
示例仅演示“检索到上下文”,生成可对接任意 LLM(OpenAI/Claude/本地模型)。
# pip install sentence-transformers faiss-cpufrom sentence_transformers import SentenceTransformerimport faiss, numpy as np# 1) 准备文档(示例用三段文本)docs = ["RAG 通过从外部文档检索证据,再让大模型基于证据生成答案。","KAG 侧重结构化知识(知识图谱)注入,强调事实一致性与可控性。","GraphRAG 将文档抽取成图谱,再结合图谱结构化检索与生成。"]titles = ["什么是RAG", "什么是KAG", "什么是GraphRAG"]# 2) 向量化(bge-m3 多语模型)embedder = SentenceTransformer("BAAI/bge-m3")embs = embedder.encode(docs, normalize_embeddings=True)dim = embs.shape[1]# 3) 建索引(内积检索)index = faiss.IndexFlatIP(dim)index.add(embs)def retrieve(query, k=2):q = embedder.encode([query], normalize_embeddings=True)D, I = index.search(q, k)return [(titles[i], docs[i], float(D[0][j])) for j, i in enumerate(I[0])]# 4) 查询 + 构造提示(把证据拼进提示)query = "RAG 和 KAG 有什么区别?"hits = retrieve(query, k=2)context = " ".join([f"[{t}] {c}" for t, c, _ in hits])prompt = f"仅依据以下上下文作答,并给出要点对比: {context} 问题:{query}"print("拼装的上下文: ", context)print(" 可将上面 prompt 交给任意 LLM 生成答案(OpenAI/Claude/本地模型)。")
要接 LLM 生成(可选)
# pip install neo4jfrom neo4j import GraphDatabaseURI = "bolt://localhost:7687" # 你本地 Neo4j,或远程地址AUTH = ("neo4j", "password") # 修改为你的用户名/密码driver = GraphDatabase.driver(URI, auth=AUTH)with driver.session() as session:# 1) 建立一个极小知识图谱:Tesla <-[CEO]- Elon Musksession.run("""MERGE (c:Company {name:'Tesla'})MERGE (p:Person {name:'Elon Musk'})MERGE (p)-[:HOLDS_ROLE {title:'CEO'}]->(c)""")# 2) 以自然语言问题为入口,转成 Cypher(这里直接写死规则)question = "谁是特斯拉的首席执行官?"cypher = """MATCH (p:Person)-[r:HOLDS_ROLE {title:'CEO'}]->(c:Company {name:'Tesla'})RETURN p.name AS person, r.title AS title, c.name AS company"""result = session.run(cypher).data()driver.close()# 3) 将结构化结果喂给 LLM(这里仅打印;实际你可把 result 拼进提示再生成)print("结构化答案:", result)# -> [{'person': 'Elon Musk', 'title': 'CEO', 'company': 'Tesla'}]
RAG(Retrieval-Augmented Generation):从文档中“找证据再回答”,更适合开放域、时效更新快的场景。
KAG(Knowledge-Augmented Generation):把结构化知识(知识图谱/数据库)“融进生成过程”,在实体关系与事实一致性上更稳。
RAG与KAG:主要区别
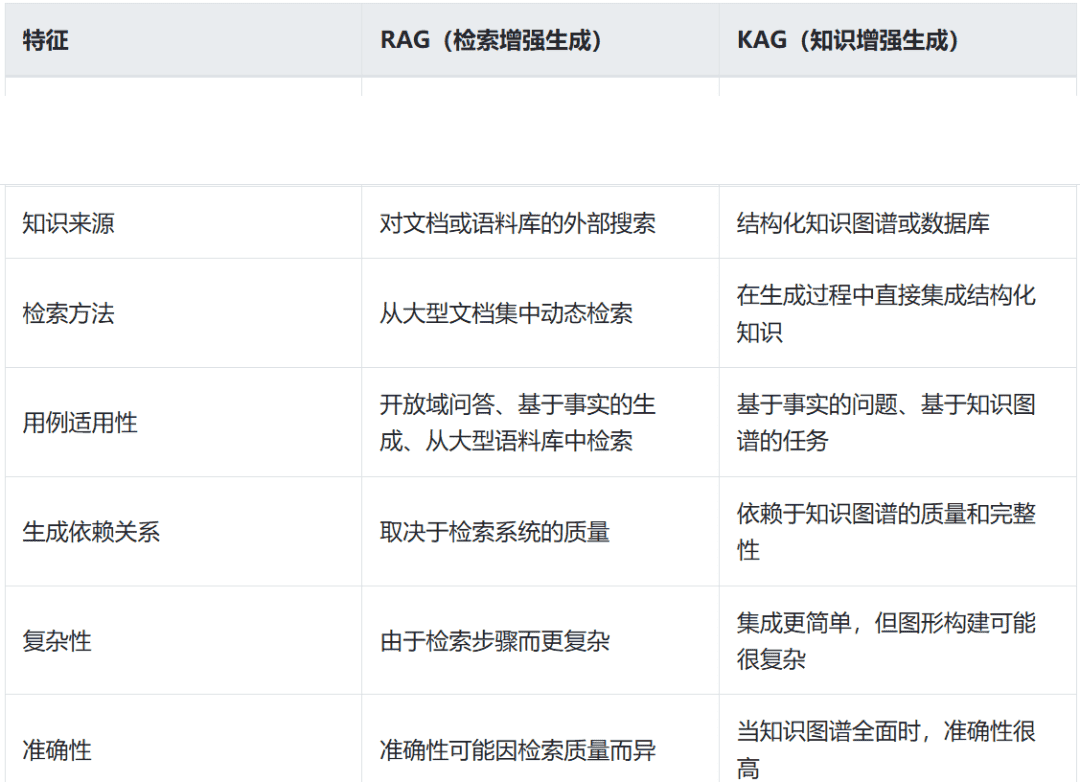
实战建议:多数业务选 RAG 起步;需要强事实一致性/规则推理时上 KAG;混合(GraphRAG/KG-RAG)能同时兼顾覆盖与可信。
RAG:原理、工程要点与开源实战
工作流要点
文档管线:清洗 → 分块(保标题层级/表格结构)→ 向量化 → 向量库
检索:向量召回(ANN)+ 重排(Cross-Encoder)+ 上下文压缩
生成:基于证据回答,标注引用/拒答策略
评估:检索命中率、答案一致性、引用可溯源、延迟/成本
最小可跑示例(FAISS + bge-m3 + 任何LLM)
依赖:pip install sentence-transformers faiss-cpu
LlamaIndex 端到端(最省心):LlamaIndex 负责分块、存储、检索、重排与调用 LLM。
LlamaIndex Quickstart(RAG):https://docs.llamaindex.ai/en/stable/getting_started/installation/
RAG 示例合集:https://docs.llamaindex.ai/en/stable/examples/
LangChain QA/RAG 用例文档:https://python.langchain.com/docs/use_cases/question_answering/
Haystack RAG 教程与管线(含重排/评估):https://haystack.deepset.ai/
开源组件选择(常用)
向量库:FAISS(本地)https://github.com/facebookresearch/faiss
Milvus https://github.com/milvus-io/milvus
Weaviate https://github.com/weaviate/weaviate
Chroma https://github.com/chroma-core/chroma
嵌入模型:BAAI/bge-m3(多语)https://huggingface.co/BAAI/bge-m3
重排模型:BAAI/bge-reranker-large https://huggingface.co/BAAI/bge-reranker-large
评估:RAGAS https://github.com/explodinggradients/ragas
TruLens https://github.com/truera/trulens
DeepEval https://github.com/confident-ai/deepeval
可复用实战项目/教程
LangChain Cookbook(多种 RAG 玩法)https://github.com/langchain-ai/langchain/tree/master/cookbook
Haystack Wikipedia QA 示例:https://haystack.deepset.ai/tutorials
LlamaIndex “Chat with your docs” 模板:https://docs.llamaindex.ai/en/stable/understanding/querying/
KAG:原理、工程要点与开源实战
工作流要点
知识构建:知识图谱/结构化库(实体、关系、属性、来源、时效)
实体识别与链接:把文本里的实体映射到图谱节点
图检索与推理:路径查询、多跳推理、约束查询(Cypher/SPARQL)
知识注入:提示中嵌入三元组/属性卡片、图嵌入、或解码约束
生成:基于结构化事实的可控生成(可带来源)
最小可跑示例(Neo4j 小图谱 + Cypher 查询 + 把结果交给 LLM)
依赖:pip install neo4j
图谱搭建/探索:
Neo4j(社区版+桌面管理)https://neo4j.com/
Wikidata(真实开放图谱,带 SPARQL)https://www.wikidata.org/
SPARQL 在线查询(Wikidata Query Service)https://query.wikidata.org/
图谱与 LLM 集成:
Neo4j GenAI 生态与示例合集:https://github.com/neo4j-labs/genai-ecosystem
LlamaIndex 知识图谱索引与查询:https://docs.llamaindex.ai/en/stable/examples/knowledge_graph/
图谱嵌入/推理:
PyKEEN(知识图谱嵌入)https://github.com/pykeen/pykeen
DGL-KE https://github.com/awslabs/dgl-ke
RDFLib(RDF 处理)https://github.com/RDFLib/rdflib
适用场景与实践提醒
适合:实体密集、规则明确、需要溯源一致性的任务(合规校验、设备部件关系、医药/专利实体关系、推荐系统特征联动)。
工程要点:实体链接质量>一切;定义好本体和命名规范;事实需要来源与时间戳;考虑冲突与版本管理。
混合范式(GraphRAG/KG-RAG):把“可用”和“可信”都做强
思路:先从文档中抽取实体/关系构成轻量知识图谱,再进行图结构检索与生成;同时保留原文片段用于溯源。
评估与监控:把“看起来会”变成“稳定可用”
开源项目
Microsoft GraphRAG(从文本构图+分层检索):https://github.com/microsoft/graphrag
LlamaIndex KG + 文本 RAG 组合:https://docs.llamaindex.ai/en/stable/examples/knowledge_graph/knowledge_graph_rag/
何时选
文档繁杂且跨域,需要图结构来理清“谁-与谁-什么关系”;但仍需原文引用与时效更新。
指标与工具
检索:Top-k 命中率、重排提升、覆盖率(BEIR/自建评测集)
生成:基于证据的正确性(RAGAS/TruLens)、一致性(同问同答)、拒答率
体验与成本:延迟、吞吐、调用费用
资源
RAGAS(自动化评估指标与流水线)https://github.com/explodinggradients/ragas
TruLens(在线观测/反馈回路)https://github.com/truera/trulens
DeepEval(可自定义断言/指标)https://github.com/confident-ai/deepeval
BEIR(检索评测基准)https://github.com/beir-cellar/beir
HotpotQA(多跳问答)https://hotpotqa.github.io/
MS MARCO(真实搜索问答)https://microsoft.github.io/msmarco/
快速选型清单
你的知识主要是文档、更新频繁 → RAG(向量库 + 重排 + 引用)
需要强一致性、图结构推理/约束 → KAG(知识图谱 + 实体链接)
进一步阅读(论文/技术参考)
RAG 原创论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP(Lewis et al., 2020)https://arxiv.org/abs/2005.11401
REALM:Retrieval-Augmented Pretraining(Guu et al., 2020)https://arxiv.org/abs/2002.08909
Fusion-in-Decoder(FiD, 2020)https://arxiv.org/abs/2007.01282
Atlas:Few-shot Learning with Retrieval(Izacard et al., 2022)https://arxiv.org/abs/2208.03299
KnowBERT(知识增强的代表工作,2019)https://arxiv.org/abs/1909.04164
K-BERT(知识图谱注入,2019)https://arxiv.org/abs/1909.07606
Microsoft GraphRAG(项目主页)https://github.com/microsoft/graphrag
两者都要:关键事实入图谱+规则约束,长尾与时效用检索补齐 → GraphRAG/KG-RAG
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











