
24–48GB 一卡也能把 7B 训出可用助手?我把复杂流程拆成了工程化步骤和避坑清单
许多人一接触模型微调就慌了:显存不够、超参像迷宫、训练崩溃不敢动手。我身边有同事小王和朋友张姐,刚开始都是白热化的焦虑,他担心钱花了模型没用,张姐则怕数据一处理就乱套。说实话,我也经历过类似的夜晚,但把整个流程当成工程拆解后,焦虑反而变成了可控的窗口期——你需要的是一张清晰的流程图和几条反复验证的操作习惯,而不是神秘的黑盒子。
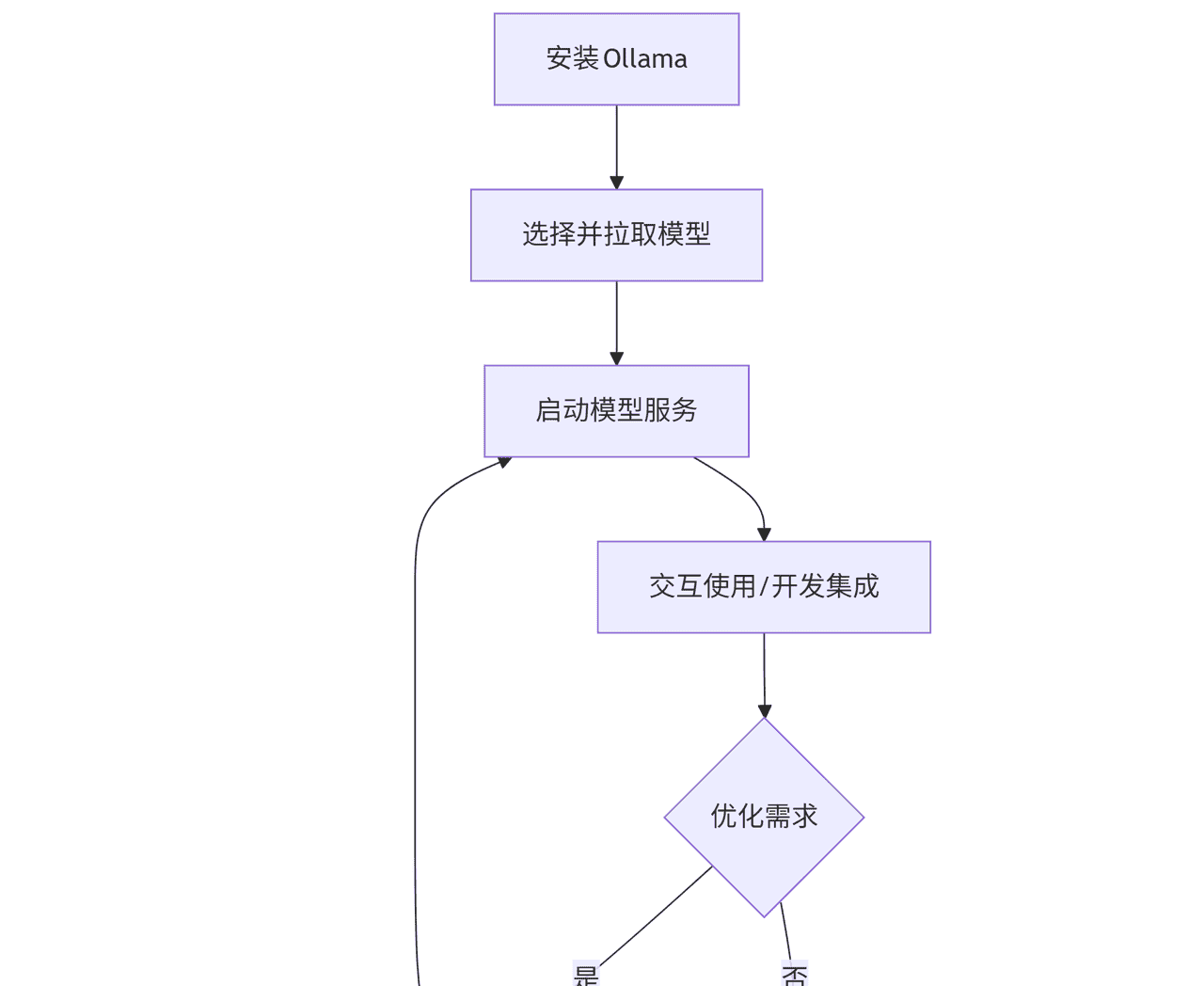
把复杂的训练流程先画成一条线会舒服许多:大模型从预训练开始,接着如果你有行业语料再做继续预训练让模型“听得懂”你的行业话语,随后用指令微调(SFT)教它“按指令办事”,再用偏好对齐方法(像 DPO/ORPO/KTO)把回答风格往你想要的方向拉,最后用强化学习对齐(PPO 类方案)做策略层面的精细调整。可复用的工具和模板很重大,Hugging Face、TRL、PEFT 这些库是写代码流的基石,而 ms‑swift 则是想快速落地、用 CLI 一键跑通流程的捷径。记住,LoRA/QLoRA 可以显著降低显存门槛,但合并权重、选择 target_modules 这些细节直接影响后续部署的便利性。
如果你的资源有限,实际可操作的选择很明确:SFT/QLoRA 在单卡 24–48GB 上一般够用,关键是把 batch 调小并开启累积梯度,合理设置 packing(group_texts)来提高吞吐。QLoRA 的经验区间我见过比较靠谱的配置是 r=16/32,学习率在 2e‑4 到 5e‑5 之间,当然这要结合你的 batch 和任务目标调整。继续预训练最好用 base(非 Instruct)模型去做,步数不是越多越好,而是看语料覆盖和清洗质量,去重、去噪、脱敏必须到位,否则小数据反而拉低模型表现。
偏好对齐和强化学习对齐的取舍直接关系到训练成本和稳定性。DPO 这类对比优化对学习率超级敏感,一般把 lr 控制在 5e‑6 到 2e‑5 更稳;PPO 类方法能在策略层面逼近更理想的行为,但对 Reward Model 的设计、target_kl 的限制和显存要求都更苛刻。我的提议是先用 DPO 或 ORPO 做“低成本”的风格校准,等有稳定的评价函数和更多算力时再尝试 PPO,并思考把 PPO 的参数化也做成 LoRA 形式以节省显存。
关于工具选择,ms‑swift 的确能把许多繁琐的命令合并成一行,适合想快速验证想法的团队;而 Hugging Face + TRL + PEFT 的组合给你最大的可控性和可复现性,便于调试细粒度问题。实务中我一般把 ms‑swift 用于小规模试验和同事演示,把核心实验放到 HF/TRL 流程以便做日志、版本控制和结果可追溯。别忘了先在本地跑 swift -h 或查看你当前版本的协助参数,有时候同一工具不同版本的 CLI 参数会有差别。
常见的那些坑真的会让人抓狂:chat_template 不一致会导致 label 错位,SFT 时要确保 prompt 部分被标为 -100,只有 assistant 段落有 label;max_length 截断和模型的 rope/scaling 参数不一致会让生成时句子莫名其妙断开;LoRA 的 target_modules 名称在不同架构里可能不同,遇到问题先用 print(model) 看清楚层级。另外,数据质量最重大,小量的不良样本会拖后腿,统计样本分布、人工抽检和对抗样本检查能省下许多无谓的训练时间。
把模型推向生产又是另外一门学问。部署时可以思考 vLLM 来提升吞吐,LoRA 热插拔让模型在不同任务间切换更方便。量化是降成本利器,AWQ/GPTQ 离线量化和 bitsandbytes 在线 8/4bit 都值得试,但要在离线评测上把 hallucination、拒答率、延迟这些指标跑一遍后再上线。蒸馏成小模型用于边缘部署也很常见,既能降低算力要求,又能延长服务寿命。
让我说个真实的案例:我同事小王有一张 A100 40GB,他先用 QLoRA 在一份包含两万条行业问答的数据上做 SFT,r 设为 16,lr 3e‑5,batch 很小但开了累积,最后合并 LoRA 权重并做 8bit 量化后上线,用户交互延迟显著下降,张姐则在做偏好对齐时用 DPO 并把 lr 降到 8e‑6,最开始训练很不稳定,后面把数据里的 prompt/rejected 对做了更严格的筛选和去噪,效果才上来了。说实话,看她夜里调参的背影,我才真正体会到“工程化”二字的耐心和厉害。
如果你目前需要一个简短可落地的路线图,先从数据做起:清洗、去重、脱敏,按照 messages 格式构造样本并确保训练/推理模板一致,然后判断是否需要继续预训练,如果语料多且专业就做几万步的领域自适应;接着用 QLoRA 做 SFT,r 从 16 开始尝试,learning_rate 在 2e‑4 到 5e‑5 里调整,batch 小并开累积;有偏好数据就做 DPO,把 lr 降到 5e‑6~2e‑5;需要策略优化再上 PPO,但记得做 target_kl 控制并思考用 LoRA 化的 PPO 节省显存;最后合并 LoRA、做量化和离线评测,再上线小范围灰度观察拒答率和幻觉率,逐步放量。
别把模型训练当成魔法,它更像一项需要耐心、重复试验和细节管理的工程。我觉得你只要把每一步当成一个小实验并写下可复现的日志,长期看回报会远大于临时的焦虑。你目前的 GPU 配置、数据规模和最终想把模型做成什么样的产品?说说你的资源和最大担心,我可以按你的情况给出更具体的超参数和操作提议,你目前最想解决的那个问题是什么?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











