
一、前序
大型语言模型(LLM)一般分多个阶段训练,包括预训练及若干微调阶段(如下所述)。虽然预训练成本高昂(即数上百万计算开销),但相比之下微调LLM(或执行上下文学习)成本极低(仅数千元或更低)。鉴于高质量预训练LLM(如MPT、Falcon或LLAMA-2)已广泛免费可用(包括商用),我们可通过在相关任务上微调LLM构建多种强劲应用。

二、监督微调(SFT)
监督微调(SFT)是近期AI研究中最广泛使用的LLM微调形式。该方法通过精选高质量LLM输出数据集,使用标准语言建模目标直接微调模型。SFT具备简单/低成本优势,是校准语言模型的有效工具,因而在开源LLM研究社区及其他领域广受欢迎。本概述将阐释SFT原理,综述相关研究,并提供仅需数行Python代码即可实践SFT的范例。
Transformers库本文代码基于transformers库实现。该深度学习库功能强劲,且提供丰富教程与文档,是深度学习及LLM项目的实用学习资源。

语言模型训练一般分三阶段进行(见上文)。第一进行预训练——这是迄今算力消耗最大的阶段;随后进行校准,一般采用三步框架(见下文):监督微调(SFT)与基于人类反馈的强化学习(RLHF)。
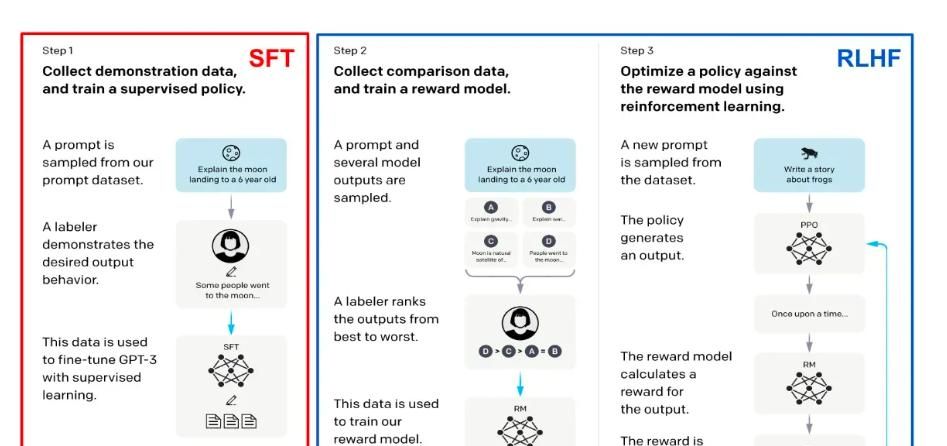
上述步骤构成多数最先进LLM(如ChatGPT或LLaMA-2[3])的标准化训练流程。SFT与RLHF相比预训练算力成本低,但需构建数据集——高质量LLM输出或人类对LLM输出的反馈——其过程可能耗时费力。
应用LLM解决下游任务时有时需额外操作。具体而言,可通过领域微调或上下文学习进一步定制模型(见下文)。领域微调仅需在任务相关数据上继续训练模型(一般采用类似预训练/SFT的语言建模目标);而上下文学习则向模型提示中添加额外语境或示例作为解题依据。

三、何为校准?
上文多次提及的”校准”(alignment)是核心概念。预训练语言模型一般无实用价值——其输出往往重复且无效。为使模型实用化,需将其行为校准至符合人类期望:即不生成最可能的文本序列,而是生成用户期望的文本序列。
通过前述SFT与RLHF的三步框架实现的校准,可引导LLM形成多种行为特性。一般训练者会选定一个或多个核心校准标准,常见包括:提升指令遵循能力、抑制有害输出、增强实用性等。例如LLaMA-2[5]的校准目标为:i) 有用性 ii) 无害性/安全性(见上文)。
四、何为SFT?
监督微调(SFT)是LLM校准流程的首步,其机制极为简明:
- 精选高质量LLM输出数据集(本质是模型正确行为的范例,见下文)
- 基于这些范例直接微调模型
“监督”特性体目前:我们收集的是模型应效仿的范例数据集,微调过程中模型将学习复制这些范例的特定风格

- 与下一词元预测的关联
值得注意的是,SFT与语言模型预训练并无本质差异——两者均采用下一词元预测作为底层训练目标!核心区别在于数据来源:预训练使用海量原始文本数据,而SFT采用高质量LLM输出的监督数据集。每次训练迭代中,采样若干范例后基于下一词元预测目标微调模型。一般该目标仅作用于每个范例中LLM输出对应的部分(如附图中响应内容)。
- 技术起源
含SFT与RLHF的三步校准流程最初由InstructGPT[2]提出,该模型系ChatGPT的先驱姊妹模型。鉴于InstructGPT与ChatGPT的成功,此三步框架已成标准化方案并广泛应用于后续语言模型。基于SFT与RLHF的校准方法现已成为研究与实践的核心手段。
- SFT之前的微调
尽管SFT近期盛行,语言模型微调实为长期主流方法。例如GPT[7]直接在评估任务上微调(见下图);仅编码器语言模型(如BERT[8])——因其不常用于生成任务——几乎完全依赖微调解决下游任务。此外,部分LLM采用与SFT略异的微调方案:如LaMDA[9]在多类辅助任务上微调,Codex[10]则在代码语料库执行领域微调(即不同数据上的增量预训练)。
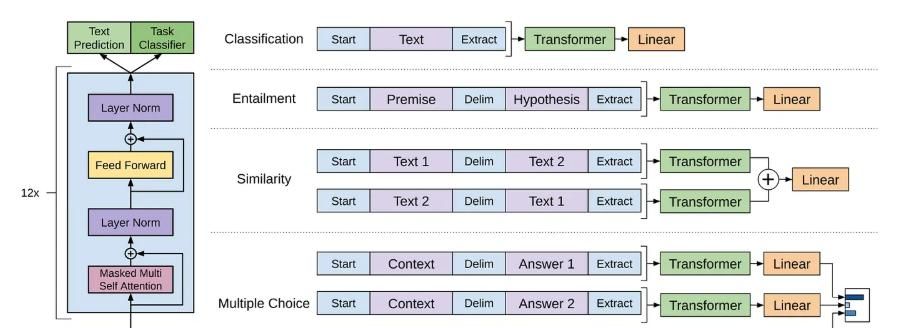
值得注意的是,SFT与常规微调略有不同:典型深度学习微调旨在使模型掌握特定任务能力,但会导致模型专精化而丧失通用性——成为”狭隘专家”。相比通用模型,微调后模型在特定任务上精度更高(如GOAT[11]),但可能丧失解决其他任务的能力。相反,SFT作为语言模型校准的核心环节(包括通用基础模型),其微调目标是使模型习得正确风格或行为模式,而非解决具体任务,故不会削弱其通用问题解决能力。

SFT具备易用性优势——其训练过程与目标同预训练高度类似。此外,该方法在校准效果上极为高效,且算力成本远低于预训练(即降低100倍以上)。如上图所示,仅使用SFT(不依赖任何RLHF)即可显著提升模型的指令遵循能力、准确性、连贯性及综合性能。换言之,SFT是提升语言模型质量的高效技术。但需注意其存在局限,以下考量缺陷:

SELF-INSTRUCT方法概览。流程始于小型任务种子集(即任务池),从中随机采样任务并输入现成语言模型,使其生成新指令及对应实例;随后过滤低质量或重复生成内容,将合格结果添加至初始任务库。最终数据可用于语言模型自身的指令微调,从而提升其遵循指令的能力。图中任务均由GPT3生成。
构建数据集的质量直接影响SFT效果。若数据集包含多样化范例集,能准确覆盖所有相关校准标准并表征语言模型预期输出,则SFT成效显著。不过如何确保SFT数据集全面涵盖校准流程中需鼓励的所有行为?仅可通过人工精细检查实现,但存在两大缺陷:i) 不可扩展 ii) 成本高昂。替代方案如自动化框架生成SFT数据集(例如self instruct[12],见上图),但数据质量无法保证。因此,SFT虽流程简单,却需构建高质量数据集——此过程颇具挑战。

引入RLHF可获额外增益。即使已构建高质量SFT数据集,近期研究表明执行RLHF仍能进一步提升效果。换言之,仅通过SFT微调语言模型并不充分。此发目前LLaMA-2[5]报告中尤为显著(该模型同步采用SFT与RLHF校准,见上文)。LLaMA-2的SFT阶段使用人工精选的大规模对话数据集(总计27,540范例)以确保质量与多样性。尽管采用优质大数据源进行SFT,追加RLHF仍在有用性与安全性(即LLaMA-2校准标准)方面产生显著提升;详见下图。

五、代码实现
以下位实现SFT监督训练的完整代码示例。
from transformers import AutoTokenizer, AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments
# 1. 加载预训练模型与分词器
model_name = "facebook/opt-350m" # 可替换为LLaMA-2等模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. 加载数据集(示例使用IMDB,需替换为您的SFT格式数据)
dataset = load_dataset("imdb", split="train") # 确保数据集包含"text"字段
# 3. 配置训练参数
training_args = TrainingArguments(
output_dir="./sft_results",
per_device_train_batch_size=4, # 根据显存调整
gradient_accumulation_steps=4, # 模拟更大batch size
learning_rate=2e-5,
num_train_epochs=3,
fp16=True, # A100/V100开启混合精度
logging_steps=100,
save_strategy="epoch",
report_to="none"
)
# 4. 初始化SFT训练器
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=dataset,
dataset_text_field="text", # 指定文本字段
max_seq_length=512, # 根据模型调整
packing=True # 动态打包提高效率
)
# 5. 执行训练
trainer.train()
# 6. 保存微调后模型
trainer.save_model("./sft_final_model")© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录










收藏了,感谢分享