把两套东西合起来用,能把回答的准确率和完整性都往上拉一大截。许多项目里,改成GraphRAG后,复杂问题的命中率明显高了;客服类场景响应更稳,用户抱怨少了。说白了,就是既能覆盖大量文本,又能把逻辑关系弄清楚,效果就不一样了。
有个家电公司的例子挺说明问题。售后机器人上线后,用户问“冰箱BCD-258WDPD的耗电量是多少?”这种带具体型号的问题,原来单靠向量检索常常匹配不到准确片段,命中率只有五六成。后来他们把关键词检索(BM25)和向量检索合并,关键词权重给到60%,向量40%。结果准确率从55%上到92%,投诉量降了三成多。另一个媒体机构把历史稿件做成知识库后,记者查资料的速度提升了60%,写稿效率明显变快。像这种实际很直观,能看得见的收益。
先讲图和向量是怎么一起用的。GraphRAG的思路不复杂:把文本的“语义片段”放在向量库里,当需要大段语义支持时用向量检索;同时把关键实体和它们之间的关系抽出来,存成子图,放到图数据库里。当用户的问题需要关系推理,就从图里走一遍;要是偏概念理解或长文本的总体把握,就拿向量片段给模型。两边各取所长,最后合起来丢给大模型,让它生成答案。微软研究院在2024年有个GraphRAG的项目,把这个套路做成了可落地的实现,业界反响挺大的。
向量那一套,怎么搭比较快也比较省事。流程大致是:把各种非结构化文档(PDF、Wiki、Markdown、技术手册等)切成若干段,按语义尽量不拆断,然后用Embedding模型把每段换成高维向量。像OpenAI的text-embedding-ada-002、或者本地的sentence-transformers这类模型,都常被用来做这一步。向量存到专门的向量数据库里,列如Pinecone、Milvus、Weaviate这类。小项目也可以用PostgreSQL加pgvector扩展来存。检索时把用户的问题也编码成向量,计算类似度,距离近的片段就返回。优点是模糊匹配能力强,用户即便用的词不一样,也能找到相关内容;构建速度快,自动化程度高,不用大量人工标注,几天到几周能上线基本系统。缺点也很明显:切片丢掉上下文会让LLM生成时迷路,向量层本身不擅长做复杂关系推理,解释性差——你很难直接告知用户“为什么取了这一段作为依据”。
切片这事儿看着简单,实操很讲究。切得太大,会把无关信息搅在一块,检索结果变模糊;切得太小,又可能把完整语义拆散,丢了上下文。对技术手册类比较规整的文档可以按章节/段落切;新闻或评论类的文档更适合用语义窗口切法,尽量保证每个片段是个完整的信息单元。LangChain、LlamaIndex这两套工具在数据加载、切片、索引上能帮不少忙。别忘了向量数据库的索引类型也会影响检索速度和质量,部署时要结合数据量和查询并发做选型。
再说知识图谱那边。图谱把知识做成节点和边,主-谓-宾的三元组是标准格式。把文本里的实体抽出来(NER),再判断它们之间的关系(RE),把这些信息结构化后存成图。图数据库常见的有Neo4j、NebulaGraph、JanusGraph,查询语言常见Cypher或Gremlin。图谱的强项是关系表达和推理,能做多跳推理,列如从“A是B的父亲”和“B是C的父亲”推出“A是C的祖父”。在金融风控里,这一点特别有用:把用户、账户、交易、人脉等做成一张大网,能发现那些单靠行为特征看不到的团伙欺诈。某银行用知识图谱找出了一起利用多重虚假身份贷款的诈骗团伙,避免了上千万元的损失。供应链领域也很适合:当某零部件供应商产能不足,图谱能快速找到替代供应商并评估影响范围。推荐系统里,图谱能把用户-商品-属性关系连起来,既提高推荐准确率,也能给出“为什么推荐”的解释。用了图谱后,某平台的推荐点击率和转化率都有明显提升。
构建图谱要花功夫。得先做本体设计(Ontology),明的确 体和关系的类型、属性,以及它们之间的约束。这一步决定图谱的骨架。接着是信息抽取,要用NER、关系抽取、属性抽取等技术。工具上可以参考DeepDive、SpaCy、OpenNRE、REBEL这些,做完抽取还要做清洗、融合,解决命名不一致、重复实体等问题。存储和查询靠图数据库,Neo4j上手容易,适合中小规模;NebulaGraph、JanusGraph这种适合大规模分布式场景。总体来讲,图谱造价高,人力和时间投入都很大,维护也复杂:新增实体或改动规则时,要思考对整体结构的影响,不能随意改。
把两者放在一起比对一下,会更清楚一些。向量库是扁平的高维向量空间,靠距离体现类似性,适合海量非结构化文本的快速检索,构建门槛低,但逻辑关系表达弱、可解释性差、复杂推理乏力。知识图谱是节点边构成的网络,结构化程度高,擅长准确匹配和多步推理,便于解释,但搭建和维护成本高,处理大规模非结构化文本不够灵活。不同场景该怎么选,得看你要解决的问题是“广度+模糊理解”还是“深度+准确关系”。
在实践里,许多团队的做法是先上向量知识库,后续按需扩展。缘由简单:速度快、成本低,能先把产品做起来,验证有没有实际需求。上线后出现的问题再迭代,列如遇到专有名词、型号等准确匹配需求,可以先加混合检索,把BM25之类的关键词检索和向量检索按权重融合。那家电公司就是这么做的:把产品型号走关键词,语义相关性靠向量,两者权重调好,立竿见影。再往后,当业务需要处理复杂多跳问答、推理型查询,或者需要把业务逻辑可解释化时,就可以思考把图谱引入,逐步构建GraphRAG。
技术选型上还有一些细节。Embedding模型的选用影响语义表明质量。OpenAI的text-embedding-ada-002目前用得广,维度高,表现也稳;不过对隐私敏感或成本有限的团队,可以思考本地的sentence-transformers系列。向量数据库的选型按需求来:小规模快速验证可以选Pinecone或托管服务;要自己掌控和扩展性强的,Milvus和Weaviate是常见选择。图谱那边,Neo4j适合快速开发和分析;NebulaGraph适合大规模部署。工具链方面,向量库方面LangChain和LlamaIndex能把文档加载、切片、Embedding、检索串起来;图谱方面Apache Jena、Protégé在本体设计和语义网方面很有用,DeepDive、SpaCy等可做抽取。
构建时要注意的问题不少。向量检索会遇到“切片丢失上下文”的情况,导致LLM生成时缺信息。图谱则会面临“构建成本高、覆盖不全”的窘境。把两者结合起来可以互补:图谱提供关系骨架,向量库提供语义填充。GraphRAG里有个常见做法是用LLM从文本里抽取局部子图,只存那些关键实体和关系,避免把图谱做成全覆盖的大工程。检索时同时调用两层结果,再把它们合成给生成模型,结果往往比单一层好不少。
多跳问答的例子说明了图谱的必要性。像“埃隆·马斯克第一任妻子的职业是什么?”这类问题,靠语义类似度很难一步到位。图谱可以先定位“埃隆·马斯克”的配偶信息,再找到相应人物的职业属性,最后给出答案。有项目把复杂问答任务从45%的命中率提升到82%,差别很明显。
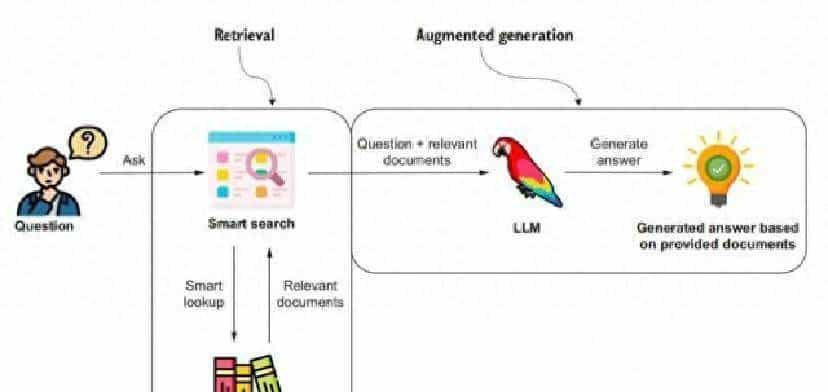
回到起点要说的问题:为什么要搞这些东西?核心缘由是大语言模型会出现“幻觉”——也就是把看上去合理但不真实的信息生成出来。这个问题在金融、医疗这些领域后果严重。金融里可能给出错误投资提议,医疗里可能输出误导性诊断参考,轻则体验差,重则会带来实质损失甚至威胁生命。为了解决幻觉,检索增强生成(RAG)被提出,让模型在生成前先去现实的知识源里查证。外部知识存放在哪里,用什么检索方式,直接决定了RAG能不能把幻觉压下去。知识库和知识图谱就是两条主线,各自解决不同的短板,合起来就是目前许多项目的最佳答案。你看着办,先把文本塞进向量库,等需求变复杂再慢慢把关系抽出来,别一开始就把图谱当万能钥匙,那活儿既贵又慢。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...