
机器学习顶会 NeurIPS 2025 公布了今年的评审结果,其中来自阿里通义千问 (Qwen) 的「Gated Attention for Large Language Models」成为国内唯一一篇最佳论文。

这也是今年获奖论文中唯一一篇与注意力机制有关的。在大家卷数据、卷算力、卷 Context Length 的时候,千问团队这次揭示了一个门控注意力对模型训练和性能影响的秘密,而论文本身也展示了对 Transformer 底层的 Attention 结构做一点「微小的改动」的方案——在 Softmax Attention 后面,加上一个简单的门控 (Gate)。
在 Transformer 统治天下的今天,把 LSTM 里的经典思想「门」装回去,竟然产生奇效。
NeurIPS 的 Program Chairs 在最终评审意见中给出了极高的评价:
我甚至可以说,这是我今年读过的最好的 5 篇论文之一。
那么,这个看似简单的「门控」,是如何发挥作用的?
Attention 机制的「强迫症」
要理解 Qwen 的改善,第一得理解原版 Transformer 的一个隐形缺陷。
标准的 Attention 机制核心是 Softmax。Softmax 函数的核心作用是将一组任意实数转换成一个概率分布,其所有输出值的和严格等于 1。
这种特性被称为归一化。也就是无论输入的 Query 和 Key 匹配度有多低,Softmax 强制所有分数的总和必须为 1。
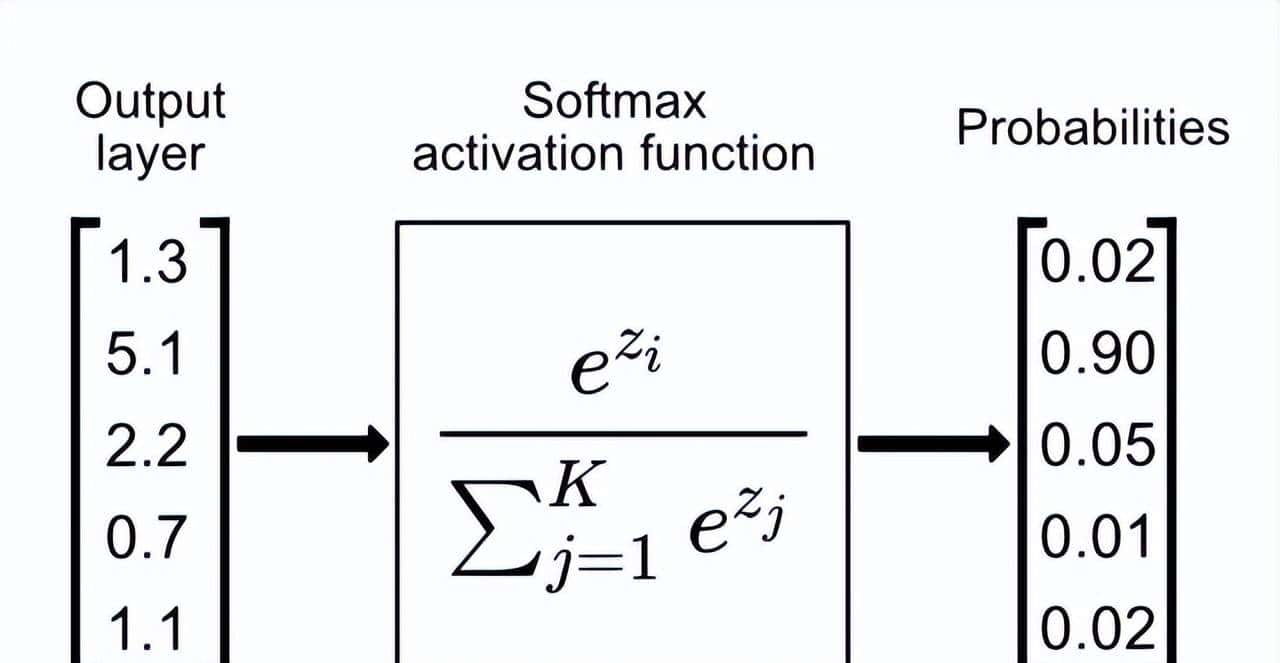
这种强制的归一化约束迫使模型必须分配注意力,即使当前的 query 找不到有意义的信息,模型也会强行把分数分配给一些无关紧要的 Token。
这就带来了两个问题,Attention Sink 和 Massive Activation。
模型在处理长文本时,首个 Token 莫名其妙地拥有了极高的注意力权重,严重干扰了模型的长距离推理能力。
这就是大模型领域著名的 Attention Sink (注意力池) 现象。
换句话说,模型并非真正认为第一个 Token 最重大,而是为了满足 Softmax 必须找到一个固定的地方来「暂存」无处安放的注意力分数(一般是<BOS>或首 Token)。
同时,为了维持这种不合理的注意力分配,模型内部的某些神经元会产生数值极大的激活值。
这在训练模型的时候是十分危险的:
- 梯度爆炸:当我们使用 BF16 或 FP16 这种低精度浮点数节约显存时,巨大的激活值在反向传播中可能导致梯度也变得极大,超出 BF16 的表明范围,导致 Loss 突然变成 NaN,训练直接崩溃。
- 量化灾难:当我们需要将模型量化 (列如 INT8) 时,为了兼容那些少量数值极大的激活值,就必须把[0, 1000]的范围映射到[0, 255]。结果就是,那些 0.1、0.2 的微小但重大的特征,在量化后被压缩到 0 或 1,精度损失惨重。
这就是 Softmax 强迫症的另一个副作用:Massive Activation(巨量激活)。
之前大家也尝试过解决这些问题,但一般都是「打补丁」。
而 Qwen 的思路是:既然 Softmax 被迫要输出分数,那我在它后面加一个门控 (Gate),给它选择的自由不就行了?
简单的改动,复杂的验证
门控思想由来已久,列如在经典的 LSTM 中,就是通过门控让模型忽略不重大的信息,记住重大的信息。
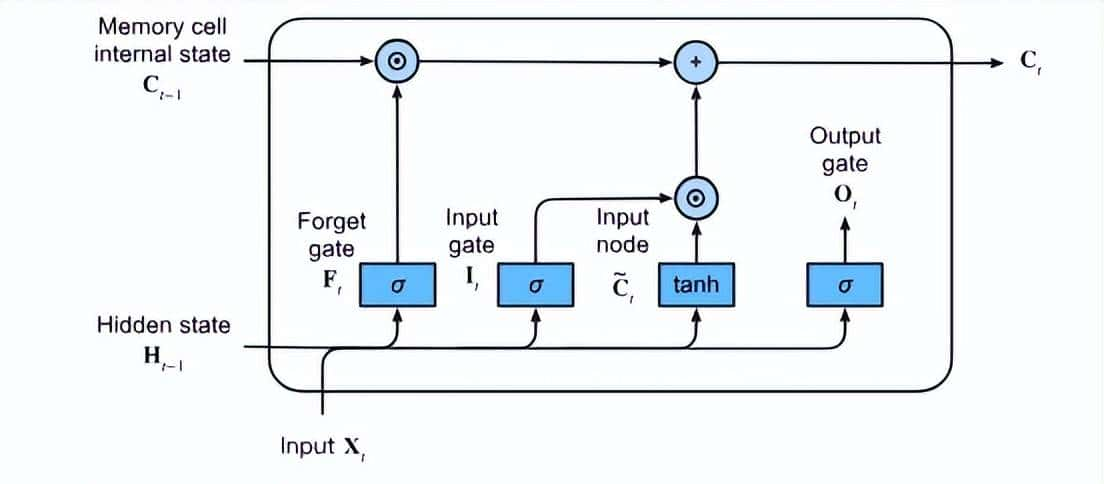
Qwen 团队提出的结构超级简单,他们称之为 Gated Attention。
核心思想是:在标准的 Scaled Dot-Product Attention (SDPA) 输出之后,直接乘上一个由 Sigmoid 激活函数控制的门控值。
用公式表达就是:Y ′ = g(Y, X, W_θ, σ) = Y ⊙ σ(XW_θ)
这里面的就是新增的「门」:
- σ就是Sigmoid 函数,能把任何数变成 0 到 1 之间的小数,作为「通过率」;
- XWθ就是用原始输入信息算出的一个控制信号;
- ⊙则代表「逐元素相乘」,就是把「初步信息汇总」和「通过率」对齐后,对应位置的数字相乘,如果通过率是 0.1,就意味着对应的原始信息只保留 10%。
你也许会问:「就这?加个 Sigmoid 就能最佳论文了?」
但问题在于,加在哪,怎么加,效果能否 Scale,这些都需要大量的实验进行验证。
换句话说,当我们有了一个 idea,如果设计实验去证明它的确是最优的?
Qwen 团队实则并不是直接拍脑门决定把门控加在 SDPA 输出后面的,而是做了极为细致的消融实验。
他们把 Attention 模块拆解后,找到了五个可以「加塞」的位置,分别进行了验证。
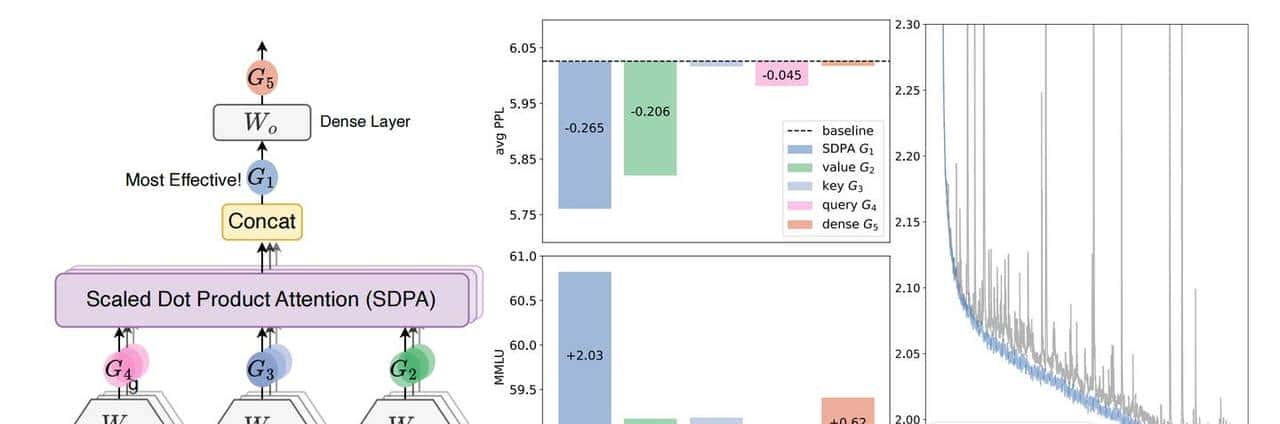
其中:
- G1(SDPA 输出后): 效果最好,同时解决了上述问题。
- G2(Value 后): 有必定效果,能缓解数值爆炸,但由于它与当前 Query 无关,所以没能解决 Attention Sink 的问题。
- G3(Key 后): 效果一般。
- G4(Query 后): 效果一般。
- G5(最终 MHA 输出后): 基本无效。
为什么偏偏是G1?
论文中也给出了线性代数解释,在标准 Attention 中,Value 投影矩阵和最终的输出投影矩阵是两个连续的线性变换:Output=(…(X⋅W_V))⋅W_O
两个线性变换(矩阵乘法)的复合,其结果依然是一个线性变换。由于 Attention Head 的维度(列如 128)一般远小于模型的隐藏维度(列如 2048),这个复合后的线性变换的「秩 (Rank)」会受到中间那个较小维度的限制。这就是所谓的 低秩瓶颈 (Low-Rank Bottleneck),它限制了模型的表达能力。
通过加入非线性的 Sigmoid 门控,就能极大提升了模型在低维空间的特征表达能力。
实验发现:
引入 Sigmoid 门控后,模型拥有了「拒绝权」,Sigmoid 的输出范围是(0, 1)。当模型发现当前这一步 Attention 没算出什么有用的东西时,后续的 Gate 可以直接输出一个接近 0 的值。
这一招,直接把噪音截断了。论文实验显示,加了门控后,首 Token 的注意力占比从 46.7% 骤降至 4.8%,基本治好了 Softmax 的强迫症。
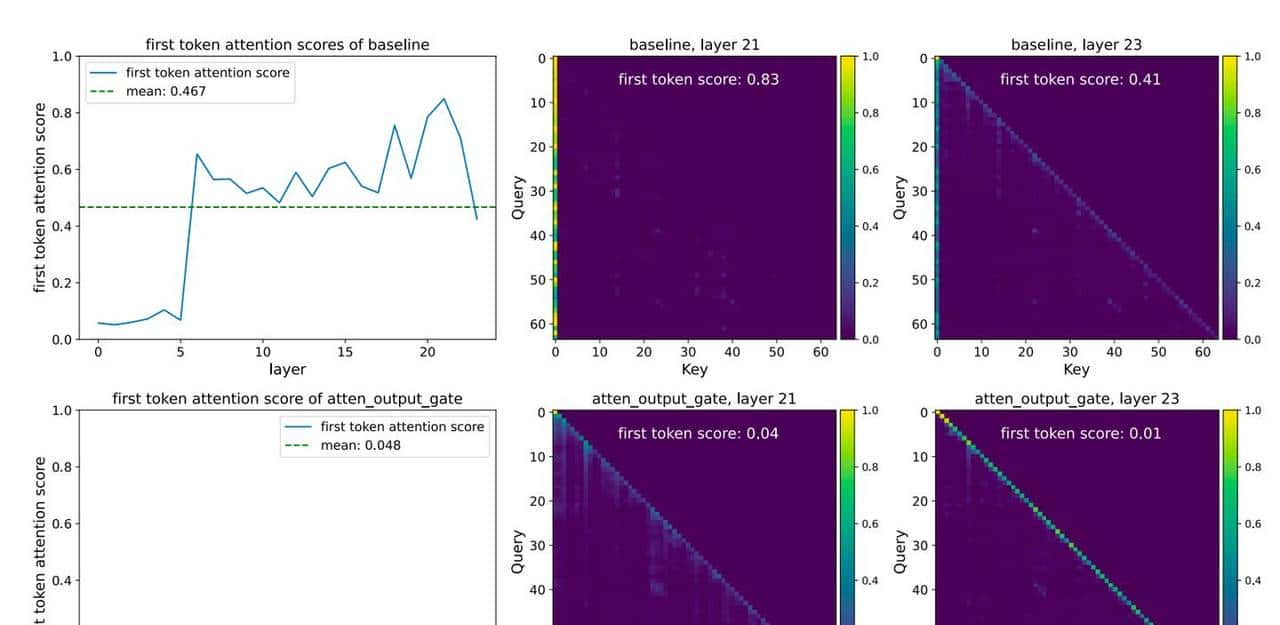
同时,Gate 具有极强的稀疏性(Sparsity),可以把之前异常大的数值压下来,实验数据表明,最大激活值从 1053 降到了 94。
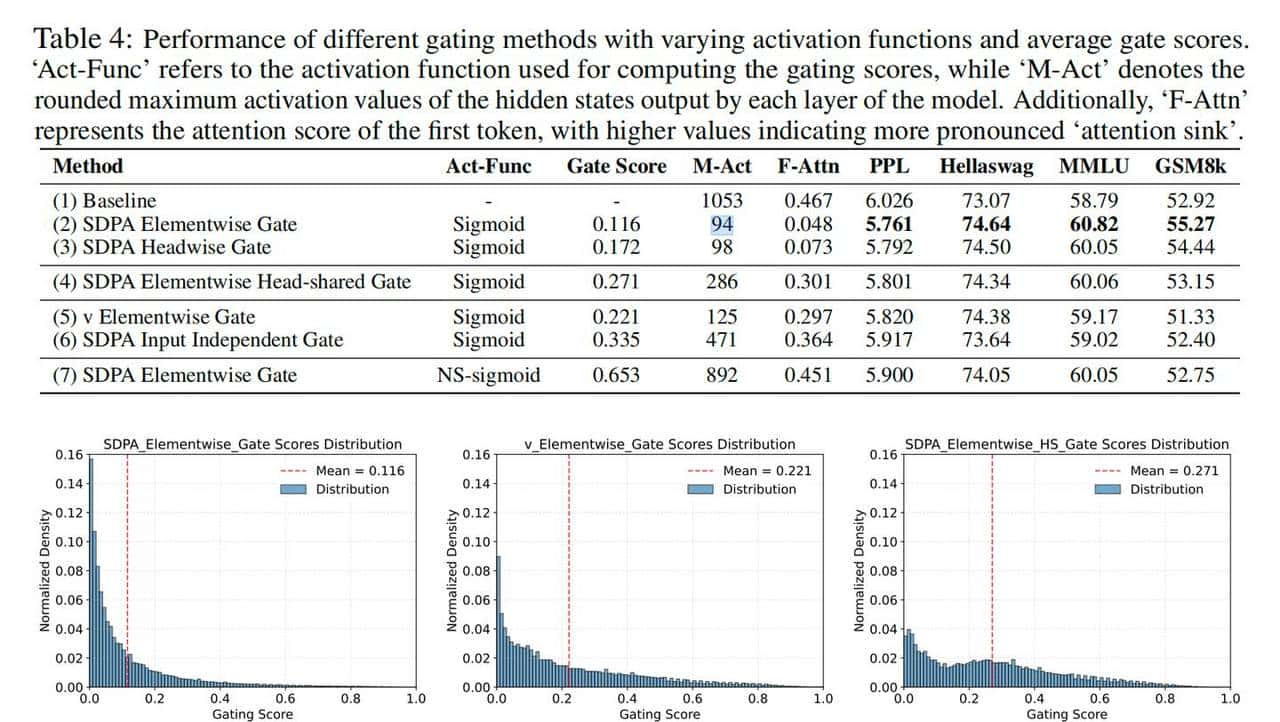
可以说,加了门控的模型,可以用更大的 Learning Rate 训练而不用担心梯度爆炸。
One more thing:Rebuttal 中的问答
除了内容之外,这篇论文的 Rebuttal 环节也很精彩,值得大家学习。
在论文最初的 4 份评审意见中,甚至有一位审稿人给出了「Borderline reject」,主要质疑是:
- 实验设置混淆:在验证门控能让模型在更大批次下稳定训练时,团队同时增加了训练 token 总量和 batch size,这引入了混淆变量。如何证明稳定性提升不是由于 token 更多了?
- 性能提升不「显著」:评审认为,0.2 的 PPL 下降并不算是「显著」的提升。
针对第一项质疑,Qwen 立即增加了新的实验:在固定的 400B token 数据上,分别测试了不同 batch size 和更高学习率下的表现。新实验结果表明,在基线模型由于学习率过高而崩溃时,带有门控的模型依然能稳定训练并取得更好性能。这有力地证明了门控带来的稳定性增益。
针对第二项质疑,Qwen 从多角度论证了 PPL 下降的意义,在 48 层的大模型上,把训练数据从 400B 增加到 1T(翻倍不止),PPL 才下降了 0.06。 而通过门控,PPL 直接下降 0.2,相当于节省了巨量的训练资源。
也正是经过了 Rebuttal 环节的打磨,这篇论文才最终成功地拿到了 6654 的分数。
小结
我觉得没有比评选委员会的评价更好的总结了:
这篇论文的主要发现是,通过在稠密(Dense)和专家混合(MoE)Transformer 模型的 SDPA 注意力操作后引入特定 Sigmoid 门控机制,可以持续提升使用 Softmax 注意力的大语言模型性能。这一结论得到了超过30项实验的支持——这些实验基于 15B 参数的 MoE 模型和 1.7B 参数的稠密模型,在 400B、1T 或 3.5T token规模的数据集上训练,测试了不同门控 Softmax 注意力的变体。论文还通过细致分析表明,作者推荐的这种门控形式能提升大语言模型的训练稳定性,缓解注意力模型中广泛报道的「注意力池」现象,并增强上下文长度扩展的性能。论文提出的方案易于实现,鉴于文中提供的关于LLM架构改善的大量证据,我们预期这一思路将被广泛采用。本研究代表了只有工业级计算资源才能支撑的重大工作量,作者对研究成果的分享(这将推动学界对大语言模型注意力机制的理解)尤其值得赞赏——特别是在当前LLM领域科学成果开放共享趋势减弱的背景下。
这篇论文之所以能打动 NeurIPS 的评审,并不在于提出了什么复杂的数学公式,反而是用一个十分简洁的改动,解决了最棘手的痛点问题(训练不稳定、长文本能力差),并用生产级的实验数据证明了这种方法的可靠性。
这可能成为 Transformer 架构的又一次性价比极高的标准升级,能够带来显著的性能和稳定性提升。
除了提出理论,Qwen 还明确表明:Gated Attention 已经在 Qwen3-Next 模型中得到验证。团队也保持了 Qwen 一贯的开源精神。代码、模型架构细节、失败的尝试和经验都毫无保留地做了分享。
在 AI 甚至开始出现「闭源回潮」的今天,Qwen 的这种开源精神更显得宝贵,或许这才是中国 AI 团队能站在世界顶会最高领奖台上的底气。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录


这个成果有点牛啊 直接可以落地的
收藏了,感谢分享