【浅谈】如何优雅的使用AI辅助代码工具—使用统一规范及自动更新规范机制来提升个人及团队效率(二)
AI辅助代码书写工具规范文件文档系列文章相关项目AI辅助开发项目自我规范及自我进化如何使用规范框架来开发其他项目项目规范规则说明及使用写在后面
规则优先级说明优先级分级🔴 高优先级规则(必须遵守)项目公用规则Git相关规则编译器/IDE报错处理核心技术规范
🟡 中优先级规则(冲突时参考)代码书写格式规则Autotest规则(流程部分)代码语法规范
🟢 低优先级规则(参考使用)一般性建议和规范工具配置建议
冲突处理原则优先级层次表具体冲突解决规则特殊场景处理
项目规则详细说明1、项目代码修改规则autotest规则:高优先级规范(必须遵守)中优先级规范(测试流程)
临时文件管理规则:高优先级规范(必须遵守)🔴 高优先级规范(文件名命名规范规则)中优先级规范(目录结构整理)
文件路径使用规则:高优先级规范(必须遵守)
文件路径下代码编辑规则:高优先级规范(必须遵守)中优先级规范(Git提交流程)
特殊配置文件管理规则:高优先级规范(必须遵守)中优先级规范(配置管理)
全局变量规则(下载域名管理):高优先级规范(必须遵守)
文本版本控制规则(不依赖git):高优先级规范(必须遵守)
数据库配置管理规则(基于db_lists.txt):高优先级规范(必须遵守)中优先级规范(版本管理)
Git提交远程仓库前公用规则:高优先级规范(必须遵守)中优先级规范(仓库同步)
语法规范自动调整公用规则:高优先级规范(必须遵守)
WSL2纯净开发环境规则:高优先级规范(必须遵守)中优先级规范(配置详情)
规则优先级漏洞逻辑自动调整规则:高优先级规范(必须遵守)
规则优先级冲突与逻辑漏洞分析报告发现的问题1. 规则优先级分级不合理2. 冲突处理原则逻辑矛盾3. 规则间隐式依赖关系4. 规则文件自身不符合规则要求
解决方案建议1. 规则重新分类2. 修正标记问题3. 优化冲突处理原则4. 完善规则间依赖关系5. 应用规则优先级漏洞逻辑自动调整规则
项目全局规则配置1. 容器仓库配置规则 (register-docker-login)配置模式重要说明
2. 开发容器初始化工具 (build-image-tools)工具列表及说明安装规则工具详情
3. PortainerEE安装配置 (portainerEE-Compose)触发条件配置文件路径环境变量
4. 规则管理器 (rules_manager.py)功能说明使用方法主要方法
在项目中启用私有规则选择性使用全局规范测试覆盖范围
冲突检测与优化说明合并结果逻辑一致性检查后续维护
代码语法规范编写shell脚本,应该遵循Google Shell编码风格指南:编写Python代码,应该遵循大厂Python编码风格规范:编写C语言代码,应该遵循华为C语言编程规范:编写Rust代码,应该遵循企业级编程规范:编写Go代码,应该遵循官方编码规范与最佳实践:编写C++代码,应该遵循Google C++风格指南:Unity游戏Mod开发规范编写JavaScript代码,应该遵循Google JavaScript风格指南:编写HTML/CSS代码,应该遵循Google HTML/CSS风格指南:Markdown文档写作规范:CSDN技术博客写作规范:CSDN技术博客md文件管理规则:编写Java代码,应该遵循Google Java风格指南:日志记录规范及最佳实践:
规则文件状态管理文件锁定机制远程规则模式本地规则模式模式切换规则状态文件管理规则规范文件备份机制
项目变量管理规则(project_vars.txt)变量登记规范当前项目变量定义变量使用规范
README文件规范README文件要求
文档指南文件规范文档存放位置文档更新机制路径变量注册
AI辅助代码书写工具规范文件文档
系列文章
【浅谈】如何优雅的使用AI辅助代码工具—使用统一规范及自动更新规范机制来提升个人及团队效率(一)
【浅谈】如何优雅的使用AI辅助代码工具—使用统一规范及自动更新规范机制来提升个人及团队效率(二)
【浅谈】如何优雅的使用AI辅助代码工具—使用统一规范及自动更新规范机制来提升个人及团队效率(完)
相关项目
https://github.com/aspnmy/ai_project_rules.git规则文件直接地址:https://raw.githubusercontent.com/aspnmy/ai_project_rules/refs/heads/master/project_rules.md如果对我的这套AI辅助代码统一规范有兴趣的,只需要
curl -sSL https://raw.githubusercontent.com/aspnmy/ai_project_rules/refs/heads/master/project_rules.md
到本地AI-IDE的规则目录下即可,无需git仓库如果要完整品尝–AI辅助代码书写工具规范文件–形成的自动化辅助开发框架,则需要拉取整个仓库:
git clone -b devAIFramework https://github.com/aspnmy/ai_project_rules.git
AI辅助开发项目自我规范及自我进化
这个项目本身就是使用这个规范文件自动化构建的,和AI沟通过程中一般就这样 :
human:继续完善规则 README.md规则,如果路径下有子路径 需要递归的按照 README.md规则要求执行 更新规范文件 并检查工作区是否满足新规范
AI:根据用户要求,需要继续完善README.md规则并递归检查所有子目录。我将创建一个todo列表来组织这项任务,确保全面覆盖所有要求。
AI:创建递归检查和更新README.md的任务列表
AI:更新project_rules.md以包含递归检查README.md的规范要求
AI:递归检查所有子目录,为缺少README.md和README_En.md的目录创建文件
AI:检查整个工作区是否符合新规范并修复问题
AI:更新project_vars.txt以记录所有新创建的README文件路径
AI:更新project_rules.md文件,我将再一次检查工作区路径结构是否满足新的project_rules.md文件规范的要求…

如何使用规范框架来开发其他项目
首先更新rulesmyproject_rulesmyproject_rules.txt文件,按照里面的内容填写必要的参数然后在AI聊天框中,这样发送指令
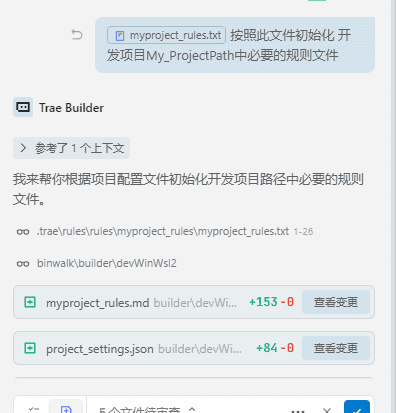 然后AI工具就会给被开发的项目新增必要的配置文件如果要对开发项目进行规范的时候,只需要这样对AI说
然后AI工具就会给被开发的项目新增必要的配置文件如果要对开发项目进行规范的时候,只需要这样对AI说
human:对myproject进行合规性检查
AI:根据您的规则我现在开始新建todo进行规划检查
私有项目规则和框架项目规则直接如何选择查看
.trae
ules
ulesmyproject_rulesmyproject_rules.txt中的参数配置
# 这是常用默认值
# 是否执行全局规范的绝对性(true/false)
My_UseGlobalRules|project_var|"false"
# 代码规范遵循配置 (true/false)
My_UseGlobalCodeSpec|project_var|"true"
# 路径结构遵循全局规范 (true/false)
My_UseGlobalPathSpec|project_var|"true"
# 文档规则遵循全局规范 (true/false)
My_UseGlobalDocSpec|project_var|"false"
# README规则遵循全局规范 (true/false)
My_UseGlobalReadmeSpec|project_var|"true"
项目规范规则说明及使用
每次更新规范文件后,需要告诉AI,检查规范文件的优先度是否有冲突和漏洞,如果有则生成详细检测报告,添加TODO标志为了应对AI降智的问题,把任务拆分处理,比如让AI执行缺陷检查,把报告记录再todo_rules_lists.txt下,然后再让AI对todo_rules_lists.txt中的任务清单进行规划执行,执行成功的标注成成功,没有执行成功的继续保留TODO,然后更新到规范文件中,如下方这样:

写在后面
学习使用AI辅助规范非常有意思,这个规范可以适合大多数能自行执行代码逻辑的辅助模型,通过和AI对话过程中理解逻辑树的趣味性,真是非常有意思的事情本规范中特别有一个CSDN博客规范,这个是一个小功能组件目的是自动编写博客文件,而不是现在这种精炼的一看就是AI写的md文档风格按照csdn规范的要求,当AI对每个递归的子路径中生成README.md后,执行csdn博客规范,模拟人类对里面的内容进行扩写,变成一个对人类更友好的csdn_md,然后方便我进行发布,不过这个部分的规则还没完全设置好,所以两个docs.md和csdn.md风格完全一样,一看就是AI写的。狗头狗头狗头
————下面是规则文件的本身说明(此文件后续还好持续自我优化)
规则优先级说明
优先级分级
🔴 高优先级规则(必须遵守)
项目公用规则
除代码规范外的所有用户要求增加的规则适用于整个项目的通用性规则Git提交远程仓库前公用规则(代码检查、默认仓库配置)语法规范自动调整公用规则(IDE规范优先、版本管理)规则优先级漏洞逻辑自动调整规则(漏洞检查、冲突处理)
Git相关规则
涉及git提交、清理中间文件、非git依赖文件版本控制、文件更名规范等版本控制和代码管理相关规则
编译器/IDE报错处理
语法错误:必须立即修复,优先级高于所有其他规则编译错误:必须解决,优先级高于代码规范代码风格警告:遵循代码书写格式规则(中优先级)静态分析建议:参考使用,遵循一般性建议(低优先级)
核心技术规范
字符编码规范(UTF-8、BOM头等)文件路径规范(相对路径要求)安全相关规范(禁止SUID/SGID等)
🟡 中优先级规则(冲突时参考)
代码书写格式规则
项目风格一致性要求优先级顺序:项目既定风格 > IDE风格建议 > 通用代码规范说明:当IDE风格建议与项目既定风格冲突时,必须保持项目风格一致性
Autotest规则(流程部分)
测试流程规范、测试用例设计技术规范部分(编码、文件格式)提升至高优先级文件命名冲突时,以语法规范要求为准
代码语法规范
各编程语言的具体语法要求命名约定、格式要求等
🟢 低优先级规则(参考使用)
一般性建议和规范
最佳实践建议和优化建议代码可读性建议性能优化建议
工具配置建议
推荐工具配置非强制性规范要求
冲突处理原则
优先级层次表
| 层次 | 规则类型 | 处理原则 |
|---|---|---|
| 最高 | IDE语法/编译错误(不包括风格建议) | 必须立即修复 |
| 高 | 项目公用规则、Git规则、核心技术规范、项目风格规范 | 必须遵守 |
| 中 | 代码格式、语法规范、测试流程 | 冲突时参考,可协商调整 |
| 低 | 一般性建议、工具配置、IDE风格建议 | 参考使用,灵活处理 |
具体冲突解决规则
| 冲突类型 | 处理原则 | 依据优先级 |
|---|---|---|
| IDE语法错误 vs 任何规则 | 修复语法错误 | 最高 |
| IDE编译错误 vs 代码规范 | 解决编译错误 | 最高 |
| IDE风格警告 vs 代码格式规则 | 遵循代码格式规则 | 中 |
| 公用规则 vs 代码规范 | 公用规则优先 | 高 |
| Git规则 vs 文本版本控制 | Git规则优先 | 高 |
| Autotest技术规范 vs 语法规范 | 技术规范优先 | 高 |
| Autotest流程 vs 测试相关语法规范 | 语法规范优先 | 中 |
| 具体规则 vs 通用规则 | 具体规则优先 | 按层次确定 |
| IDE规范 vs 语法规范 | 语法规范优先 | 高(项目风格一致性要求) |
| 规则更新 vs 现有规则 | 先检查漏洞再更新 | 高(规则优先级漏洞逻辑自动调整规则) |
特殊场景处理
紧急修复场景:允许临时违反中低优先级规则,但需添加TODO注释用户明确要求:用户明确指定的规则修改要求优先级高于对应层次的默认规则规则更新:新添加的规则默认继承其分类的优先级,特殊情况单独标注
项目规则详细说明
1、项目代码修改规则
所有项目代码修改,必须先提交到git仓库,然后再进行修改。当需要修改的代码本身是适用于所有平台的时,直接修改即可。当项目代码本身是适配linux系统时,需要修改代码了独立支持win或者macOS时,必须先提交当前未修改前的版本到git仓库,然后再新建新分支,命名规则如下 dev-platform,例如 dev-win,然后再进行修改;如果只是简单的修改,例如修改文件路径,那么可以直接在master分支上修改;如果需要修改的分支是master或者main分支,需要先把本地的提交新建一个分支,然后从远程拉取master或main分支最后个版本代码;第三步再以主分支建立dev-platform分支然后再进行修改。严禁直接对master或main分支进行直接修改
autotest规则:
高优先级规范(必须遵守)
技术规范要求:
日志文件必须使用utf-8编码,且必须在文件开头包含BOM头(字节顺序标记)🔴日志文件命名必须满足”临时文件管理规则”中关于temp-${filename}的命名规范🔴测试脚本必须支持跨平台兼容性(Windows、macOS、Linux)🔴
中优先级规范(测试流程)
每次编写代码以后,配套编写一个autotest脚本,用于测试代码的正确性。特别是代码中包含用户条件选择的部分,需要测试不同的选择情况。例如:
测试用户输入不同的选项,验证脚本是否按照预期执行。测试用户输入无效的选项,验证脚本是否能够正确处理错误情况。测试用户输入空值,验证脚本是否能够正确处理边界情况。测试用户输入特殊字符,验证脚本是否能够正确处理特殊情况。测试用户输入非预期的输入,验证脚本是否能够正确处理异常情况。测试脚本在不同操作系统上的兼容性,例如Windows、macOS和Linux。每个测试用例都应该有一个唯一的名称,用于标识测试的具体场景。测试用例应该覆盖脚本的所有主要功能和边界情况。测试用例应该是可重复执行的,确保每次运行结果一致。测试用例应该在不同的时间点和环境下执行,以模拟真实的使用场景。每个测试步骤都要用输出日志记录,包括用户输入、脚本执行结果和预期结果。测试用例应该包含必要的前置条件,例如创建测试文件、设置环境变量等。autotest脚本输出的日志文件要和测试用例的名称保持一致,例如 test1.log, test2.log 等。每个测试用例的日志文件,都要包含测试用例的名称、测试步骤、用户输入、脚本执行结果和预期结果等信息。
临时文件管理规则:
高优先级规范(必须遵守)
命名规范:
因自动化指令没有人工确认而新增的正式文件备份文件,必须使用 temp-${filename} 前缀命名🔴例如:install-wsl2.py 的临时备份文件应命名为 temp-install-wsl2.py🔴 版本控制:
严禁将temp-前缀的临时文件提交到版本控制系统🔴调试完成更新到主文件或提交git到远程仓库前,必须清理掉temp-前缀的临时文件🔴
🔴 高优先级规范(文件名命名规范规则)
${PG_RuleFileName}唯一规则:
${PG_RuleFileName}的路径必须是rulesproject_vars.txt注册的值🔴文件后缀必须为md,以便于和其他次级rule的txt文件进行区别🔴只有次级rule才使用txt文件格式🔴此为唯一一条文件名命名规范规则,不可修改🔴
中优先级规范(目录结构整理)
定期目录整理:
根据工作区功能使用要求,把rules有关的规则文件更名成txt后缀,然后存放在rules目录下🟡和规则中相关联的脚本、功能应用存放在Util目录下🟡log文件存放在Logs目录下🟡文档类文件(除README外的.md文件)存放在docs目录🟡WSL相关配置文件存放在wsl_config目录🟡 目录结构规范:
根目录:只存放主规则文件project_rules.md、README文件和必要的配置文件🟡rules目录:存放所有次级规则文件(.txt格式)、变量定义文件和规则备份文件🟡Util目录:存放所有功能脚本,按功能分类存放🟡Logs目录:存放所有日志文件🟡db_config/db_config_secure目录:存放数据库配置文件🟡docs目录:存放所有文档类文件(除README外的.md文件)🟡wsl_config目录:存放WSL相关配置文件🟡scripts目录:存放所有脚本文件(.bat、.sh、.py等)🟡docker目录:存放所有Docker相关配置和脚本🟡installers目录:存放所有安装相关脚本🟡 特殊文件存放:
gateway类文件(download-gateway、dockerimage-gateway等)应该存放在scripts目录🟡Compose配置文件(portainerEE-Compose)应该存放在docker目录🟡安装和配置脚本(install_.bat/sh、setup_.bat)应该存放在installers目录🟡 硬编码路径检查:
梳理完目录格式后,检查所有的功能脚本是否有硬编码的路径代码🟡如果存在硬编码路径,则把此路径注册到PG_ProjectVarName中🟡确保所有路径都通过环境变量或配置文件管理🟡 Todo列表管理:
不符合规范的文件应该生成todo列表🟡Todo列表应该存放在rules/todo_rules_lists.txt文件中🟡每次执行规范文件检测后生成的报告应该存放在todo_rules_lists.txt中🟡规范文件中只需要记录todo_rules_lists.txt的路径变量🟡
文件路径使用规则:
高优先级规范(必须遵守)
路径规范:
所有涉及文件调用的代码,无论是什么操作系统,都必须使用相对路径🔴必须在代码中获取本文件所在路径作为基点,来加载上级文件或下级文件🔴禁止使用绝对路径加载任何资源文件🔴 示例代码模式:
import os
current_dir = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(current_dir, 'config', 'settings.json')
文件路径下代码编辑规则:
高优先级规范(必须遵守)
文件管理:
在每个路径下编辑代码时,必须在此路径下新增一个rules/files_rules.md文件🔴files_rules.md文件用于记录项目生成的正式代码文件、库文件的相对路径🔴 文件格式规范:
[生产代码]
true-${filename}-${platform}-${version}-${num+1}
[临时生成]
temp-${filename}-${platform}-${version}-${num+1}
[测试代码]
test-${filename}-${platform}-${version}-${num+1}
autotest--${filename}-${platform}-${version}-${num+1}
中优先级规范(Git提交流程)
提交前清理:
提交git远程仓库前,必须先将[生产代码]下的所有true-
f
i
l
e
n
a
m
e
更新成
{filename}更新成
filename更新成{filename}🟡清理[临时生成]下面所有的temp-${filename},再进行同步🟡rules/files_rules.md文件也需要同步更新,删除所有temp-
f
i
l
e
n
a
m
e
和
t
e
s
t
−
{filename}和test-
filename和test−{filename},并更新[生产代码]下的
f
i
l
e
n
a
m
e
,保持与
[
生产代码
]
下的
{filename},保持与[生产代码]下的
filename,保持与[生产代码]下的{filename}一致🟡 工作区功能复用性检查:
当用户要求清理、整理工作区或提交版本控制时,检查test-、test_、debug-、debug_前缀文件的功能复用性🟡评估这些文件是否包含可复用的功能模块或工具函数🟡如果文件具有复用价值,按照命名规范进行更名,避免直接删除🟡 全面清理:
如果用户指令是iscleanfull或全面清理,必须全部清除[临时生成]和[测试代码]下面的文件🟡
特殊配置文件管理规则:
高优先级规范(必须遵守)
配置文件分类:
所有数据库配置文件必须存放在db_config/或db_config_secure/目录下🔴环境变量配置模板必须以.json.example为后缀🔴安全敏感的配置文件必须存放在db_config_secure/目录下🔴 配置文件命名:
配置文件必须使用描述性名称,清晰反映其用途🔴同一类型的配置文件使用统一的命名前缀🔴
中优先级规范(配置管理)
配置文件版本控制:
敏感配置文件不应直接提交到版本控制系统🟡应提供示例配置文件(如registerConfig.json.example)供参考🟡实际配置文件应通过环境变量或本地配置管理🟡 配置文件格式:
推荐使用JSON格式存储配置信息🟡配置文件应包含必要的注释说明🟡
全局变量规则(下载域名管理):
高优先级规范(必须遵守)
下载网关域名管理:
download-gateway
dockerimage-gateway
域名使用规则:
文件下载URL:
https://${download-gateway}/xxx/xxx/xxx
https://${dockerimage-gateway}/xxx/xxx/xxx
环境变量设置:
脚本运行时必须设置
DOWNLOAD_GATEWAY
DOCKERIMAGE_GATEWAY
使用示例:
下载文件:
https://${DOWNLOAD_GATEWAY}/files/tool.zip
https://gateway.cf.shdrr.org/files/tool.zip
${DOCKERIMAGE_GATEWAY}/windows:latest
drrpull.shdrr.org/windows:latest
$DOWNLOAD_GATEWAY
$DOCKERIMAGE_GATEWAY
文本版本控制规则(不依赖git):
高优先级规范(必须遵守)
版本控制机制:
启用简单的文本版本控制机制,使用**-
f
i
l
e
n
a
m
e
−
d
{filename}-d
filename−d{num+1}格式进行版本管理🔴 文件命名规则:
首次编辑文件:**-${filename}-d1(基础版本)🔴后续完全不同业务方向:**-
f
i
l
e
n
a
m
e
−
d
2
、
∗
∗
−
{filename}-d2、**-
filename−d2、∗∗−{filename}-d3等,依次递增🔴关联性功能扩展:使用temp-${filename}临时文件🔴
数据库配置管理规则(基于db_lists.txt):
高优先级规范(必须遵守)
db_lists.txt 文件格式:
格式:
mcp_server:${mcp_server_name}|${system_path_var}
mcp_server:filesystem|DB_PATH_CONFIG
环境变量管理:
使用 set_SystemPathVar.py 工具安全设置数据库路径环境变量🔴环境变量值必须指向实际存在的数据库文件或目录🔴禁止使用硬编码的绝对路径,必须通过环境变量引用🔴
MCP 服务器配置:
使用 db_lists_parser.py 解析 db_lists.txt 文件🔴使用 db_filesystem_manager.py 生成 MCP 服务器配置🔴配置文件必须包含在 db_config/ 目录中🔴
配置验证:
使用 check_project_config.py 工具验证项目配置完整性🔴必须验证环境变量设置、路径存在性、MCP配置有效性🔴所有配置必须在项目使用前通过验证检查🔴
安全要求:
环境变量名称必须足够复杂,避免与其他系统变量冲突🔴数据库文件路径必须设置适当的访问权限🔴禁止在代码中暴露实际的数据库文件路径🔴
工具使用流程:
编辑 db_lists.txt 添加 MCP 服务器配置🔴运行 set_SystemPathVar.py 设置环境变量🔴运行 db_lists_parser.py 验证配置格式🔴运行 db_filesystem_manager.py 生成 MCP 配置🔴运行 check_project_config.py 验证项目配置🔴
错误处理:
如果环境变量未设置,必须提供清晰的错误提示和修复步骤🔴如果路径不存在,必须提供创建路径的指导🔴如果配置格式错误,必须提供格式修正建议🔴
中优先级规范(版本管理)
版本用途规范:
**-${filename}-d1:开发Windows系统下执行业务的代码🟡**-${filename}-d2:开发Debian系统下执行业务的代码(完全不同方向)🟡temp-
f
i
l
e
n
a
m
e
:与
∗
∗
−
{filename}:与**-
filename:与∗∗−{filename}-d1有关联性的功能扩展🟡 文件合并规则:
temp-
f
i
l
e
n
a
m
e
测试通过后,必须合并回对应的
∗
∗
−
{filename}测试通过后,必须合并回对应的**-
filename测试通过后,必须合并回对应的∗∗−{filename}-d1中🟡确保代码复用,避免已存在代码被浪费🟡 适用范围:此规则在[生产代码]、[临时生成]、[测试代码]中全面启用🟡清理规则:用户未给出清理指令或提交git远程仓库前,**-
f
i
l
e
n
a
m
e
−
d
{filename}-d
filename−d{num}文件应予以保留🟡
Git提交远程仓库前公用规则:
高优先级规范(必须遵守)
代码检查规范:
同步代码到远程仓库前,必须先按照规则文件中的语法规范对代码进行检查🔴如果IDE报错,以IDE优化建议为准进行修正🔴检查并修正后,再进行同步到远程仓库🔴 默认仓库配置:
用户没有输入”同步私有库”指令前,默认只提交到github🔴默认新发布的仓库为私有仓库🔴
中优先级规范(仓库同步)
私有库同步规则:
用户输入指令”同步私有库”,则提交到私有库中🟡如果私有库中已经存在同名仓库就更新🟡如果分支名不一致则新建分支🟡如果私有库中不存在同名仓库则发布🟡私有库默认全部发布为私有仓库🟡
语法规范自动调整公用规则:
高优先级规范(必须遵守)
IDE规范优先:
如果编写代码中IDE提示规范高于目前语法规范,按IDE要求修改代码规范🔴修改后需要同步修改目前的语法规范🔴 版本管理:
考虑到语法版本的问题,在修改语法规范时需要表明此语法修改对应的版本号🔴
WSL2纯净开发环境规则:
高优先级规范(必须遵守)
环境配置:
开发环境系统版本:${wsl-distro} '.wsl-distro.info’🔴
${wsl-distro}变量值从
.wsl-distro.info
win11
win11l
win7u
win2025
podman-win-wsl2
w
s
l
−
d
e
v
p
a
t
h
′
{wsl-devpath} '
wsl−devpath′HOMEgit_data${gitbranch}'🔴
Windows容器环境:
c:\${wsl-usr}\git_data\${gitbranch}
${HOME}/git_data/${gitbranch}
中优先级规范(配置详情)
容器配置:
容器默认端口:RDP(4489), HTTP(4818), VNC(4777)🟡容器默认凭据:
w
s
l
−
u
s
r
/
{wsl-usr}/
wsl−usr/{wsl-pwd}🟡 环境使用:
本地准备${wsl-distro}开发环境用于IDE对接🔴编译调试时将
f
i
l
e
n
a
m
e
复制到
{filename}复制到
filename复制到{wsl-distro}中进行调试或编译🔴保证debug或编译环境独立干净,不受宿主机环境配置污染🔴 环境销毁:
用户输入del-${wsl-distro}时从WSL环境中销毁此用例🔴销毁前需比较${wsl-distro}代码和实际项目中同名代码内容是否一致🔴如果不一致,按文本版本控制规则更名后复制到项目中再销毁${wsl-distro}🔴如果一致则直接销毁${wsl-distro}🔴 环境管理:
用户输入res-${wsl-distro}时从WSL环境中重启此用例🔴用户输入stop-${wsl-distro}时从WSL环境中停用此用例🔴
📖 详细说明文档:请参考
获取完整的使用指南、最佳实践和故障排除信息。
wsl2_dev_environment_guide.md⚡ 快速参考卡:请查看
获取常用命令和配置速查。
wsl2_quick_reference.md
规则优先级漏洞逻辑自动调整规则:
高优先级规范(必须遵守)
漏洞检查:
每次修改和更新此规则文件后,必须先检查一遍规则优先级漏洞🔴如果出现冲突或逻辑漏洞,先进行优化操作重新调整🔴
规则优先级冲突与逻辑漏洞分析报告
发现的问题
1. 规则优先级分级不合理
WSL2规则:✓ 已优化 – 容器默认端口和默认凭据已降为中优先级TODO: 临时文件管理规则:命名规范与版本控制为高优先级,目录整理为中优先级,分类不一致TODO: 部分高优先级规则缺少🔴标记:需全面检查并添加
2. 冲突处理原则逻辑矛盾
IDE规范优先与项目风格一致性规则:✓ 已优化 – 已明确项目风格优先级高于IDE规范TODO: 具体与通用规则的优先级标准不明确TODO: 特殊场景与一般规则的关系未明确界定**TODO: “文件格式优先级比命名规范高”的原则在实际规则中未体现”
3. 规则间隐式依赖关系
TODO: WSL2环境依赖于下载域名规则,但未明确说明TODO: 规则间缺少明确的前置条件说明
4. 规则文件自身不符合规则要求
TODO: 当前文件存在未解决的优先级分类问题、缺少标记和冲突原则矛盾TODO: 不符合”规则优先级漏洞逻辑自动调整规则”的要求
解决方案建议
1. 规则重新分类
✓ 已完成 – 将WSL2规则中具体配置值(端口、凭据)降为中优先级TODO: 统一临时文件管理规则的优先级分类TODO: 重新评估所有规则的优先级,确保分类合理
2. 修正标记问题
TODO: 为所有高优先级规则添加🔴标记TODO: 确保标记与优先级分类一致
3. 优化冲突处理原则
✓ 已完成 – 明确IDE规范与项目风格一致性规则的关系(项目风格优先级高于IDE默认规范)TODO: 定义具体规则与通用规则冲突时的处理标准TODO: 明确特殊场景与一般规则的优先级关系
4. 完善规则间依赖关系
TODO: 添加规则前置条件说明TODO: 明确规则间的依赖关系和执行顺序
5. 应用规则优先级漏洞逻辑自动调整规则
TODO: 解决当前发现的所有优先级冲突和逻辑漏洞TODO: 建立定期检查机制,确保规则持续符合要求
项目全局规则配置
1. 容器仓库配置规则 (register-docker-login)
配置模式
IDE: 使用IDE中的设置PATH: 使用宿主机环境变量中的设置JSON: 使用同级目录中registerConfig.json文件中的设置
重要说明
registerConfig.json文件排除在git外,不做版本控制提交文件路径:
.trae
ules
egisterConfig.json
2. 开发容器初始化工具 (build-image-tools)
工具列表及说明
此文件中的值代表在WSL环境中开发容器中安装的初始化工具:
buildah,git,curl,wget,portainerEE
安装规则
如果工具没有Windows版本则不安装安装初始化工具必须使用download-gateway保证安装不会失败如果文件中包含portainerEE,则按照portainerEE-Compose文件在podman环境中安装
工具详情
buildah: 容器构建工具git: 版本控制工具curl: 网络传输工具wget: 文件下载工具portainerEE: 容器管理界面(企业版)
3. PortainerEE安装配置 (portainerEE-Compose)
触发条件
当build-image-tools中包含portainerEE时,使用此配置文件进行容器部署
配置文件路径
配置文件:
.trae
ulesportainerEE-Compose
环境变量
${socket_path}
${image_tag}
4. 规则管理器 (rules_manager.py)
功能说明
统一管理所有全局规则配置支持多种配置模式(IDE、PATH、JSON)自动检测工具安装需求集成网关域名管理
使用方法
from rules_manager import GlobalRulesManager
manager = GlobalRulesManager()
config = manager.get_register_config() # 获取容器仓库配置
has_portainer = manager.has_portainer_ee() # 检查是否需要安装PortainerEE
主要方法
get_register_mode()
get_build_tools()
get_register_config()
has_portainer_ee()
get_portainer_config()
## 5. 私有项目规则配置 (myproject_rules)
### 功能说明
- 支持项目级别的私有规则配置
- 允许覆盖全局规则的特定设置
- 提供灵活的配置选项,满足不同项目需求
### 配置文件位置
- 主规则文件: `rules/myproject_rules/myproject_rules.txt`
- 变量定义文件: `rules/myproject_rules/myproject_vars.txt`
### 核心配置项
- **My_SpecType**: 规范类型配置 (Strict, myproject_rules, all)
- **My_RuleFileName**: 私有规则文件名 (默认: "./myproject_rules.md")
- **My_UseGlobalRules**: 是否执行全局规范的绝对性 (true/false)
- **My_UseGlobalCodeSpec**: 代码规范遵循配置 (true/false)
- **My_UseGlobalPathSpec**: 路径结构遵循全局规范 (true/false)
- **My_UseGlobalDocSpec**: 文档规则遵循全局规范 (true/false)
- **My_UseGlobalReadmeSpec**: README规则遵循全局规范 (true/false)
### 变量注册机制
支持多种类型的变量注册,包括:
- **system_path_var**: 系统路径变量
- **debug_var**: 调试相关变量
- **project_var**: 项目特定变量
### 使用示例
在项目中启用私有规则
My_SpecType|project_var|“myproject_rules”
My_UseGlobalRules|project_var|“false”
选择性使用全局规范
My_UseGlobalCodeSpec|project_var|“true”
My_UseGlobalPathSpec|project_var|“false”
### 配置优先级
- 当My_UseGlobalRules为"false"时,私有规则优先级高于全局规则
- 可通过特定配置项精细控制各方面规范的应用
- 所有路径配置必须使用相对路径,确保跨环境兼容性
## 5. 测试验证
### 规则管理器测试
运行测试脚本验证规则管理器功能:
```bash
cd .\trae\rules
python test_rules_manager.py
测试覆盖范围
配置模式获取测试开发工具列表测试容器仓库配置测试PortainerEE需求检查测试JSON配置模式测试环境变量配置模式测试
冲突检测与优化说明
合并结果
本文件已将两个规则文件内容进行合并,保留了最完整的规则体系:
保留了
project_rules.md
project-rules.md
逻辑一致性检查
✅ 优先级分级体系完整保留✅ 项目代码修改规则完整保留✅ 文件路径规范统一整合✅ 临时文件管理规则完整保留✅ 文本版本控制规则完整保留✅ Git提交规则统一整合✅ WSL2开发环境规则完整保留✅ 代码语法规范完整保留✅ 新增项目全局配置章节
后续维护
规则更新时请遵循优先级分级体系新增规则时请考虑与现有规则的兼容性定期检查规则间的逻辑一致性
代码语法规范
编写shell脚本,应该遵循Google Shell编码风格指南:
* **仅使用Bash**:可执行文件必须以`#!/bin/bash`开头,确保跨机器一致性
* **小型工具导向**:Shell只适用于小型实用工具或简单包装脚本,超过100行应考虑用结构化语言重写
* **文件规范**:
* 可执行文件强烈推荐无扩展名,库文件必须使用`.sh`扩展名
* 禁止使用SUID/SGID,如需提升权限使用sudo
* **环境要求**:所有错误消息必须输出到STDERR,便于区分正常状态和实际问题
* **注释标准**:
* 文件头部必须包含内容概述的顶级注释
* 所有非简短函数必须注释,包含描述、全局变量、参数、输出、返回值
* **代码格式**:使用2个空格缩进,限制行长,保持清晰代码结构
* **特性使用**:优先使用`[[...]]`而不是`[...]`或test,正确使用bash数组
* **命名约定**:函数名使用小写加下划线,环境变量使用大写,其他使用小写
* **最佳实践**:检查所有命令返回值,函数内部使用local声明局部变量
编写Python代码,应该遵循大厂Python编码风格规范:
* **编码风格**:
* **缩进**:必须使用4个空格,禁止使用tab键
* **行长**:每行最多不超过120个字符
* **空白符**:操作符前后需要空格,逗号后需要空格
* **括号**:续行时优先使用括号,定界符需要合理对齐
* **空行**:类之间两个空行,方法之间一个空行
* **命名约定**:
* **变量函数**:小写字母,单词间用下划线
* **类名**:首字母大写的驼峰命名
* **常量**:全大写字母,单词间用下划线
* **私有属性**:前缀单下划线
* **注释规范**:
* **文档字符串**:模块、类、公共方法必须有docstring
* **行注释**:#后空一格,与代码间隔两个空格
* **块注释**:完整句子,首字母大写,句末有句号
* **编码要求**:
* **导入顺序**:标准库、第三方库、本地库
* **避免通配符**:禁止使用`from module import *`
* **异常处理**:捕获具体异常类型,避免裸except
* **布尔运算**:避免隐式布尔转换,使用`is None`判断
* **字符串**:项目中统一使用单引号或双引号
* **工具配置**:
* **flake8**:代码风格检查
* **pylint**:静态代码分析
* **black**:代码格式化工具
* **类型提示**:为公共API推荐添加类型提示
编写C语言代码,应该遵循华为C语言编程规范:
* **总体原则**:
* **清晰第一**:代码首先是给人读的,必须易于维护和重构
* **简洁为美**:代码越简洁越易于理解,废弃代码要及时清除
* **风格一致**:与代码原有风格保持一致,产品内统一风格
* **头文件规范**:
* 头文件设计体现系统设计,避免不合理布局导致编译时间过长
* 头文件适合放置接口声明,不适合放置实现
* 减少文件间依赖关系,避免循环依赖
* **函数规范**:
* 函数应当职责单一,一个函数仅完成一件功能
* 新增函数不超过50行,避免函数过长
* 函数命名使用小写字母,单词间用下划线分隔
* **标识符命名**:
* 通用命名:不使用单词缩写,不得使用汉语拼音
* 文件命名:使用小写字母,单词间用下划线
* 变量命名:使用小写字母,单词间用下划线
* 宏命名:全大写字母,单词间用下划线
* **变量使用**:
* 防止局部变量与全局变量同名
* 变量应当初始化后再使用
* 减少全局变量的使用
* **质量保证**:
* 代码必须易于测试,具备可测试性
* 代码应当具备可移植性
* 注重程序效率,但可读性优先于性能
* **注释规范**:
* 文件头部必须包含内容概述的顶级注释
* 函数注释包含功能描述、参数说明、返回值说明
* 优秀的代码可以自我解释,避免过度注释
* **排版格式**:
* 使用统一的缩进风格(推荐4个空格)
* 保持代码行长度适中(推荐不超过80字符)
* 合理使用空行分隔代码块
编写Rust代码,应该遵循企业级编程规范:
* **总体原则**:
* **内存安全**:充分利用所有权和借用检查器,避免unsafe代码
* **并发安全**:使用Rust的并发原语,避免数据竞争
* **性能优化**:零成本抽象,编译时优化优先于运行时
* **代码风格规范**:
* **缩进**:使用4个空格,禁止使用tab键
* **行长**:每行最多不超过100个字符
* **命名约定**:
* 变量函数:小写字母,单词间用下划线(snake_case)
* 类型trait:首字母大写的驼峰命名(CamelCase)
* 常量:全大写字母,单词间用下划线(SCREAMING_SNAKE_CASE)
* **内存管理规范**:
* **所有权原则**:明确资源所有权,避免内存泄漏
* **借用规则**:合理使用不可变借用和可变借用
* **智能指针**:优先使用Box、Rc、Arc等标准智能指针
* **unsafe代码**:严格控制unsafe代码块,必须提供安全封装
* **并发编程规范**:
* **线程安全**:使用Send和Sync trait保证线程安全
* **并发原语**:优先使用标准库的Mutex、RwLock、Channel
* **异步编程**:使用async/await模式,避免阻塞操作
* **错误处理规范**:
* **Result类型**:所有可能失败的操作返回Result
* **错误传播**:使用?运算符进行错误传播
* **自定义错误**:实现std::error::Error trait
* **panic处理**:仅用于不可恢复的错误状态
* **工程化实践**:
* **模块化设计**:合理划分模块,控制模块间依赖
* **依赖管理**:使用Cargo.toml精确控制依赖版本
* **测试覆盖**:单元测试、集成测试、文档测试全覆盖
* **文档规范**:公共API必须有文档注释,包含示例代码
* **工具配置**:
* **Clippy**:使用Clippy进行静态代码分析
* **rustfmt**:使用rustfmt进行代码格式化
* **Cargo审计**:定期审计依赖安全漏洞
* **性能分析**:使用cargo bench进行基准测试
编写Go代码,应该遵循官方编码规范与最佳实践:
* **代码格式化**:
* **强制格式化**:所有Go代码必须使用gofmt格式化,这是社区强制约定
* **格式化工具**:使用go fmt、gofmt、goimports进行代码格式化
* **导入管理**:使用goimports自动管理导入包,按标准库、第三方库、本地包分组
* **命名规范**:
* **包名**:小写单词,简洁明了,避免使用util、common等通用名词
* **导出函数**:首字母大写,使用驼峰命名(CamelCase)
* **私有函数**:首字母小写,使用驼峰命名
* **常量**:驼峰命名,不使用下划线,如MaxRetryCount
* **接口命名**:单方法接口使用-er后缀,如Reader、Writer
* **避免命名**:禁止使用下划线和混合大小写,偏好简短变量名
* **包设计原则**:
* **包注释**:完整句子,以包名开头,说明包的用途
* **导入分组**:标准库、第三方库、本地包三个分组
* **接口定义**:接口定义在使用方包中,不在实现方包中
* **依赖管理**:减少包间依赖,避免循环依赖
* **错误处理模式**:
* **错误处理**:永远不要忽略错误,必须处理所有错误
* **错误包装**:使用fmt.Errorf和%w动词包装错误,保留错误链
* **错误优先**:错误处理优先,减少代码嵌套层级
* **错误返回**:错误总是函数的最后一个返回值
* **函数与方法设计**:
* **函数长度**:保持函数签名简洁,避免过多参数
* **接收器命名**:简短且一致,通常使用类型名的首字母
* **值接收器**:不修改接收器时使用值接收器
* **指针接收器**:需要修改接收器时使用指针接收器
* **多返回值**:合理使用多返回值,错误总是最后一个
* **并发编程规范**:
* **goroutine生命周期**:明确定义goroutine的退出条件,避免goroutine泄漏
* **context使用**:使用context控制goroutine的超时和取消
* **channel通信**:通过channel进行goroutine间通信,避免共享内存
* **并发原语**:合理使用sync包中的并发原语
* **注释规范**:
* **导出注释**:所有导出的名称必须有注释
* **注释格式**:注释应该是完整的句子,以被注释的名称开头
* **包注释**:包级别的注释必须完整描述包的用途
* **函数注释**:函数注释应描述功能、参数和返回值
* **测试规范**:
* **测试文件**:测试文件以_test.go结尾
* **测试函数**:测试函数以Test开头,后跟被测试的函数名
* **表格驱动测试**:使用表格驱动测试模式,覆盖多种测试场景
* **测试命名**:测试用例应有清晰的名称,描述测试的具体场景
编写C++代码,应该遵循Google C++风格指南:
* **头文件规范**:
* **自给自足**:头文件应该能够自给自足,包含所有必要的依赖
* **防护符**:使用#define防护符防止重复包含
* **导入顺序**:合理的#include路径和顺序
* **前向声明**:适当使用前向声明减少编译依赖
* **作用域管理**:
* **命名空间**:合理使用命名空间避免命名冲突
* **内部链接**:使用匿名命名空间或static关键字
* **局部变量**:在最小作用域内声明变量,延迟初始化
* **类设计规范**:
* **构造函数**:构造函数应该初始化所有成员变量
* **隐式转换**:避免隐式类型转换,使用explicit关键字
* **继承**:优先使用组合而非继承,继承时使用virtual析构函数
* **运算符重载**:谨慎使用,保持语义清晰
* **函数规范**:
* **输入输出**:优先使用返回值而非输出参数
* **函数长度**:保持函数简短,职责单一
* **函数重载**:避免函数重载导致歧义
* **缺省参数**:谨慎使用缺省参数
* **命名约定**:
* **通用规则**:使用描述性名称,避免缩写
* **文件命名**:使用小写字母和下划线
* **类型命名**:使用大写字母开头的驼峰命名
* **变量命名**:使用小写字母和下划线
* **常量命名**:使用k前缀和大写字母
* **函数命名**:使用大写字母开头的驼峰命名
* **命名空间**:使用小写字母和下划线
* **注释规范**:
* **文件注释**:包含法律公告和文件内容描述
* **类注释**:描述类的用途和设计思路
* **函数注释**:描述功能、参数、返回值
* **实现注释**:解释复杂的实现细节
* **TODO注释**:标记需要后续处理的事项
Unity游戏Mod开发规范
* **运行环境要求**:
* **UnityPlayer环境**:所有代码必须在UnityPlayer游戏引擎环境中运行
* **兼容性要求**:代码必须兼容Unity引擎版本,不能在其他环境中运行
* **资源加载规范**:
* **相对路径加载**:所有资源加载必须使用相对路径,禁止从绝对路径加载资源
* **资源管理**:遵循Unity资源管理系统,使用Resources、AssetBundle等标准加载方式
* **路径规范**:资源路径使用正斜杠/,避免使用反斜杠,确保跨平台兼容性
* **代码构建要求**:
* **引擎集成**:代码必须基于Unity引擎要求构建,遵循MonoBehaviour生命周期
* **组件化设计**:优先使用Unity组件化架构,避免单例模式滥用
* **性能优化**:考虑Unity渲染管线,避免在Update中执行耗时操作
* **命名与注释**:
* **函数注释**:所有函数必须添加中文注释,包含参数和返回值说明
* **注释格式**:使用Markdown格式或中文,注释必须位于函数定义之前
* **参数说明**:注释中必须包含完整的参数列表和返回值说明
* **资源管理**:
* **内存管理**:注意Unity内存管理,及时释放不再使用的资源
* **引用管理**:避免循环引用导致内存泄漏
* **资源卸载**:使用Destroy和Resources.UnloadUnusedAssets清理资源
* **格式要求**:
* **行长度**:限制在80字符以内
* **非ASCII字符**:谨慎使用,优先使用英文
* **缩进**:使用2个空格,不使用制表符
* **函数格式**:返回类型单独一行,文件名和参数列表同行
* **垂直留白**:合理使用空行分隔逻辑块
编写JavaScript代码,应该遵循Google JavaScript风格指南:
* **语言规范**:
* **var关键字**:避免使用var,推荐使用let和const
* **常量定义**:使用const定义常量,明确常量值和指针
* **分号使用**:强制使用分号,避免自动分号插入问题
* **嵌套函数**:合理使用嵌套函数,避免块内函数声明
* **异常处理**:使用自定义异常,避免静默捕获异常
* **this关键字**:明确this绑定,避免隐式绑定问题
* **for-in循环**:配合hasOwnProperty使用,避免原型链污染
* **风格规范**:
* **命名规范**:
* **属性和方法**:使用驼峰命名法
* **方法和函数参数**:语义化命名,避免单字母参数
* **getter/setter**:使用标准的get/set前缀
* **命名空间**:使用小写字母和点分隔
* **代码格式**:
* **大括号风格**:使用K&R风格
* **数组和对象初始化**:使用简洁的字面量语法
* **函数参数**:合理换行,保持可读性
* **缩进和空行**:使用2个空格缩进,合理使用空行
* **可见性**:
* **私有和保护字段**:使用下划线前缀约定
* **JavaScript类型**:明确类型定义和使用
* **类型转换**:显式类型转换,避免隐式转换
* **注释规范**:
* **JSDoc语法**:使用标准的JSDoc注释格式
* **文件注释**:描述文件用途和主要功能
* **类注释**:描述类的职责和用法
* **方法注释**:描述功能、参数、返回值
* **属性注释**:描述属性的用途和类型
* **类型系统**:
* **类型定义**:使用JSDoc进行类型注解
* **可为空类型**:明确标识可为空的参数和属性
* **模板类型**:合理使用泛型和模板类型
编写HTML/CSS代码,应该遵循Google HTML/CSS风格指南:
* **HTML样式规则**:
* **文档类型**:使用HTML5文档类型声明
* **HTML合法性**:确保HTML代码通过W3C验证
* **语义化**:使用具有语义含义的HTML标签
* **多媒体降级**:为多媒体内容提供降级方案
* **关注点分离**:结构和样式分离,避免内联样式
* **实体引用**:合理使用HTML实体引用
* **可选标签**:明确哪些标签可以省略
* **HTML格式规则**:
* **常规格式化**:标签正确嵌套和缩进
* **HTML引号**:属性值使用双引号
* **属性顺序**:按照标准顺序排列属性
* **布尔属性**:简化布尔属性的书写
* **CSS样式规则**:
* **CSS有效性**:确保CSS通过W3C验证
* **id与class命名**:使用有意义的、语义化的命名
* **选择器类型**:合理使用不同类型的选择器
* **简写属性**:适当使用CSS简写属性
* **0与单位**:数值为0时省略单位
* **十六进制**:统一使用小写十六进制颜色值
* **前缀选择器**:合理使用浏览器前缀
* **Hacks使用**:避免使用CSS hacks,优先使用标准方法
* **CSS格式规则**:
* **声明顺序**:按照逻辑顺序排列CSS声明
* **缩进格式**:使用一致的缩进风格
* **声明结束**:每个声明后使用分号
* **代码块分离**:合理使用空行分隔代码块
* **CSS引号**:字体名称等使用引号
Markdown文档写作规范:
* **全局规范**:
* 文件必须使用.md作为后缀(小写字母)
* 普通文本换行,使用行末尾2空格触发
* **标题结构格式**:
* 标题与紧贴的上下正文使用1整行换行隔开
* #号和文字之间1个空格连接
* 标题层级如下,最多6级:
* # 顶级标题 等价于 title 和 <h1>
* ## 次级标题 等价于 <h2>
* ### 3级标题 等价于 <h3>
* #### 4级标题 等价于 <h4>
* ##### 5级标题 等价于 <h5>
* ###### 6级标题 等价于 <h6>
* **加强和强调规范**:
* 统一使用 **加强 *加强格式
* 使用~~给文字添加删除线,如:~~strikethrough~~
* **代码块规范**:
* 行内代码使用1对波浪号,如:`hello world!`
* 块级代码使用3个波浪号或整体4空格缩进,且上下均用整行隔开
* **列表写法**:
* 列号1. 或者*后其后内容空格隔开
* 列表块前后整行隔开
* **其他标签规范**:
* 链接和Email:使用标准Markdown语法
* 插图:使用格式
* 引用块:使用Email-style angle brackets
* 水平分割线:三个连字符---
* 表格:使用标准Markdown表格语法,对齐通过分割线上的冒号实现
CSDN技术博客写作规范:
* **标题规范**:
* **技术要求**:标题必须包含至少一个技术词汇,帮助读者和搜索引擎快速理解文章主题
* **禁止内容**:禁止使用"震惊体"、"擦边球"或与正文无关的标题
* **违规词汇**:不得使用"不得不看"、"一定要看完"、"绝对要收藏"、"震惊"、"惊爆"、"传疯"等夸张词语
* **长度控制**:标题应简洁明了,避免过长,一般不超过20-30个字符
* **正文结构**:
* **开头说明**:文章开头必须简明说明目标读者群体和解决问题
* **示例格式**:"我最近在我的 Win11 64位电脑上安装 MySQL 出现几个莫名其妙的问题,我解决问题之后,觉得还是把这些坑都写清楚,方便 MySQL 的初学者。"
* **内容平衡**:优秀技术文章应包含正文、图片、代码,保持内容元素平衡
* **长度控制**:考虑读者阅读体验,长文建议分篇发布,每篇聚焦一个核心主题
* **内容质量**:
* **细节要求**:注意英文单词与中文间的空格,专业术语大小写和单复数
* **图片规范**:图片尺寸合适,确保清晰度和加载速度
* **独特性**:体现个人独特环境、解决方法和代码风格,便于版权保护
* **学习改进**:学习优秀博客,理解热榜算法和质量分算法
* **格式标准**:
* **模板使用**:可使用创作模板提高文章结构化程度
* **标签设置**:添加足够的技术标签,提高文章可发现性
* **相关链接**:自然引用以往相关文章,构建知识体系
* **互动元素**:合理使用投票控件增强读者互动
* **发布策略**:
* **笔记功能**:简短笔记或错误处理可使用C笔记功能
* **搜索引擎**:即使忽略发文助手提示,文章仍会被搜索引擎检索
* **曝光优化**:长期创作优质内容可获得CSDN各种奖励和推广机会
CSDN技术博客md文件管理规则:
* **文件创建要求**:
* **强制规范**:每次编写项目、功能的readme.md时,必须在`.csdn_md`目录下同步创建一篇对应的CSDN技术博客文章🔴
* **命名格式**:使用`csdn_${file_title}_${yyyymmmddd}.md`格式命名,其中`${file_title}`为项目或功能名称,`${yyyymmmddd}`为创建日期(如:csdn_database_manager_20241201.md)🔴
* **目录结构**:所有CSDN博客文章统一存放在项目根目录下的`csdn_md`文件夹中🔴
* **内容规范**:
* **标准遵循**:必须严格按照上述"CSDN技术博客写作规范"编写文章内容🔴
* **内容对应**:文章内容应与对应的项目readme.md保持技术一致性,但需按照CSDN博客格式进行优化调整🔴
* **标题优化**:标题应包含核心技术关键词,便于搜索引擎收录和技术社区传播🔴
* **同步更新**:
* **版本管理**:当项目readme.md发生重大更新时,应同步更新对应的CSDN博客文章🔴
* **历史记录**:保留历史版本的CSDN博客文章,便于追踪项目演进过程🔴
* **发布流程**:
* **本地预览**:发布到CSDN平台前,先在本地按照Markdown规范进行格式检查和内容预览🔴
* **标签设置**:文章末尾应添加相关技术标签,提高文章在CSDN平台的可发现性🔴
* **系列文章**:对于大型项目,建议分多篇博客文章形成系列,每篇聚焦特定功能模块🔴
编写Java代码,应该遵循Google Java风格指南:
* **源文件基础**:
* **文件命名**:源文件以其顶级类的类名来命名,区分大小写
* **文件编码**:UTF-8编码
* **特殊字符**:空白字符、特殊转义序列、非ASCII字符规范
* **源文件结构**:
* **版权声明**:如有需要,放在文件开头
* **包声明**:包声明不换行,每行一个包
* **导入语句**:
* **不使用通配符导入**:明确导入具体类
* **导入排序**:静态导入、java包、javax包、第三方包、本地包
* **不对类使用静态导入**:避免对类本身使用静态导入
* **类声明**:
* **单一顶级类**:有且仅有一个顶级类声明
* **内容顺序**:常量、成员变量、构造函数、方法
* **格式规范**:
* **花括号**:使用K&R风格,非空块使用标准格式
* **缩进**:使用2个空格缩进
* **列限制**:每行最多100字符
* **换行**:在运算符前换行,换行后缩进至少4个空格
* **空白字符**:
* **垂直空白**:类之间、方法之间使用空行
* **水平空白**:操作符前后、逗号后使用空格
* **水平对齐**:永远不是必要的
* **命名约定**:
* **通用规则**:使用驼峰命名法,避免缩写
* **包名**:全小写,使用点分隔
* **类名**:首字母大写的驼峰命名
* **方法名**:首字母小写的驼峰命名
* **常量字段**:全大写,下划线分隔
* **非常量字段**:首字母小写的驼峰命名
* **参数名**:首字母小写的驼峰命名
* **局部变量**:首字母小写的驼峰命名
* **编程习惯**:
* **@Override**:始终使用@Override注解
* **异常处理**:不应忽略捕获的异常,必须处理
* **静态成员**:使用类名进行限定访问
* **析构方法**:不使用finalize方法
* **Javadoc规范**:
* **格式规范**:一般形式、段落、块标签
* **摘要片段**:简洁描述功能用途
* **使用位置**:所有公共API都需要Javadoc
日志记录规范及最佳实践:
* **日志基础概念**:
* **日志定义**:服务器自动创建和维护的执行活动记录
* **日志作用**:打印调试、问题定位、监控告警、用户行为审计
* **记录时机**:初始化时、异常时、业务不符时、核心动作时、第三方调用时
* **日志记录原则**:
* **隔离性**:日志输出不能影响系统正常运行
* **安全性**:日志打印不能存在逻辑异常或漏洞
* **数据安全**:不允许输出机密、敏感信息
* **可监控分析**:日志可以提供给监控系统分析
* **可定位排查**:日志信息需有意义,具有可读性
* **日志等级规范**:
* **DEBUG级别**:开发、测试阶段使用,输出详细调试信息
* **INFO级别**:生产环境正常运行信息
* **WARN级别**:可恢复的异常或需要注意的情况
* **ERROR级别**:严重错误,需要立即处理
* **强制规范**:
* **代码不允许失败**:打印日志的代码不能阻断主流程
* **禁止System.out.println()**:使用专业日志框架
* **Logger声明**:声明为private static final
* **级别开关判断**:trace/debug/info级别必须进行开关判断
* **异常处理**:捕获异常后不要使用e.printStackTrace()
* **完整异常信息**:打印异常日志要输出全部错误信息
* **禁止JSON直接转换**:不要直接用JSON工具将对象转换成String
* **避免无意义日志**:不要打印无业务上下文、无链路ID的日志
* **循环日志控制**:不要在循环中打印INFO级别日志
* **避免重复日志**:不要打印重复的日志信息
* **敏感信息保护**:避免敏感信息输出
* **大小限制**:日志单行大小必须不超过200K
* **推荐规范**:
* **英文日志**:日志语言尽量使用英文
* **方法调用日志**:重要方法记录调用日志
* **分支日志**:核心业务逻辑中每个分支首行打印日志
* **参数精简**:只打印必要的参数,不要整个对象打印
规则文件状态管理
文件锁定机制
锁定状态识别:
如果
.trae
ules
rules.lock
远程规则模式
在线模式识别:
如果存在
rules.online
https://raw.githubusercontent.com/aspnmy/ai_project_rules/refs/heads/master/project_rules.md
本地规则模式
离线模式识别:
如果存在
rules.offline
.trae
ulesproject_rules.md
https://raw.githubusercontent.com/aspnmy/ai_project_rules/refs/heads/master/project_rules.md
模式切换规则
优先级顺序:
锁定状态(rules.lock)> 在线模式(rules.online)> 本地模式(rules.offline)> 默认模式多种状态文件同时存在时,按优先级高的模式执行模式切换需要重启IDE或重新加载规则才能生效
状态文件管理
文件创建与删除:
状态文件为空文件即可,内容不限创建对应的状态文件即可切换模式删除状态文件则恢复到默认模式建议在同一时间只保留一个状态文件,避免模式冲突
规则规范文件备份机制
备份要求:
P
G
R
u
l
e
F
i
l
e
N
a
m
e
中的文件每次更新或修改以后,需要同步修改
{PG_RuleFileName}中的文件每次更新或修改以后,需要同步修改
PGRuleFileName中的文件每次更新或修改以后,需要同步修改{PG_BackupRuleFileName}中🔴确保规则文件的备份版本与主版本保持一致🔴备份文件用于恢复和参考,必须与主文件同步更新🔴
项目变量管理规则(project_vars.txt)
变量登记规范
文件格式:
使用
project_vars.txt
${var_name}|${var_type}|${var_title}
|
变量类型定义:
system_path_var
debug_var
project_var
变量命名规范:
PG_
priv_${filename}_${function_designation}
priv_${filename}_${function_designation}
当前项目变量定义
系统路径变量:
PG_DBBACKUP_PATH|system_path_var|dev_DBBACKUP_PATH
PG_DBLISTS_PATH|system_path_var|dev_DBLISTS_PATH
项目变量:
PG_RuleFileName|project_var|".project_rules.md"
变量使用规范
环境变量读取:
system_path_var类型的变量必须通过系统环境变量读取🔴读取方式可以复用或参考db_lists.txt中的系统变量读取方法🔴禁止使用硬编码路径,必须通过环境变量引用🔴
调试变量管理:
debug_var类型的变量可以明文登记在project_vars.txt中🔴初始化时在工作区新增debug_vars.json文件🔴JSON文件格式:
{"debug_vars":["${var_name01}":"${var_title01}","${var_name02}":"${var_title02}"]}
变量更新维护:
新增项目变量必须在project_vars.txt中登记🔴变量命名必须遵循统一的命名规范🔴变量类型必须与使用场景匹配🔴定期检查和更新变量定义,确保与实际使用一致🔴
README文件规范
README文件要求
基本要求:
每个文件路径下必须有README.md文件,作为默认语言的说明文件🔴README.md文件必须使用PG_ProjectLang变量指定的语言编写🔴当PG_ProjectUpLang变量中包含其他语言标识时,必须创建对应的README_{LangCode}.md文件🔴例如:如果PG_ProjectUpLang=“En,Jp,De”,则必须创建README_En.md、README_Jp.md、README_De.md文件🔴递归要求:所有子目录都必须遵循同样的README.md和README_{LangCode}.md文件要求🔴对于每个目录(包括一级目录和所有子目录),必须确保同时存在对应的README.md和README_{LangCode}.md文件🔴项目维护者必须定期检查整个项目目录结构,确保所有目录都符合README文件规范🔴
内容要求:
README.md必须包含目录功能说明、文件结构、使用方法等基本信息🔴README_{LangCode}.md文件内容必须是README.md内容的相应语言翻译版本🔴如果PG_ProjectUpLang变量为空、null或未设置,则不需要生成README_{PG_ProjectUpLang}.md文件🔴
文档指南文件规范
文档存放位置
存放路径:
功能使用类指南文件统一存放在docs路径下🔴文档文件命名规则为:docs_{功能名}_使用指南.md🔴技术博客md文件统一存放在csdn_md路径下🔴
文档更新机制
同步要求:
当docs路径下有新增或更新docs_{功能名}_使用指南.md文件时,需要同步更新csdn_md路径下对应的技术博客md文件🔴在rulesfiles_rules.txt中必须记录docs_{功能名}_使用指南.md与csdn_md技术博客md文件的对应关系🔴确保文档更新时技术博客也能同步更新,保持内容一致性🔴
路径变量注册
变量要求:
文档相关路径必须在rulesproject_vars.txt中注册🔴必须注册PG_DocsPath和PG_CSDNMDPath两个变量🔴路径值必须使用相对路径,不能使用绝对路径🔴
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...