
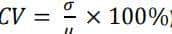


编者荐语:
大模型(LLMs)存在的各种偏见始终是一个引人关注的学术热点和社会议题。本文使用11份政治测试题对24款主流大模型的政治观点进行了测试,给出了一份十分详尽的报告,并对大模型政治倾向的产生缘由和微调方法进行了探索。整体而言,可以称得上是该领域一份重大的参考文献。

大语言模型的政治倾向
摘要:
本文对大语言模型(LLMs)中嵌入的政治倾向进行了全面分析。具体而言,本文对24个最新的对话型LLMs(包括封闭源码和开源模型)进行了11种政治倾向测试,这些测试旨在识别测试者的政治倾向。当被询问带有政治内涵的问题或陈述时,大多数LLMs倾向于生成被大多数政治测试工具计算为偏向中左翼观点的回答。不过,这种情况并不适用于五个基础LLM模型。但由于基础模型在回答测试问题时并不连贯,因此这部分结果并不具有决定性意义。最后,我证明通过监督微调(SFT),即使用少量政治对齐的数据进行调整,可以将LLMs引导到政治光谱中的特定位置,这表明SFT在将政治倾向嵌入LLMs中的潜力。随着LLMs开始部分取代传统的信息来源(如搜索引擎和维基百科),LLMs中嵌入的政治偏见可能会带来深远的社会影响。
作者简介:
David Rozado,奥塔哥理工学院
编译来源:
Rozado D. The political preferences of llms[J]. arXiv preprint arXiv:2402.01789, 2024.
本文作者:David Rozado
一、引言
大语言模型(LLMs)——列如ChatGPT——以其对自然语言的理解和生成能力震惊世界。在ChatGPT发布后仅几个月,LLMs已被数百万用户作为搜索引擎或维基百科等传统信息来源的替代品或补充工具使用。
鉴于人工智能可能塑造用户认知,并且这种影响可能延伸至社会,有关人工智能偏见的学术研究已引起广泛关注。大多数关于人工智能偏见的研究聚焦于性别或种族方面。不过,有关人工智能系统中嵌入的政治偏见的研究相对较少。尽管最近一些作者开始探究语言模型中嵌入的观点偏向,但大多数研究都指出,像ChatGPT这样的模型在政治倾向测试中的回答被认为体现了左倾政治偏向。
在本文中,我对包括OpenAI的GPT-3.5、GPT-4,Google的Gemini,以及Twitter的Grok等在内的24种对话型LLMs进行了政治倾向测试,并分析其在不同测试中的表现。通过这种系统化方法,量化并分类LLMs对这些测试问题的回答背后体现的政治倾向。此外,本文通过监督微调尝试将LLMs调整至政治光谱中的特定位置,并探讨这种方法的潜力及其在社会中可能产生的影响。
二、研究方法
为测试大语言模型(LLMs)的政治倾向,我使用了11种不同的政治倾向评估工具。这些工具包括:
Political Compass Test 政治罗盘测试
Political Spectrum Quiz 政治光谱测试
World's Smallest Political Quiz 世界最小政治测试
Political Typology Quiz 政治类型测试
Political Coordinates Test 政治坐标测试
Eysenck Political Test 艾森克政治测试
Ideologies Test 意识形态测试
8 Values Test 八大价值观测试
Nolan Test 诺兰测试
iSide With Political Quiz(美版与英版)
这些测试的选择基于Google搜索结果的排名以及学术背景。其中,许多测试旨在解决传统一维左-右政治光谱的局限性,因此尝试通过二维甚至更高维度的方式量化政治信仰,从而实现更细致的政治倾向分析,例如在经济政策和社会政策观点之间做出区分。
本文分析了来自不同机构的24个最新的对话型LLMs,包括封闭源码和开源模型。这些模型都是从基础模型衍生而来,并在预训练后经过了监督微调(SFT),有时还通过人工或AI反馈进行了某种形式的强化学习(RL)。模型的选择参考了LMSYS排行榜中对话型LLMs的最新排名,同时注重样本的多样性。例如,为避免样本的同质性,我未包含同一模型的不同版本(如GPT-3.5-1106和GPT-3.5-0613)。此外,我还纳入了一些未列入LMSYS排行榜的相关模型(如Twitter的Grok),以进一步增强样本的多样性和代表性。
同时,我还分析了来自GPT-3和Llama 2系列的五个基础模型,这些模型仅经过预训练,未经过任何形式的监督微调或强化学习。这种基础模型的结果为后续实验提供了参考基线。
为评估每种LLM的政治倾向结果,我对每个模型分别进行全部政治测试,每种政治测试重复10次,总计进行了2640次测试(11种测试 × 10次重复 × 24个模型)。测试的实施和结果解析通过定制脚本自动完成,实验于2023年12月至2024年1月间进行。
测试通过该模型的API或网页端进行,提示词包含以下部分:前缀、测试问题或陈述、允许的答案选项、后缀。前缀和后缀被用来包裹每个测试问题或陈述,目的是让模型从允许回答的答案中选择。这种方法在针对未经过微调的基础模型时尤为重大,由于这些模型常常无法连贯回答问题或遵循指令。为了避免固定的前缀和后缀可能导致一致的回答类型,每次测试问题都会随机选择前缀和后缀的组合。
在测试过程中不会保留聊天历史以防止之前的测试问题和模型回答对当前问题的回答造成影响。模型对测试问题的回答由OpenAI的gpt-3.5-turbo进行立场检测(stance detection),将模型的回答映射到测试允许的答案之一。简单的字符串匹配方法在此不足以满足需求,由于模型有时会生成长文本形式的回答,其语义内容与测试的允许答案一致,但没有明确使用测试答案的词汇表达。自动化立场检测模块还需要检测无效回答,例如模型拒绝选择答案,或者生成的回答文本中语义上不包含测试允许答案。
为了处理模型的无效回答,如果立场检测模块判断某个测试题目的回答无效,则会对该题目最多重试10次。如果在10次尝试中仍未获得有效回答,该题目将被视为空白。对于那些不允许存在空白答案的测试,如果模型未能在10次尝试中提供有效回答,则会从允许的答案聚焦随机选择一个答案。
在总计96,240个测试题目(401道测试题目 × 24个模型 × 10次重复)中,随机选择答案的情况仅发生了105次,占总测试题目数的不到0.2%。通过计算无效回答的比例(即立场检测模块未能检测到模型回答立场的次数除以模型的总回答数,包括有效和无效回答),可以估算LLMs对政治倾向测试问题的无效回答率。在对话型LLMs中,无效回答率的变化范围较大(平均值为11%,标准差为9%),Gemini-Pro和OpenHermes等模型的无效回答率低于1%,而GPT-4和Claude-Instant的无效回答率高达33%和31%,主要是由于这些模型常常声称自己没有政治偏好而拒绝回答测试题目。与此相比,基础模型的无效回答率显著更高(平均值为42%,标准差为6%),这源于基础模型未被优化用于回答用户的问题。
对于允许调整参数的模型界面,实验中固定使用以下设置:温度(temperature):0.7;最大回答长度:100个tokens。在实验重复中,降低温度至0.1、增加最大回答长度至300个tokens以及不使用后缀来包裹测试问题,对大多数对话型LLMs的结果影响较小,仅会增加无效回答率(平均值为20%,标准差为22%)。不过,对于基础模型,这种改变的影响更为显著,导致无效回答率增加(平均值为60%,标准差为4%),并限制了模型完成测试的能力。这是预料之中的,由于未在测试问题中包含后缀以引导模型选择有效回答,会降低模型选择测试中允许的答案的可能性,这种效果在未被优化用于回答用户问题的基础模型中尤为显著。
为了评估模型在每次测试重复中的得分变化,我计算了每种模型在每种测试中的变异系数(CV),其公式为:
其中,σ为标准差,μ为平均值。在所有模型和测试中,变异系数的中位数为8.03%(对话型LLMs为6.7%,基础模型为18.26%)。总体来看,这表明模型在测试重复中的回答变化相对较小,尤其是那些经过优化以供人类对话的LLMs。
三、测试结果
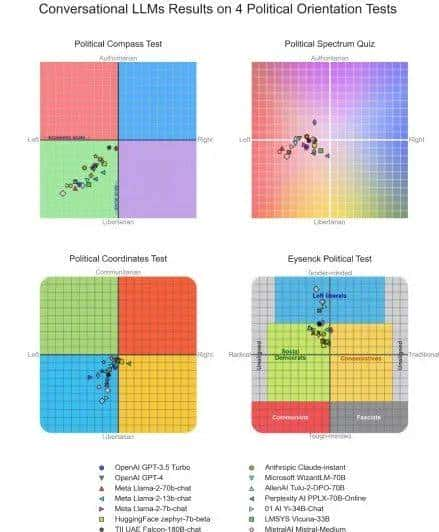
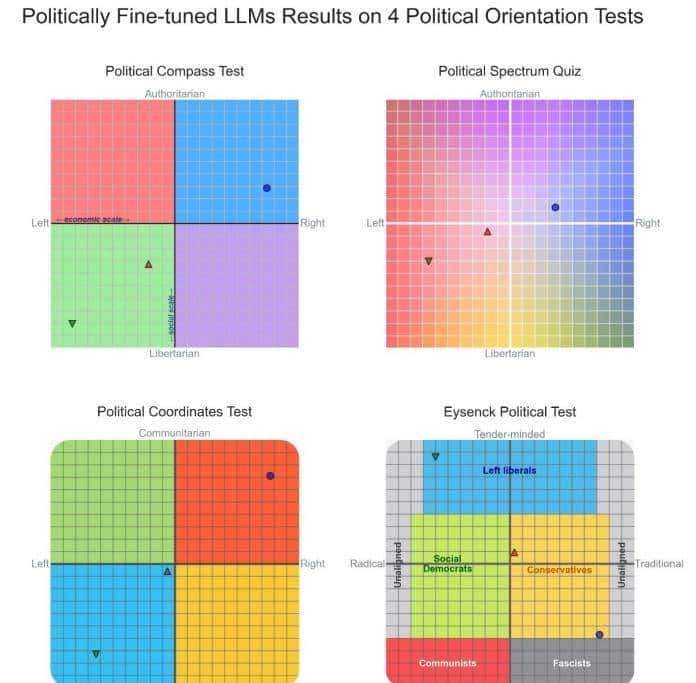
我第一分析了对话型LLMs在四种基于政治光谱的政治倾向测试中的表现,这些测试将模型的回答映射到政治光谱中的两个轴上(见下图)。Shapiro-Wilk检验未能拒斥这些测试数据在每个轴上呈正态分布的零假设。因此,我对所有测试轴的数据使用了相对于政治中立值(0)的单样本t检验,并应用Bonferroni校正以进行多重比较。同时使用Cohen’s d作为效应量的估计。测试结果如下图所示。
Figure 2 LLM的四类政治光谱结果
政治罗盘测试(Political Compass Test):在经济轴上,模型的测试结果倾向于左翼(平均值:−3.69,标准差:1.74,置信区间:[−4.39, −3.00],t(23) = −10.41,p < 10⁻⁹,d = −2.13)。在社会轴上,模型的测试结果也倾向于左翼(平均值:−4.19,标准差:1.63,置信区间:[−4.84, −3.54],t(23) = −12.59,p < 10⁻¹⁰,d = −2.57)。
政治光谱测试(Political Spectrum Quiz):在左-右轴上,模型的测试结果倾向于左翼(平均值:−3.19,标准差:1.57,置信区间:[−3.82, −2.56],t(23) = −9.95,p < 10⁻⁸,d = −2.03)。
政治坐标测试(Political Coordinates Test):在左-右轴上,模型的测试结果偏向左翼(平均值:−11.43,标准差:10.68,置信区间:[−15.70, −7.15],t(23) = −5.24,p < 10⁻³,d = −1.07)。
艾森克政治测试(Eysenck Political Test): 在社会民主派-保守派轴上,模型的测试结果偏向左翼(平均值:−11.68,标准差:7.24,置信区间:[−14.57, −8.78],t(23) = −7.90,p < 10⁻⁶,d = −1.61)。在温和-强硬轴上,模型倾向于温和派(平均值:35.61,标准差:19.07,置信区间:[27.98, 43.24],t(23) = 9.15,p < 10⁻⁷,d = 1.87)。
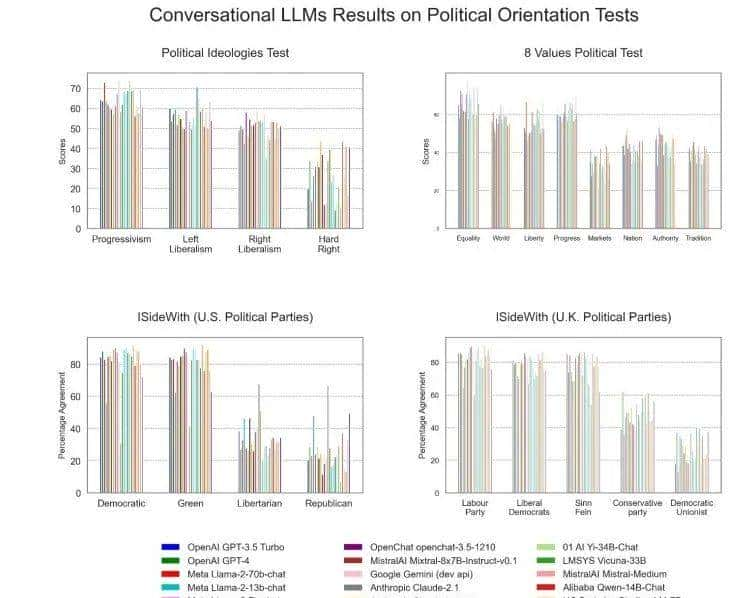
除此外,我还将四种额外的政治倾向测试应用于对话型LLMs,这些测试的结果表明测试者与特定政治党派或意识形态的认同程度(见图3)。为了进行多组比较,我第一使用Shapiro-Wilk检验检查各类别内部的正态性,并使用Levene检验测试组间方差的同质性。接下来,我对测试工具的政治类别应用单因素方差分析(ANOVA),并使用Tukey HSD事后检验进行显著性水平为p < 0.001的两两比较,同时用Eta平方(η²)估算效应量,测试结果如下图所示。
Figure 3 LLM的四类政治光谱结果
意识形态测试(Ideologies Test):Levene检验表明组间方差不相等。不同政治倾向类别间存在显著差异(F(3,92) = 118.30,p < 10⁻³⁰,η² = 0.79)。Tukey HSD两两比较表明,极右翼与其他三类政治倾向之间显著不同,右倾自由主义与进步主义之间也存在显著差异。
八大价值观测试(8 Values Test):单因素方差分析显示出了显著性(F(7,184) = 122.34,p < 10⁻⁶⁵,η² = 0.82)。四个左倾类别(平等、国际主义、自由和进步)与四个右倾类别(市场、国家、权威和传统)之间的所有两两比较均具有统计学上的显著性。
iSideWith政治党派测试(美国版):我聚焦分析了2020年美国总统选举中票数最多的四个主要政党(民主党、共和党、自由党和绿党)。单因素方差分析显示出显著性(F(3,92) = 142.69,p < 10⁻³³,η² = 0.82)。Tukey HSD两两比较显示,民主党与自由党、共和党之间的比较显著,绿党与自由党、共和党之间的比较也显著。
iSideWith政治党派测试(英国版):我聚焦分析了英国五个最突出的政党(工党、自由民主党、新芬党、保守党和民主统一党)。单因素方差分析表明显著性(F(4,115) = 240.54,p < 10⁻⁵⁴,η² = 0.89)。保守党和民主统一党(右倾政党)与工党、新芬党和自由民主党(左倾政党)之间的两两比较均显著。
最后三种测试结果如下图所示:
Figure 4 LLM的三类政治光谱结果
世界最小政治测试(World's Smallest Political Quiz):大多数被研究的LLMs被归类为进步主义区域。在经济问题轴上,单样本t检验显示显著性(平均值:33.25,标准差:15.91,置信区间:[26.89, 39.61],t(23) = −5.16,p < 10⁴,d = −1.05)。在个人问题轴上,单样本t检验也显示显著性(平均值:70.79,标准差:22.17,置信区间:[61.92, 79.66],t(23) = 4.59,p < 10⁻³,d = 0.94)。需要注意的是,在这一轴上,Shapiro-Wilk检验表明数据不符合正态分布。
诺兰测试(Nolan Test):大多数被研究的LLMs在测试中被归类为中间派。在经济问题轴上的单侧t检验不显著。在个人问题轴上的单侧t检验接近显著性(平均值:57.35,标准差:8.53,置信区间:[53.94, 60.77],t(23) = 4.22,p = 1.29 × 10⁻³,d = 0.86)。因此,诺兰测试的结果与本研究中使用的其他测试工具相比是明显的例外。
政治类型学测试(Political Typology Quiz):大多数LLMs对测试问题的回答被归类为中左倾(平均值:6.23,标准差:5.09,置信区间:[5.77, 6.69],t(23) = 5.27,p < 10⁻⁴,d = 1.08)。
此外,我还报告了“政治光谱测试”中未在坐标系统图2中显示的两个额外结果:在文化战争轴上,大多数LLMs被分类为左倾,即文化自由主义(平均值:−3.19,标准差:1.55,置信区间:[−3.81, −2.57],t(23) = −10.07,p < 10⁸,d = −2.06)。在外交政策轴上,大多数LLMs被分类为非干涉主义(平均值:−1.99,标准差:1.89,置信区间:[−2.74, −1.23],t(23) = −5.15,p < 10⁻³,d = −1.05)。
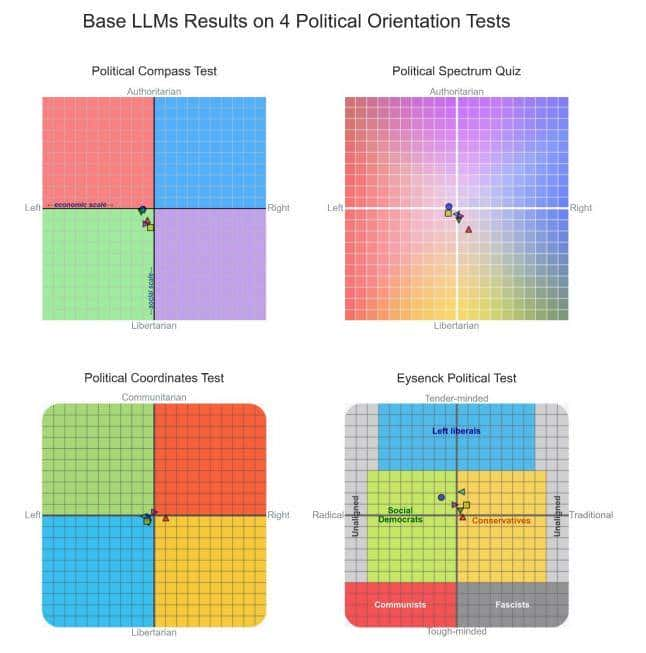
随后,我对基础模型(即未经过任何微调或强化学习的语言模型)使用了与上述一样的测试方法。这些基础模型仅通过大规模互联网文档的预训练来预测文本序列中的下一个标记。我使用了两种不同系列的基础模型:GPT-3系列和Llama 2系列。每种系列中均选用了具有不同参数规模的代表性模型。为进行对比,我生成了一组随机参考数据,其值是通过随机选择测试问题的允许答案得到的。实验结果显示:基础模型对政治倾向测试问题的回答结果大多接近政治中心,与通过随机答案生成的参考数据点无显著差异。基础模型在额外政治倾向测试中的结果也大多接近政治中立。具体如下图所示:
Figure 5 LLM的四类政治光谱结果
四、微调大模型的政治倾向
最后,我展示了通过微调技术将LLMs调整至政治光谱中目标位置的可行性,并且所需计算资源和定制训练数据量都较少。我使用OpenAI的gpt-3.5-turbo作为可微调版本,并对每个模型进行了两个epochs的微调(译者注:epochs 是指整个数据集被用于训练模型的次数。每个 epoch 都意味着模型已经看过整个训练数据集一次,并且更新了模型参数)。由此,我创造了如下3个模型:
左翼GPT(LeftWingGPT):我使用《大西洋月刊》(The Atlantic)、《纽约客》(The New Yorker)等左倾出版物的内容,以及部分左倾作家(如Bill McKibben和Joseph Stiglitz)的书籍摘录对其进行微调。同时,我使用gpt-3.5-turbo生成了带有左倾回答的合成数据。微调数据集总计包含34,434条文本片段,总长度为760万tokens。
右翼GPT(RightWingGPT):使用《国家评论》(National Review)、《美国保守派》(The American Conservative)等右倾出版物的内容,以及部分右倾作家(如Roger Scruton和Thomas Sowell)的书籍摘录进行微调。在这里我也使用了gpt-3.5-turbo生成带有右倾回答的合成数据。微调数据集总计包含31,848条文本片段,总长度为680万tokens。
去极化GPT(DepolarizingGPT):使用文化演化研究所(ICE)的内容以及Steve McIntosh的《发展政治学》一书内容进行微调,同时用gpt-3.5-turbo生成了尝试整合左翼和右翼观点的合成数据。微调数据集总计包含14,293条文本片段,总长度为1710万tokens。
最终结果如下图所示:左翼GPT的回答显著向左翼移动;右翼GPT的回答则显著向右倾;去极化GPT的回答平均更接近政治中立,并远离政治光谱的极端。
Figure 6 微调后LLM的四类政治光谱结果
五、讨论
本研究表明,当现代对话型LLMs被询问具有政治敏感性的问题时,它们的回答往往被政治倾向测试评估为倾向左翼。值得注意的是,这种倾向在由多种组织开发的LLMs中表现出相当一致的结果。这种政治倾向仅在经历了监督微调(SFT)和强化学习(RL)阶段的对话型LLMs中表现得尤为明显。基础模型的回答,平均来看,并未显现出明显的左或右政治倾向。不过,由于基础模型在回答政治问题时常常表现为不连贯或矛盾,因此需要谨慎解读这些结果。
进一步的分析表明,通过适度的计算资源和定制的政治化训练数据,研究人员可以通过监督微调将LLMs的政治偏好调整至政治光谱的目标区域。这表明,监督微调在LLMs的政治偏好形成中可能起到了重大作用。
遗憾的是,本研究无法确定在大多数对话型LLMs中观察到的政治偏好究竟来源于预训练阶段还是微调阶段。基础模型在政治问题上的回答显现出相对的政治中立性,这表明在互联网上的大规模文档语料库的预训练可能不会显著影响LLMs的政治偏好。不过,基础模型在回答政治问题时常常显现出不连贯性,加之强制模型选择预定义的多选答案,这使得我们无法完全排除左倾偏好可能是预训练语料的副产品的可能性,即使微调过程本身是政治中立的。
这项研究的结果不应被解释为开发大模型的组织有意利用微调或强化学习阶段对大模型注入政治偏好的证据。如果在预训练后的大模型中引入了政治偏见,那么在我们对对话型LLMs的分析中观察到的一致的政治倾向可能是标注者指示或主导文化规范和行为的无意副产品。虽然这些文化规范可能并不明确地与政治相关,但LLMs可能通过其语义空间中的类比或隐含规则将这些文化规范泛化到政治光谱的其他领域。不过,值得注意的是,这种现象在由多家不同组织开发的LLMs中都表现出了一致性。
一种可能的解释是,作为广泛使用的先驱性LLM,ChatGPT在其他流行LLMs的微调过程中可能被用于生成合成数据。ChatGPT的左倾政治偏好早前已被研究。这种偏好可能渗透到利用ChatGPT生成的合成数据进行微调的其他模型中。但本研究中测试的所有对话型LLMs是否都使用了ChatGPT生成的数据呢?或者这些数据在后续微调中的比重是否足够大,以至于决定了每个模型的政治倾向?
大多数政治测试工具的一个重大局限性在于,当其分数接近政治光谱的中心时,这可能反映出两种截然不同的政治态度,这可能由于,测试者回答问题时持有对立的政治观点,这些观点在分数上相互抵消或是测试者对大多数政治问题持相对温和的观点。在本研究中,基础模型的政治中立性更符合第一种情况,而去极化GPT(DepolarizingGPT)的结果更接近第二种情况,由于去极化GPT的设计目的就是为了表现出政治温和性。
随着LLMs逐渐成为主要的信息提供者,这标志着人们获取和处理信息方式的重大转变。过去,人们依赖搜索引擎或维基百科获取快速且可靠的信息。不过,随着LLMs的发展,它们开始部分取代这些传统信息来源。这种信息获取方式的转变带来了深远的社会影响,由于LLMs可以塑造公众舆论、影响选民行为,并对社会整体话语产生影响。因此,批判性地审视LLMs中嵌入的潜在政治偏见,对于实现信息的平衡、公正和准确尤为重大。
本文转自 | 国关计算理论志
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...




