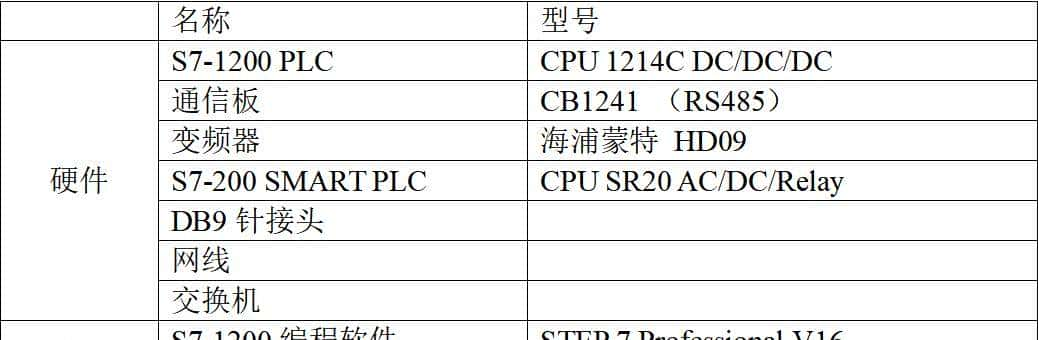

1.满血板定义和划分
目前市面上,只要是671B参数的DeepSeek都叫满血版
满血版又分:
原生满血版(FP8 数据精度,显存占用 671G )
转译满血版 (BF16或者FP16数据精度,显存需求未量化1342G)
量化满血版(INT8(Q8) 显存 671G、INT4(Q4)显存335G、Q2、Q1数据精度)
三种划分方法和命名,在2月9日,由“算力百科”组织线下沙龙,由几名行业专家首次提出并论证,已经获得同行广泛认可。
默认官方原生满血版就是智商最高的DeepSeek版本。
厂商宣传时,都只会宣传满血版,主意辨别。
2.三款支持FP8的国产AI芯片
算力百科已经跟相关厂商完成确认,目前公开市场有三款国产AI芯片支持FP8,算能SC1x、瀚博VA1x、摩尔线程S5x。
某头部AI芯片大厂,给客户推广DeepSeek一体机,被问到是否支持Fp8时,说的原话是“所有国产AI芯片都不支持Fp8”,用来弱化自家国产AI芯片不支持FP8的短板。
此类人还有一些媒体人,难道说真的不懂还是别有用心?国产AI芯已经很难啦,做的性能好,老美制裁,做的不好又卖不出去,目前又被同行抹黑,我们呼吁,请停止抹黑国产AI芯。
3.模型参数越大,智商越高
实践证明DeepSeek模型参数量跟智商成正比,参数越大,智商越高。
咱把671B相当于博士生,70B相当于本科生,32B相当于专科生,并不是所有的岗位都需要博士生,根据需求选择最好的即可。
但是多数情况,这个岗位用过了博士生都不再愿意用本科更何况是专科生。
4. 671B各个版本智商,比70B和32B智商都高。
我们内部测试结果,671B Q4量化的效果比蒸馏的70B的确 是好,相当于不同专业的博士生,的确 比本科生智商更优秀。
测试方法:把一样的问题,问不同的模型,查看返回结果,跟官方chat.DeepSeek.com返回答案对比,看类似程度。
问题列如: 7.11和7.9哪个大?
5.DeepSeek 开源openinfra 是绑定了CuDA生态?!
开源的目的是让更多的人能基于DS的工作,进一步创新或者移植,并不是非要绑定CuDA生态,也许某一天国产算力生态成熟了,会被基某公司采用。
6.Deepseek模型更新太快,对国产AI芯片不是好事。
DS每推出一代模型,国产AI芯片就需要适配和优化,投入大量人力物力,当这一代刚适配优化完,还没收回成本,下一代又发布了,如此快速迭代,让AI芯片厂商吃不消,小的AI芯片团队容易掉队,所以说软件创新太快,不必定是好事,任何事情发展都需要一个度。
7.国人对大模型的认知两个契机和时间点
22年底朋友圈里GPT火了,大家知道大模型,狼要来了。
24年底朋友圈Deepseek火了,大模型应用,狼真的来了。
使用Deepseek,参与全球创新,是大势所趋,是历史的必然。与智能手机必定取代功能机一样。
8.基础大模型公司必定会自研芯片,如果不自研,只能说明不够大。
基础大模型公司必定会自研芯片(投资、孵化、收购),由于需求确定,并且采购量巨大,自研的必定比单独采购第三方经济。
9.英伟达会长期是训练芯片的霸主
英伟达投资了全球绝大多数独角兽基模公司,基模公司想当长的时间内选择成熟的CuDA生态,可以快速出成果,跟进全球创新,这是必然选择。
一个基本实际,目前全球领先的基础大模型还没有一个是脱离CuDA训练成功的。
但是Gork3的发布说明堆算力炼丹模式已经走到头,边际收益已经低的令人发指了,训练霸主也无能为力。
10.我们应该做正确的事
赚自己认知内的米,20年前的光伏产业,10年前的新能源产业,目前的算力大模型产业,都是产业发展的必然。
任何繁荣产业的初期,都会有许多产业机会,很高兴参与新时代产业发展中,每个人都利用自身的资源和优势,找到自己的产业定位,赚到米。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录












说的都什么乱七八糟