")?.text or ""),
"original": self._clean_price(soup.select_one("div.price-origin")?.text or "")
},
"cross_border": {
"purchase_location": soup.select_one("div.purchase-location")?.text.strip() or "",
"logistics_type": soup.select_one("div.logistics-type")?.text.strip() or "",
"delivery_time": soup.select_one("div.delivery-time")?.text.strip() or ""
},
"seller": {
"name": soup.select_one("div.seller-name a")?.text.strip() or "",
"location": soup.select_one("div.seller-location")?.text.strip() or "",
"level": soup.select_one("div.seller-level")?.text.strip() or ""
}
}
def _parse_iframe_detail(self, item_id: str, headers: Dict[str, str], proxy: Dict[str, str]) -> Dict[str, str]:
"""解析iframe中的规格参数与详情"""
try:
url = self.detail_iframe_url.format(item_id=item_id)
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
soup = BeautifulSoup(response.text, "lxml")
# 提取规格参数
spec_table = soup.select_one("table.spec-table")
specs = {}
if spec_table:
for row in spec_table.select("tr"):
th = row.select_one("th")
td = row.select_one("td")
if th and td:
specs[th.text.strip()] = td.text.strip()
# 提取版本信息(跨境商品核心)
version = specs.get("版本", "") or re.search(r"[美欧日中]版", soup.text).group() if re.search(r"[美欧日中]版", soup.text) else ""
return {
"specs": specs,
"version": version,
"expiry_date": specs.get("保质期", ""),
"customs_info": soup.select_one("div.customs-info")?.text.strip() or "" # 报关信息
}
except Exception as e:
print(f"iframe详情解析失败: {str(e)}")
return {"specs": {}, "version": "", "expiry_date": "", "customs_info": ""}
def _fetch_dynamic_data(self, item_id: str, headers: Dict[str, str], proxy: Dict[str, str]) -> Dict:
"""调用动态接口获取库存、销量、运费(带签名)"""
dynamic_data = {
"stock": 0, "available": 0, "sales_count": 0,
"comment_count": 0, "freight": 0.0
}
try:
# 1. 获取库存与销量
timestamp = str(int(time.time() * 1000))
stock_params = {
"goodsId": item_id,
"t": timestamp,
"platform": "pc"
}
stock_params["sign"] = self._generate_sign(stock_params)
stock_resp = requests.get(
self.stock_api,
params=stock_params,
headers=headers,
proxies=proxy,
timeout=10
)
stock_data = stock_resp.json()
if stock_data.get("code") == 200:
dynamic_data["stock"] = stock_data["data"].get("stock", 0)
dynamic_data["available"] = stock_data["data"].get("available", 0)
dynamic_data["sales_count"] = stock_data["data"].get("salesCount", 0)
dynamic_data["comment_count"] = stock_data["data"].get("commentCount", 0)
# 2. 获取运费
freight_params = {
"goodsId": item_id,
"t": timestamp,
"addressId": "110000" # 示例:北京地址ID,影响运费计算
}
freight_params["sign"] = self._generate_sign(freight_params)
freight_resp = requests.get(
self.freight_api,
params=freight_params,
headers=headers,
proxies=proxy,
timeout=10
)
freight_data = freight_resp.json()
if freight_data.get("code") == 200:
dynamic_data["freight"] = freight_data["data"].get("amount", 0.0)
except Exception as e:
print(f"动态数据获取失败: {str(e)}")
return dynamic_data
def item_get(self, item_id: str, timeout: int = 10) -> Dict:
"""
获取洋码头商品详情
:param item_id: 商品ID(如1234567)
:param timeout: 超时时间
:return: 标准化商品数据
"""
try:
# 1. 主页面请求
url = self.base_url.format(item_id=item_id)
headers = self._get_headers()
proxy = self._get_proxy()
time.sleep(random.uniform(2, 4)) # 随机延迟
response = requests.get(
url=url,
headers=headers,
proxies=proxy,
timeout=timeout
)
response.raise_for_status()
main_html = response.text
# 2. 解析主页面数据
main_data = self._parse_main_page(main_html)
if not main_data["title"]:
return {"success": False, "error_msg": "商品不存在或已下架"}
# 3. 解析iframe详情
iframe_data = self._parse_iframe_detail(item_id, headers, proxy)
# 4. 获取动态数据(库存、运费等)
dynamic_data = self._fetch_dynamic_data(item_id, headers, proxy)
# 5. 整合结果
result = {
"success": True,
"data": {
"item_id": item_id,** main_data,
"product": {
"specs": iframe_data["specs"],
"version": iframe_data["version"],
"expiry_date": iframe_data["expiry_date"]
},
"cross_border": {
**main_data["cross_border"],
"customs_info": iframe_data["customs_info"]
},
"price": {** main_data["price"],
"tax_included": "含税" in (main_html or ""), # 从页面判断是否含税
"freight": dynamic_data["freight"]
},
"trade": {
"sales_count": dynamic_data["sales_count"],
"comment_count": dynamic_data["comment_count"],
"stock": dynamic_data["available"]
},
"update_time": time.strftime("%Y-%m-%d %H:%M:%S")
}
}
return result
except requests.exceptions.HTTPError as e:
if "403" in str(e):
return {"success": False, "error_msg": "IP被封或签名失效,建议更换代理并重试", "code": 403}
return {"success": False, "error_msg": f"HTTP错误: {str(e)}", "code": response.status_code}
except Exception as e:
return {"success": False, "error_msg": f"获取失败: {str(e)}", "code": -1}
# 封装好API供应商demo url=https://console.open.onebound.cn/console/?i=Lex
# 使用示例
if __name__ == "__main__":
# 代理池(替换为有效代理)
PROXIES = [
"http://123.45.67.89:8888",
"http://98.76.54.32:8080"
]
# 登录态Cookie(从浏览器获取)
COOKIE = "user_id=xxx; token=xxx; session_id=xxx"
# 初始化API客户端(需补充secret_key,通过JS逆向获取)
api = YangmatouItemApi(proxy_pool=PROXIES, cookie=COOKIE)
# 获取商品详情(示例item_id)
item_id = "1234567" # 替换为实际商品ID
result = api.item_get(item_id)
if result["success"]:
data = result["data"]
print(f"商品标题: {data['title']}")
print(f"价格: ¥{data['price']['current']}({'含税' if data['price']['tax_included'] else '不含税'}) | 运费: ¥{data['price']['freight']} | 原价: ¥{data['price']['original']}")
print(f"跨境信息: {data['cross_border']['logistics_type']} | 采购地: {data['cross_border']['purchase_location']} | 时效: {data['cross_border']['delivery_time']}")
print(f"规格版本: {data['product']['version']} | {', '.join([f'{k}:{v}' for k, v in list(data['product']['specs'].items())[:3]])}")
print(f"卖家信息: {data['seller']['name']}({data['seller']['location']} | 等级: {data['seller']['level']})")
print(f"交易数据: 销量{data['trade']['sales_count']}件 | 评价{data['trade']['comment_count']}条 | 库存{data['trade']['stock']}件")
else:
print(f"获取失败: {result['error_msg']}(错误码: {result.get('code')})")五、关键技术难点与解决方案
动态签名参数破解(核心难点)
问题:洋码头动态接口(库存、运费)需携带
sign
逆向 JS 代码:通过浏览器开发者工具(Sources 面板)定位生成
sign
_generate_sign
iframe 嵌套内容解析
问题:商品规格参数、详情图文常放在独立 iframe 中,主页面 HTML 不包含这些数据,直接解析会导致信息缺失。解决方案:
从主页面提取 iframe 的
src
https://detail.yangmatou.com/1234567.html
_parse_iframe_detail
跨境特有字段提取(采购地、版本)
问题:采购地(如 “美国・纽约”)、版本(如 “美版”)是跨境商品的核心标识,但文本格式多样,提取难度大。解决方案:
采购地通过
div.purchase-location
specs.get("版本")
反爬机制对抗
问题:洋码头对跨境数据保护严格,反爬机制包括 IP 封锁、签名验证、Cookie 时效限制、请求频率监控。解决方案:
代理 IP 策略:使用高匿代理池(优先选择海外节点,模拟真实采购场景),每 2 次请求切换 IP;请求频率控制:单 IP 每分钟请求≤1 次,两次请求间隔 4-6 秒(跨境商品浏览决策周期较长);Cookie 轮换:维护多个登录态 Cookie(通过不同账号获取),随机携带以降低单一账号风险;异常重试:对 403 错误,延迟 10 秒后用新代理 + 新签名重试,最多 3 次。
六、最佳实践与合规要点
系统架构设计采用 “低频率、高稳定性” 架构,适配跨境电商特性:
采集层:集成代理池(含海外节点)、Cookie 池、签名生成服务,控制单 IP 请求频率(≤1 次 / 分钟);解析层:分离主页面、iframe、动态接口解析逻辑,重点处理签名参数与跨境字段;存储层:用 Redis 缓存热门商品(4 小时过期,跨境商品价格波动较慢),MySQL 存储历史数据(用于正品溯源分析);监控层:实时监控签名有效性、代理存活率,异常时自动切换密钥与代理池。
性能优化策略
异步批量获取:使用
aiohttp
item_id
合规性与风险控制
访问限制:单 IP 日请求量≤100 次,避免对平台服务器造成压力,符合跨境电商数据采集规范;数据使用边界:不得将数据用于虚假宣传、恶意比价或侵犯品牌知识产权,需注明数据来源 “洋码头”;法律风险规避:跨境商品数据涉及关税、报关信息,使用时需遵守《海关法》《电子商务法》等法规,不得篡改溯源信息。
七、总结
洋码头
item_get
签名生成逻辑的逆向与复现(确保动态接口可调用);多页面(主页面 + iframe)数据的协同整合(避免信息缺失);低频率、高匿代理的策略(应对严格反爬)。
通过本文的技术方案,可构建稳定的跨境商品详情获取系统,为跨境比价、正品验证等场景提供可靠数据支持。实际应用中,需根据平台最新反爬机制动态调整签名逻辑与代理策略,平衡数据获取效率与合规性
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











