
在使用大语言模型(LLM)时,你可能常常听到”Token”这个词,但可能并不清楚它到底是什么,为什么它会成为计费单位。想象一下,当你使用手机上网时,运营商会按流量计费;而在AI世界里,大模型也采用了类似的”流量计费”模式,而这个”流量单位”就是Token。今天,我们就来彻底搞懂Token是什么,以及它是如何计算的。

Token简介
Token是大模型处理的最小单位,可以简单理解为AI专用的”流量计量单位”。它不是我们一般理解的”字”或”词”,而是模型将输入文本分割成的最小处理单元。就像手机流量按”兆”计费一样,大模型处理文本也按”Token”计费。
Token的”真实”样子
让我们看几个例子:
- 中文句子:”我喜爱吃炸鸡”
—拆分成4个Token:[我/喜爱/吃/炸鸡]
—1个中文字符≈0.6个Token,所以”我喜爱吃炸鸡”约有2.4个Token
- 英文句子:”AI is amazing!”
—拆分成5个Token:[AI/is/amaz/ing/!]
—1个英文字符≈0.3个Token,所以”AI is amazing!”约有3.3个Token
- 更长的句子:”大模型处理文本的基本单位,通过分词器将文本分割成token,模型根据这些token生成输出”
—拆分成约15个Token
这里的关键是:Token不是按字数简单计算的,而是按模型的分词规则来划分的。不同的模型可能会对同一句话给出不同的Token数量。
为什么Token这么重大?
Token是大模型处理文本的基础,它影响着多个方面:
- 上下文长度限制:每个大模型都有一个最大上下文窗口,即它一次能处理的Token数量上限。例如,GPT-3.5-turbo的最大上下文是16,385个Token,超过这个限制的输入会被截断。
- 生成质量:Token数量影响模型能记住和理解的上下文长度,进而影响生成内容的质量和连贯性。
- 计费基础:Token是大模型API服务的计费单位,你输入和输出的Token总和决定了你需要支付的费用。
Token的计算规则:中英文差异
Token的计算规则因语言而异:
- 中文:1个中文字符≈0.6个Token
- 英文:1个英文字符≈0.3个Token
但请注意,这只是一个大致的估算。实际的Token数量取决于模型的分词方式和具体文本内容。
为什么中文和英文的计算比例不同?
这是由于中文和英文的分词方式不同。英文单词一般由空格分隔,而中文没有明显的分隔符,需要通过分词器来确定词语边界。
- 英文:一般按单词分词,但也会对长词进行拆分(如”amazing”拆成”amaz”和”ing”)。
- 中文:一般按字或词分词,但也会根据上下文进行调整(如”冰淇淋”可能被拆成”冰”、”淇”、”淋”,或作为一个词”冰淇淋”)。
Token消耗的计算方式
Token消耗的计算超级简单:你的提问+AI的回答=总Token消耗。
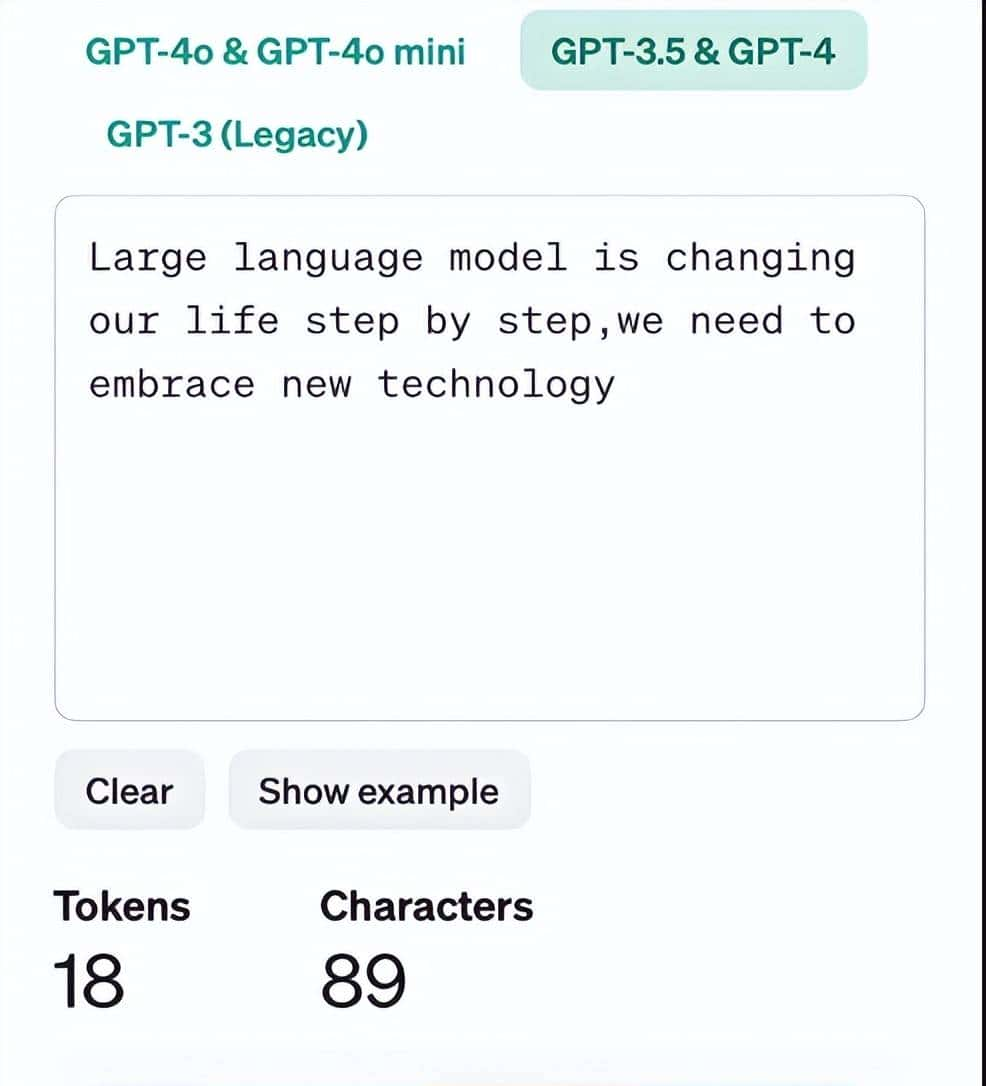
如何节省Token消耗?
了解了Token的计算方式,我们就可以采取措施节省Token,从而节省成本:
- 提问简洁明了:避免”车轱辘话”,直接说重点。例如,不要说”我想知道如何快速入睡,由于我最近总是失眠,晚上睡不着”,而要说”如何快速入睡?”
- 减少冗余信息:不要在提问中包含不必要的背景信息。
- 分步提问:如果问题复杂,可以分步骤提问,而不是一次性问多个问题。
- 控制回答长度:在API调用时设置合理的max_tokens参数,避免生成过长的回答。
- 使用提示词工程:通过精心设计的提示词,引导模型生成更简洁、更相关的回答。
如何计算自己的文本需要多少Token?
如果你想知道一段文本需要多少Token,可以使用以下方法:
- 使用模型API:大多数大模型API会在响应中返回usage信息,包括输入和输出的Token数量。
- 使用在线Token计算器:许多大模型提供商提供在线Token计算器,可以输入文本查看Token数量。
- 使用离线计算工具:如DeepSeek提供的tokenizer工具,可以离线计算一段文本的Token用量。
结语:掌握Token,用好大模型
了解Token的概念和计算方式,是高效使用大模型的关键。正如我们使用手机时要关注流量使用情况一样,使用大模型时也要关注Token消耗。掌握了Token的计算规则,你就能:
- 更好地规划和设计与大模型的交互
- 有效控制使用成本
- 提高与大模型交互的效率
- 为更复杂的AI应用打下基础
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录









token将是未来经济货币
收藏了,感谢分享