实际开发中全文检索都用的ES组件,但是不是所有业务都具有很大的数据量。当数据量不是很大的时候,也可以通过Mysql 自带的ngram分词器进行实现,具体的步骤如下:
- 创建表的全文索引:例如:
— CREATE FULLTEXT INDEX ft_index ON sys_user (nickname) WITH PARSER ngram
- 语法
- 数据如下
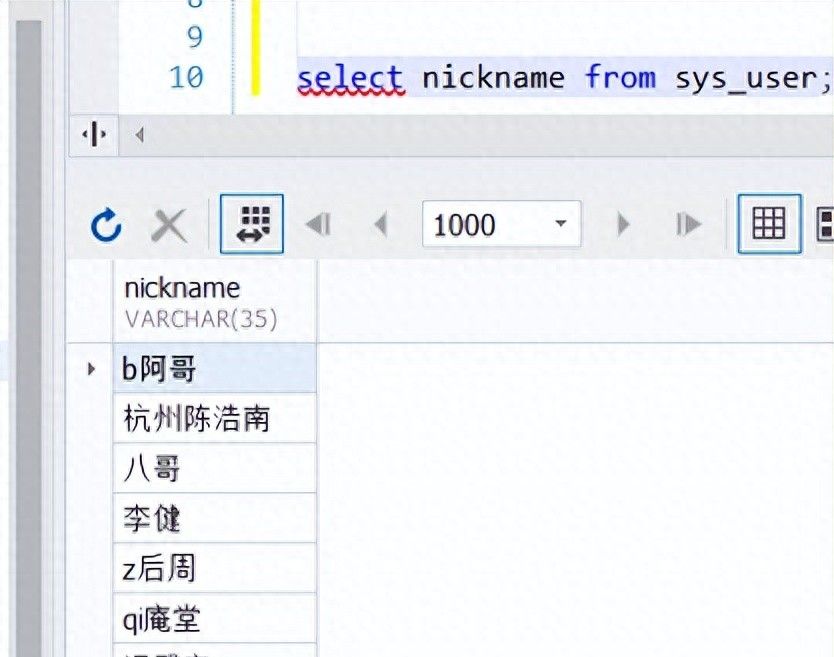
1:select nickname from sys_user WHERE MATCH (nickname) AGAINST (‘九歌汉武帝’);
结果:
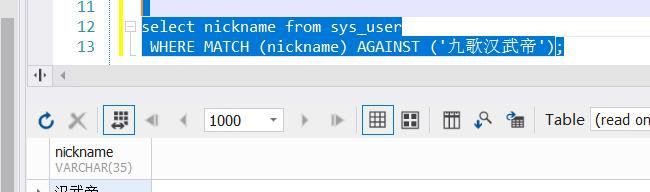
2:使用布尔模式:IN BOOLEAN MODE,+和-操作符分别指示一个单词必须存在或不存在,才能进行匹配,’危机*’,则表明匹配危机开头的记录
select nickname from sys_user WHERE MATCH (nickname) AGAINST (‘+九歌 -汉武帝’ IN BOOLEAN MODE)

- 注意
通过全文索引、配合ngram全文解析器,Mysql5.7之后可以实现对中文语义分词检索,在数据量不大且分词所以的字段是短文字段的情况下足够满足我们业务需要,无需上ES全文检索引擎
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...






