
这是一篇比较有价值的文章,必定要收藏起来,许多刚刚入职的新手或者从事网络安全研发的人员,对协议解析并不太熟悉,因此,我想写一篇关于HTTP协议解析的文章,来让更多的人了解一下什么是协议解析,协议解析的过程中,如何避免黑客给你挖的坑,千万别跳进去,想写一篇有价值的东西,给我的粉丝以及广大对技术有追求的网友,当然,会有许多人说,许多开源的软件,列如,nginx都是现成的,但是,我想说,随着市场的需求不断增加,会对协议解析提出更多的要求,如果我们不去深入研究HTTP的协议解析,很难去随机应变,这种对协议解析这的文章,网上很少见的,所以,大家必定要、必定要、必定要收藏这篇文章,没准哪天就用得上它,如果觉得我还对你有点用,就请用您尊贵的手指关注一下我,哈哈哈,开个玩笑。
既然我们的目的是解析HTTP协议,那么就必须了解一下HTTP协议的格式,为了能够带着大家了解HTTP协议的格式,我特意搭建了网络环境,来抓取HTTP数据包,网络环境的拓扑如下:
在PC机上,安装一个VMware Workstation,然后在VM上,装了一个windows7的系统,在该系统上装了一个http.exe的软件,充当HTTP服务器,windows7系统的虚拟网卡设置为NAT模式,这样PC主机可以直接访问windows7系统中的http.exe服务,我们在windows7上,通过cmd窗口,敲击一下ipconfig -a 命令,来看一下windows7系统的IP地址:
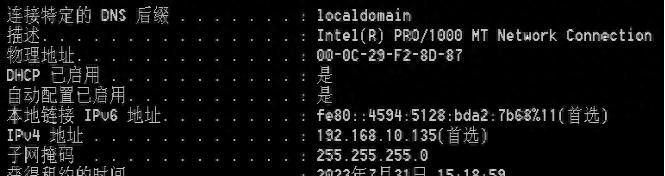
windows7 IP地址
我们知道了,windows7的IP地址是192.168.10.135,我们的http.exe这个服务软件就装在这个系统上,那么用我们自己的电脑,来ping一下192.168.10.135 这个地址,如果能够ping通的话,就说明我们的环境基本搭建成功了,我们在cmd窗口,执行ping 192.168.10.135 这条命令,看看效果:
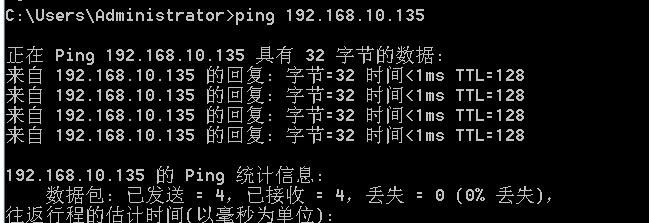
查看windows7是否可以ping通
看到了我们最希望看到的字样,%0 丢失,没有丢包,这样我们就可以访问192.168.10.135系统里面的http服务了,我们在电脑中,打开谷歌浏览器,输入http://192.168.10.135,并启动wireshark软件,进行抓包,整个过程如下所示:
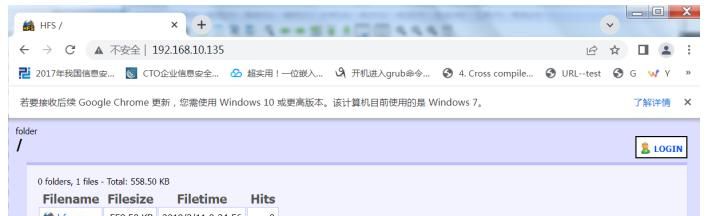
浏览windows7上的服务器
发现我们通过谷歌浏览器可以访问到192.168.10.135上的服务器,我们通过wireshark进行抓取http的数据包,这才是我们搭建环境的目的,就是获取http数据包,来看看http数据包长什么样子,见下图:
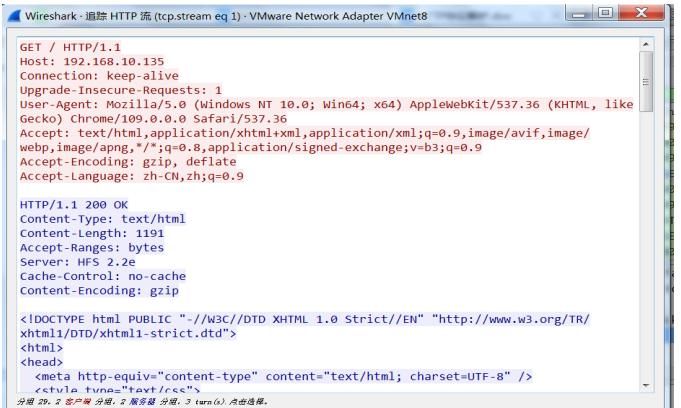
HTTP数据报文结构
可以看到wireshak抓取的http数据包,上面是HTTP请求包,下面蓝色部分是HTTP响应包,可以看到,浏览器发起的是GET请求,服务器成功回应了200 OK,说明交互过程是没有问题的,下面我们针对HTTP请求头来详细介绍一下,如何进行HTTP协议的解析。
我们把HTTP请求数据单独拿出来分析:

HTTP请求格式示意图
可以看到,HTTP请求头由两部分组成,第一个是请求行,另一个是请求头,所以,HTTP请求头的解析,就按照这两部分分别解析即可。
第一我们来看看HTTP请求行来如何解析:
GET / HTTP/1.1
可以看到,HTTP请求行分为三部分,第一部分为GET也就是HTTP方法,第二部分为/也就是URL路径, 第三部分为HTTP/1.1也就是HTTP版本信息,那么一目了然,就是先解析GET,再解析/,最后解析HTTP/1.1,这个想必大家都知道,那么我们一步一步的来分析:
1) 解析GET
许多人会觉得,不就是解析GET嘛,很简单嘛,直接从头取三个字符就完了呗,实则不是那么简单的,我们在解析GET方法时,必须要明确出GET的起始字符以及终止字符在哪,如果知道了起始字符和终止字符的话,就可以将两个字符之间的所有字符都当成是HTTP的方法,对于GET方法而言,起始字符是G,终止字符是T,关键就在于如何在HTTP请求行中找到G和T,下面重点来了,大家提起精神来。
我们观察HTTP请求行中,GET的起始字符是非空格字符,终止字符的后面是空格,因此,我们就找到了解析GET的方法。
第一遍历HTTP请求行,找到第一个不是空格的字符,这个字符就是GET中的G,然后继续往下扫描,遇到空格的位置就停止,那么这个空格的前一个字符就是T,这么说大家清楚了吗?是不是很简单呢。

请求行解析示意图
虽然按照这种方式,我们解析出了GET,但是我们作为协议解析的开发人员,应该时刻保持警惕,不要被黑客所利用,黑客常常将HTTP的方法写的超级之长,也就是永远让你找不到HTTP方法终止字符后面的空格,让你无休止的去解析下去,这样,你的内存慢慢的就被耗尽,因此,作为有着深厚功底的开发人员,这时在解析HTTP方法时,就应该留个心眼,不要上当,也就是设置个方法的上限值,我最多解析多长的HTTP方法,如果超过此长度,我认为是有问题的,这个时候,该阻断阻断,该怎么样处理就怎么处理。

黑客的攻击手段
如果黑客给你发送的数据,就是让你找不到空格,这时,你就不要继续往下找了,解析程序要有个上限,超过上限后,不继续解析了,这样你就完美的避开了黑客的陷阱。
2)解析 /
/ 我们一般叫URL的路径,/ 表明我们要获取网站主页,解析/ 和解析HTTP方法,实则原理是一样的,刚刚讲到解析GET时,我们刚好扫描到空格的位置,我们开始向后扫描,也是要找到起始字符和终止字符,最后将起始字符到终止字符的这部分内容作为URL的路径部分,找起始字符和终止字符的原理是一样的,就是扫描到第一个不是空格或者制表等字符时,遇到的第一个字符就是起始字符,继续向后扫描,遇到空格或者制表符停止,空格或者制表符前面的字符就是终止字符,这样我们就拿到了URL的路径。
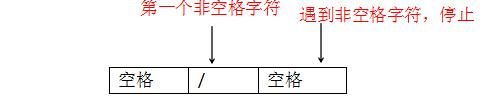
HTTP URL路径解析示意图
备注:如果我是黑客的话,我会将URL路径部分变得超级长,然后URL路径部分后面不给你空格,这样,如果你的程序中,不停的在找空格的话,你的解析程序就会陷入死局,卡在解析的地方,也会不断的消耗你的内存,因此,我们作为解析URL路径的开发人员,脑子里就要有这种概念,要防着被黑客挖陷阱,所以,我们不能允许程序无休止的去找空格,要有个限制,也就是最多解析多长的URL路径,这样我们才不会上了黑客的当。
2)解析 HTTP 版本信息
前面讲了如何解析HTTP方法、URL路径,实则,HTTP版本的解析和前面的原理一样,就是找到HTTP版本信息的起始字符和终止字符,这样终止字符和起始字符之间的内容就是HTTP版本信息,那么目前就说说如何找起始字符和终止字符。
起始字符很好找,就是扫描到第一个非空格或者制表符的位置,就是起始字符,终止字符的查找稍微不一样,找到起始字符后,然后,向后扫描,遇到
后,就停止,那么
前面的字符就是终止字符,这下清楚了吧。

HTTP版本信息解析示意图
解析版本信息的话,就相对来说容易一些,我们就检查是否符合HTTP/1.1这种格式即可,然后,最后我们要看看是否遇到了
这种字符,遇到后,我们的请求行就解析完毕了,当然我们在查找
时,也要有必定的长度限制,不能无休无止的找
,不要上了黑客的当,当找
时,扫描的过程中,如果扫描的字节数超过了长度限制,我们此时就不要继续解析了,要么放行,要么阻断。
未完待续,后续会在此基础上,更新HTTP请求头部的解析。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录








收藏了,感谢分享