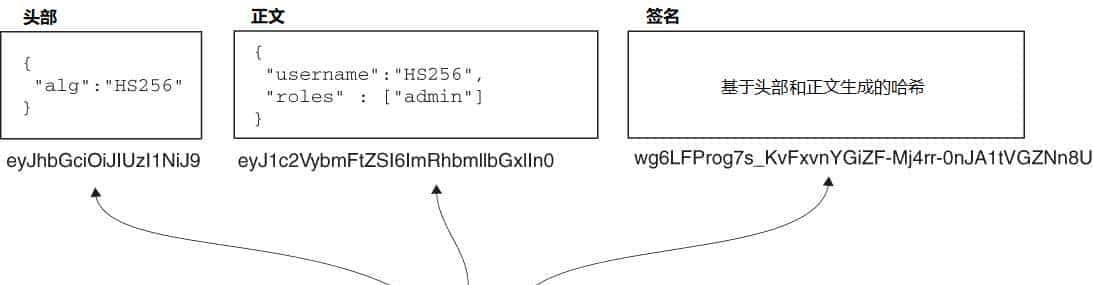
企业AI效能评估的关键:以“用户需求”为锚点的深度解构与实践指南
引言
背景介绍:AI项目的“冰火两重天”与效能评估的迷失
近年来,企业AI化已成为数字化转型的核心战略。据德勤《2023全球AI现状报告》显示,79%的企业已投入AI项目,但仅有23%的项目能持续产生业务价值;Gartner更指出,到2025年,60%的AI项目将因“效能评估与业务需求脱节”而终止。这种“高投入低产出”的困境背后,隐藏着一个被广泛忽视的核心问题:AI效能评估的锚点错位。
传统AI效能评估往往陷入“技术自嗨”的陷阱:算法团队沉迷于模型精度(如准确率、F1-score)、工程团队关注系统吞吐量(QPS)、研发团队追逐新技术(如大模型、多模态),却鲜少追问:这些指标是否真的解决了用户的问题? 以某电商平台的商品推荐系统为例,初期团队将“CTR(点击率)提升20%”作为核心目标,通过优化模型特征工程实现了指标达标,但上线后用户投诉“推荐同质化严重”“想买的搜不到”,最终导致用户留存率下降5%——这正是“技术指标对齐”而非“用户需求对齐”的典型失效案例。
核心问题:AI效能评估,到底在评估什么?
要破解这一困境,首先需要重新定义“AI效能”。从本质上看,AI系统是一种“通过数据和算法为用户创造价值的工具”,其效能的核心衡量标准应当是**“满足用户需求的程度”**。因此,企业AI效能评估的关键命题可拆解为:
什么是“用户需求”?如何精准识别和建模不同层级用户的真实需求?如何构建与用户需求强绑定的效能评估体系,避免“为评估而评估”?如何建立“用户需求-效能评估-系统迭代”的闭环机制,实现动态对齐?
文章脉络:从理论到实践的“需求对齐”方法论
本文将围绕“对齐用户需求”这一核心,系统拆解企业AI效能评估的方法论:
基础概念:厘清“用户需求”“AI效能评估”“对齐”的内涵与外延,揭示传统评估方法的局限性;核心原理:构建“需求分层建模-多维度评估体系-闭环反馈机制”的三阶对齐框架,并通过数学模型、算法流程量化实现路径;实践案例:结合阿里电商推荐、智能客服等真实项目,详解需求对齐的落地步骤与避坑指南;未来趋势:展望大模型时代用户需求的新特征,以及AI效能评估的智能化演进方向。
基础概念:重新理解“用户需求”与“AI效能评估”
核心概念界定
1. AI效能评估:从“技术指标”到“价值创造”
传统定义中,AI效能评估常被等同于“技术性能评估”,聚焦模型精度(如分类任务的Top-1准确率、NLP任务的BLEU分数)、工程效率(如训练耗时、推理延迟)、资源消耗(如GPU利用率、TCO成本)。这种视角的局限性在于:技术指标仅反映系统“能做什么”,而非“做出了什么价值”。
重新定义:AI效能评估是“以用户需求为导向,通过多维度指标衡量AI系统为用户创造价值的能力”。其核心特征包括:
价值导向:评估终点是“用户问题是否解决”,而非“技术指标是否达标”;多主体参与:需覆盖业务方(需求提出者)、终端用户(直接使用者)、技术团队(系统构建者)等多角色需求;动态演进:用户需求随场景、时间变化,评估体系需具备迭代能力。
2. 用户需求:分层、动态、多模态的复杂系统
“用户需求”并非单一维度的概念,而是由不同层级、不同主体、不同场景构成的复杂系统。基于阿里多年实践,我们将其划分为**“三层需求模型”**:
| 需求层级 | 定义 | 主体用户 | 核心关注点 | 示例(电商推荐场景) |
|---|---|---|---|---|
| 业务需求 | 驱动组织目标的战略级需求 | 业务方(如运营、产品) | 商业价值(GMV、留存率、成本降低) | “提升女装品类复购率10%” |
| 功能需求 | 为满足业务需求需实现的功能点 | 产品/技术团队 | 功能完整性、流程合理性 | “支持‘风格偏好’‘价格敏感’等维度的精准筛选” |
| 体验需求 | 用户使用系统时的主观感受 | 终端用户(消费者) | 易用性、满意度、情感共鸣 | “推荐结果多样性高,能发现小众设计师品牌” |
关键洞察:三层需求并非孤立,而是存在传递关系——体验需求支撑功能需求实现,功能需求服务于业务需求达成。例如,终端用户的“多样性推荐体验需求”(体验层)→ 需系统实现“多兴趣召回算法”(功能层)→ 最终支撑“女装复购率提升”(业务层)。若某一层需求缺失或错位,整个效能评估体系将失去根基。
3. “对齐”:目标、过程、结果的三维统一
“对齐用户需求”中的“对齐”(Alignment),是指AI系统的目标设定、开发过程、输出结果与用户需求保持一致。具体可分解为:
目标对齐:AI项目的核心目标(如“提升用户满意度”)与用户需求(如“推荐多样性”)一致;过程对齐:系统设计(如算法选型、数据采集)、评估指标(如多样性得分)服务于需求满足;结果对齐:系统输出(如推荐列表)实际解决了用户问题,且用户认可其价值。
传统效能评估方法的局限性
为凸显“对齐用户需求”的必要性,我们通过对比表格揭示传统评估方法的核心缺陷:
| 评估维度 | 传统方法 | 对齐用户需求的方法 | 本质差异 |
|---|---|---|---|
| 评估主体 | 技术团队主导(“我们认为用户需要什么”) | 多主体协同(业务方+用户+技术团队) | 从“闭门造车”到“用户参与” |
| 核心指标 | 单一技术指标(如模型精度、QPS) | 多维度价值指标(业务+体验+技术) | 从“技术驱动”到“价值驱动” |
| 用户参与度 | 事后调研(如上线后问卷调查) | 全程参与(需求采集→原型验证→迭代反馈) | 从“被动接受”到“主动共创” |
| 反馈机制 | 静态指标(指标一旦设定很少调整) | 动态闭环(根据用户反馈实时调优指标) | 从“一次性评估”到“持续优化” |
典型案例:某金融AI风控系统的评估失效
某银行信用卡中心曾上线“智能风控模型”,技术团队以“坏账率降低15%”为核心指标,采用XGBoost模型实现了指标达标。但上线后发现,大量优质用户(如年轻白领)因模型误判被拒贷,引发客诉率上升30%——原因在于传统评估仅关注“坏账率”(技术指标),而忽略了业务需求中的“用户覆盖率”(需覆盖80%潜在优质用户)和体验需求中的“解释性”(用户需知道拒贷原因)。
前置知识:需求工程与价值流理论
理解“对齐用户需求”需具备两个领域的基础知识:
需求工程(Requirements Engineering):涵盖需求采集(如用户访谈、问卷调研)、需求分析(如KANO模型、用户画像)、需求建模(如用例图、用户故事)等方法,是精准识别用户需求的基础;价值流理论(Value Stream Mapping):强调从“用户需求”到“价值交付”的全流程可视化,帮助识别评估体系中的非增值环节(如冗余指标、无效数据采集)。
本章小结
本章节通过重新定义核心概念,揭示了传统AI效能评估“重技术轻需求”的本质缺陷。关键结论包括:
AI效能的本质是“为用户创造价值”,评估需围绕“需求满足程度”展开;用户需求具有“业务-功能-体验”三层结构,需分层建模、传递对齐;“对齐”是目标、过程、结果的三维统一,需建立多主体协同、动态闭环的机制。
接下来,我们将进入核心原理部分,详解如何构建“需求对齐”的效能评估体系。
核心原理解析:“需求对齐”的三阶效能评估框架
总体架构:三阶对齐框架
基于“用户需求”的分层特征与“对齐”的三维内涵,我们提出企业AI效能评估的**“三阶对齐框架”**:
该框架以“需求分层建模”为起点,通过“多维度评估体系”实现过程对齐,最终通过“闭环反馈机制”动态调整需求与评估,形成持续迭代的正向循环。以下分模块详解各阶段的实现方法。
第一阶段:需求分层建模——从“模糊需求”到“可量化目标”
1. 需求采集:多主体、多渠道的立体采集网络
用户需求的“模糊性”是对齐的首要障碍(如业务方常说“我要一个智能的推荐系统”)。需通过多渠道采集打破信息不对称:
| 需求主体 | 采集方法 | 工具/技术支持 | 核心产出 |
|---|---|---|---|
| 业务方 | 战略研讨会、OKR对齐会 | 阿里战略解码工具(如“北斗”系统) | 业务目标文档(如“2024年女装GMV增长20%”) |
| 终端用户 | 用户访谈(1V1深度)、行为数据分析 | 用户研究平台(如阿里User Insight)、埋点系统 | 用户画像、需求痛点清单(如“搜索结果页加载慢”) |
| 技术团队 | 技术评审会、可行性评估 | 架构设计工具(如ADT)、成本测算模型 | 功能需求清单(如“支持千万级商品实时召回”) |
案例:阿里“女装新品推荐”项目需求采集
业务方需求:“新品上架后3天内GMV破百万”;终端用户需求(通过User Insight分析):“想快速发现符合风格的新品,但首页推荐太杂”;技术团队需求:“需平衡召回速度(<100ms)与准确率(点击率>行业均值15%)”。
2. 需求建模:KANO模型与优先级排序算法
采集到原始需求后,需通过建模将其转化为可量化、可排序的目标。这里引入两个核心工具:
(1)KANO模型:区分需求类型,避免“过度设计”
KANO模型将用户需求分为5类,帮助识别“必须满足”和“锦上添花”的需求,避免资源浪费:
| 需求类型 | 定义 | 示例(电商推荐) | 效能评估关联 |
|---|---|---|---|
| 基本型需求 | 不满足则用户极度不满,满足也不会惊喜 | “推荐商品与搜索词相关” | 核心指标(如相关性得分需≥0.8),不达标则系统不可用 |
| 期望型需求 | 满足程度越高,用户满意度越高 | “推荐结果多样性” | 关键指标(如多样性得分,权重由业务目标决定) |
| 兴奋型需求 | 未满足时用户无感知,满足后惊喜 | “推荐商品附带设计师故事” | 加分指标(如用户停留时长提升,不计入核心考核) |
| 无差异需求 | 满足与否对用户满意度无影响 | “推荐列表背景色更换” | 排除在评估体系外,避免资源浪费 |
| 反向型需求 | 满足后用户满意度下降 | “强制弹出推荐商品广告” | 负面指标(如投诉率,需严格控制上限) |
操作步骤:通过问卷调研(用户对“有/无某功能”的满意度评分),计算各需求的“魅力系数”(CS),公式为:
(2)层次分析法(AHP):量化需求权重,实现科学排序
当需求存在冲突(如“多样性”与“准确率”无法同时最大化)时,需通过AHP算法计算各需求的权重。以电商推荐为例,需求层级结构如下:
graph TD
A[总目标:提升女装推荐效能] --> B1[业务需求]
A --> B2[体验需求]
A --> B3[技术需求]
B1 --> C1[GMV增长]
B1 --> C2[复购率提升]
B2 --> C3[多样性]
B2 --> C4[相关性]
B3 --> C5[响应速度]
B3 --> C6[系统稳定性]
AHP算法步骤:
构造判断矩阵:邀请业务、用户、技术专家对同一层级需求两两比较重要性(1-9标度法,1=同等重要,9=极端重要);计算权重向量:通过特征值分解(AW=λmaxWAW = lambda_{ ext{max}}WAW=λmaxW)求最大特征值对应的特征向量,归一化后即为权重;一致性检验:计算CR(一致性比率)= CI/RI,若CR<0.1则判断矩阵有效。
代码示例:用Python实现AHP算法计算需求权重
import numpy as np
class AHP:
def __init__(self, matrix):
self.matrix = np.array(matrix)
self.n = self.matrix.shape[0]
def calculate_weight(self):
# 计算特征值与特征向量
eigenvalues, eigenvectors = np.linalg.eig(self.matrix)
max_idx = np.argmax(eigenvalues)
max_eigen = eigenvalues[max_idx].real
# 特征向量归一化
weights = eigenvectors[:, max_idx].real
weights = weights / np.sum(weights)
return weights, max_eigen
def consistency_check(self, max_eigen):
# 一致性指标CI
ci = (max_eigen - self.n) / (self.n - 1)
# 平均随机一致性指标RI(n=1~10有固定值,这里取n=3时RI=0.58)
ri = [0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49][self.n]
cr = ci / ri if ri != 0 else 0
return cr < 0.1 # CR<0.1则通过一致性检验
# 示例:体验需求(多样性C3、相关性C4)的判断矩阵(1-9标度)
# 矩阵[i][j]表示C_i相对于C_j的重要性(如[1, 3]表示C3比C4重要3倍)
matrix = [[1, 3], [1/3, 1]]
ahp = AHP(matrix)
weights, max_eigen = ahp.calculate_weight()
print(f"需求权重:多样性={weights[0]:.2f}, 相关性={weights[1]:.2f}") # 输出:多样性=0.75, 相关性=0.25
print(f"一致性检验结果:{'通过' if ahp.consistency_check(max_eigen) else '不通过'}") # 输出:通过
3. 需求文档化:PRD与技术方案的双向对齐
最终,需将建模后的需求转化为可执行的文档,确保技术团队与业务方认知一致。关键文档包括:
PRD(产品需求文档):明确业务目标(如“女装复购率”)、用户体验指标(如“多样性得分≥0.6”)、验收标准;技术方案文档:将需求转化为技术指标(如“召回层采用双塔模型,线上QPS≥1000”),并标注与需求的映射关系(如“双塔模型→提升相关性→支撑复购率”)。
第二阶段:多维度评估体系构建——从“单一指标”到“价值网络”
需求建模完成后,需构建与之匹配的效能评估体系。该体系需覆盖“业务-体验-技术”三个维度,形成相互支撑的“价值网络”。
1. 业务价值维度:直接关联用户业务目标
业务价值指标是评估的“顶层指挥棒”,直接反映AI系统对业务需求的满足程度。核心指标包括:
| 指标类型 | 定义 | 计算公式/衡量方式 | 示例(女装推荐) |
|---|---|---|---|
| 增长类指标 | 反映业务规模提升 | GMV=订单量×客单价;复购率=复购用户数/总用户数 | 新品GMV 3天内达120万(目标100万) |
| 效率类指标 | 反映资源投入降低 | 人工运营成本下降率=(原成本-现成本)/原成本 | 人工选品成本降低40% |
| 风险类指标 | 反映业务风险控制 | 客诉率=投诉用户数/总用户数;退货率=退货订单数/总订单数 | 客诉率≤0.5%,退货率≤行业均值 |
2. 用户体验维度:量化“用户主观感受”
用户体验指标需通过“行为数据+主观反馈”双重验证,避免“数据好看但用户不满”。核心指标包括:
| 指标类型 | 定义 | 数据来源 | 示例(女装推荐) |
|---|---|---|---|
| 行为指标 | 用户客观行为数据 | 埋点系统(如点击、停留、分享) | 新品点击占比提升25%,平均停留时长>30s |
| 满意度指标 | 用户主观评价 | NPS(净推荐值)、问卷调研 | NPS=45(目标30),满意度评分4.2/5 |
| 情感指标 | 用户情感倾向 | 评论情感分析、语音情绪识别 | 正面评论占比>80% |
量化模型:用户体验综合得分(UX Score)
通过加权求和整合多维度指标,权重由KANO模型和AHP算法确定:
3. 技术可行性维度:确保系统“能落地、可维护”
技术指标是支撑业务与体验需求的基础,需平衡“效果”与“成本”。核心指标包括:
| 指标类型 | 定义 | 关注点 | 示例(女装推荐) |
|---|---|---|---|
| 性能指标 | 系统响应速度、承载能力 | 实时性(如召回<100ms)、吞吐量(QPS≥1000) | 推荐接口平均响应时间85ms,峰值QPS=1500 |
| 成本指标 | 计算、存储、人力成本 | GPU资源利用率、模型训练耗时 | 日均GPU消耗降低20%,训练周期从72h→24h |
| 稳定性指标 | 系统容错能力、鲁棒性 | 可用性(99.9%)、故障恢复时间(<5min) | 服务可用性99.95%,故障自动恢复时间3min |
4. 指标关联与权重分配:构建“价值网络”模型
单一指标无法反映整体效能,需通过“指标关联图”揭示各维度指标的依赖关系,并通过权重分配实现综合评估。
(1)指标关联图(Mermaid示例)
graph LR
A[业务价值:女装GMV增长] --> B[体验指标:点击占比提升]
A --> C[体验指标:停留时长增加]
B --> D[技术指标:相关性得分≥0.8]
C --> E[技术指标:多样性得分≥0.6]
D --> F[技术方案:双塔召回模型]
E --> G[技术方案:多兴趣embedding]
F --> H[成本指标:GPU利用率≥70%]
G --> I[性能指标:QPS≥1000]
(2)综合效能得分模型
通过加权求和计算AI系统的综合效能得分(Overall Efficacy Score, OES),权重由需求优先级决定:
BVBVBV:业务价值得分(归一化至[0,1]),αalphaα为业务权重(如0.5);UXUXUX:用户体验得分(归一化至[0,1]),βetaβ为体验权重(如0.3);TechTechTech:技术可行性得分(归一化至[0,1]),γgammaγ为技术权重(如0.2);α+β+γ=1alpha + eta + gamma = 1α+β+γ=1,权重通过AHP算法从用户需求推导得出。
第三阶段:闭环反馈机制——动态对齐“需求-评估-迭代”
用户需求具有动态性(如用户偏好随季节变化),效能评估体系需通过闭环反馈机制持续调整。闭环流程可概括为“采集-分析-调整-验证”四步:
1. 用户反馈采集:全链路数据埋点与实时监控
需构建覆盖“用户接触点-系统输出-业务结果”的全链路数据采集网络:
| 反馈类型 | 采集节点 | 工具/技术 | 数据示例 |
|---|---|---|---|
| 实时行为反馈 | APP/网页端交互(点击、滑动、退出) | 埋点系统(如阿里ARMS)、用户行为分析平台 | 用户在第3个推荐商品点击,停留5秒后退出 |
| 事后主观反馈 | 订单完成页、客服对话后 | 满意度问卷、NPS调研 | “推荐很符合我的风格,会推荐朋友”(NPS=9) |
| 业务结果反馈 | 交易系统、CRM系统 | 数据仓库(如阿里MaxCompute) | 女装复购率本周达12%(目标10%) |
2. 需求-效能偏差分析:识别“未对齐”信号
通过对比“预期需求满足度”与“实际效能得分”,识别偏差并定位原因。引入“需求对齐度”(Alignment Degree, AD)指标:
| 偏差类型 | 表现 | 原因分析 | 应对措施 |
|---|---|---|---|
| 需求理解偏差 | 业务指标达标但用户满意度低 | 原始需求采集不充分(如未覆盖下沉市场用户) | 补充用户调研,更新用户画像 |
| 技术实现偏差 | 体验指标不达标(如多样性低) | 算法选型错误(如仅用协同过滤,未加内容特征) | 引入多兴趣召回模型,调整算法参数 |
| 环境变化偏差 | 业务指标突然下降(如GMV) | 用户需求随外部环境变化(如季节更替) | 动态调整权重(如冬季增加“保暖”相关需求权重) |
3. 评估体系动态调整:权重与指标的迭代优化
根据偏差分析结果,调整评估体系的“指标项”或“权重”:
指标项调整:新增/删除指标(如发现用户关注“新品上新速度”,新增“新品上架到推荐的时间间隔”指标);权重调整:通过AHP算法重新计算权重(如旺季时“GMV增长”权重从0.5→0.6,“成本降低”从0.2→0.1)。
4. 系统迭代与验证:MVP快速验证,小步快跑
调整后需通过MVP(最小可行产品)验证效果,避免大规模上线风险。例如,针对“多样性不足”的偏差,先在10%用户中灰度测试“多兴趣召回算法”,对比测试组与对照组的UX得分:若测试组多样性得分提升30%且NPS无下降,则全量上线;否则回滚并重新分析原因。
实践应用:阿里AI项目“需求对齐”案例深度剖析
案例一:电商推荐系统效能评估优化(从“CTR导向”到“需求导向”)
项目背景与问题
2022年,阿里某电商平台“女装推荐”场景面临困境:技术团队持续优化CTR(点击率),模型精度从85%提升至92%,但业务方反馈“用户逛得久但买得少”,终端用户投诉“推荐都是爆款,找不到适合自己的风格”。数据显示:CTR提升18%,但人均GMV下降5%,复购率下降8%——典型的“技术指标对齐但用户需求错位”。
需求对齐落地步骤
Step 1:需求重定义——从“CTR”到“用户价值”
业务方需求重构:与运营团队对齐新目标“提升女装品类人均GMV和复购率”,而非单一CTR;终端用户需求挖掘:通过User Insight分析10万+用户行为数据,发现核心痛点:
“想买小众风格,但推荐全是大众爆款”(多样性需求);“新品更新慢,总看到旧款”(时效性需求);
需求优先级排序:用AHP算法计算权重:多样性(0.4)、时效性(0.3)、CTR(0.2)、成本(0.1)。
Step 2:评估体系重构——多维度指标网络
构建新的评估体系,核心指标如下:
| 维度 | 核心指标 | 目标值 | 与需求的映射关系 |
|---|---|---|---|
| 业务价值 | 人均GMV、复购率 | 人均GMV提升15%,复购率提升10% | 直接关联业务方需求 |
| 用户体验 | 多样性得分(Diversity Score)、新品点击占比 | 多样性≥0.65,新品点击占比≥30% | 覆盖用户多样性、时效性需求 |
| 技术指标 | CTR(保底)、推荐响应时间 | CTR≥原基线(92%),响应时间<150ms | 确保体验不下降,系统稳定可用 |
多样性得分计算:
采用Entropy-based多样性指标,衡量推荐列表中商品风格的分布均匀度:
Step 3:系统迭代与闭环验证
算法优化:
召回层:引入“多兴趣召回”(MIND模型),为每个用户生成3个兴趣向量(如“法式连衣裙”“国风外套”“通勤裤装”);排序层:在CTR模型中加入“风格多样性特征”,平衡点击率与多样性;
灰度测试:选择10%目标用户(25-35岁女性,历史偏好小众风格)进行测试,结果:
多样性得分从0.42→0.71(达标);人均GMV提升22%(超目标15%),复购率提升14%(超目标10%);CTR下降3%,但因客单价提升(用户购买更多高价值小众商品),整体GMV仍增长;
全量上线与监控:建立实时监控看板,每日追踪多样性得分、GMV、复购率,每月通过AHP调整权重(如大促期间增加“时效性”权重)。
项目成果与经验总结
核心成果:女装品类人均GMV提升22%,复购率提升14%,用户NPS从38→52;关键经验:
避免“唯指标论”:CTR下降但GMV上升,证明单一技术指标无法反映真实效能;用户需求分层:区分“基础需求”(CTR保底)与“期望需求”(多样性),确保系统可用性;闭环速度:从需求采集到全量上线仅用45天(传统流程需3个月),小步快跑降低风险。
案例二:智能客服系统效能评估(从“解决率”到“用户满意度”)
项目背景与问题
阿里某智能客服系统初期以“问题解决率”(机器解决问题占比)为核心指标,优化后解决率达90%,但用户满意度(CSAT)仅65分——大量用户反馈“机器人答非所问,但不得不重复提问直到转接人工”。
需求对齐关键动作
1. 需求挖掘:用户要的是“解决问题”而非“机器解决”
通过用户访谈发现,终端用户的核心需求是“快速、准确解决问题”,而非“是否由机器解决”。因此,需将评估核心从“解决率”转向“用户问题解决的效率与体验”。
2. 评估体系重构:引入“用户解决成本”指标
定义“用户解决成本”(User Resolution Cost, URC),综合衡量解决问题的耗时与交互次数:
3. 闭环优化:从“机器视角”到“用户视角”
算法优化:
意图识别模型加入“用户 frustration 检测”(通过情绪词、重复提问识别用户不满),触发人工介入;回答生成增加“解释性”(如“您的订单未发货是因为仓库爆仓,预计明天12点前发出”);
评估结果:URC从8.2降至4.5,CSAT从65分提升至82分,人工转接率从10%降至5%(因用户无需反复提问)。
最佳实践Tips:需求对齐避坑指南
避免“需求中间商”:直接与终端用户沟通,而非仅依赖业务方转述(业务方可能过滤或误解需求);小步验证需求:用MVP(如灰度测试)验证需求假设,避免“需求正确但实现过度”;警惕“指标绑架”:定期审视指标是否仍反映需求(如GMV目标可能因市场变化需下调);跨团队协同机制:建立“业务-用户研究-技术”三方周会,同步需求变更与评估结果。
总结与展望
核心观点回顾
本文系统论证了“对齐用户需求是企业AI效能评估的关键”,并构建了“需求分层建模-多维度评估体系-闭环反馈机制”的三阶框架。核心结论包括:
用户需求具有“业务-功能-体验”三层结构,需通过KANO模型、AHP算法分层建模、科学排序;AI效能评估需覆盖“业务价值-用户体验-技术可行性”三维度,通过综合得分模型(OES)实现整体对齐;动态闭环是持续对齐的保障,需通过用户反馈实时调整需求与评估指标,避免“一劳永逸”。
行业发展与未来趋势
1. 大模型时代用户需求的新特征
大模型(如GPT、通义千问)的普及正在改变用户需求的形态:
需求表达更自然:用户从“精确关键词搜索”转向“自然语言描述”(如“帮我找一条适合小个子的法式连衣裙,不要太贵”);需求个性化深化:用户期待“千人千面”的深度定制(如“根据我的肤色推荐口红色号”);需求即时性提升:从“事后反馈”到“实时交互”(如边逛边问“这件衣服搭配什么鞋子”)。
2. AI效能评估的智能化演进方向
评估指标动态化:基于大模型的需求理解能力,实时解析用户输入并生成个性化评估指标(如为“预算敏感型用户”自动提升“价格相关性”权重);评估过程自动化:通过AI代理(AI Agent)模拟用户行为,自动测试系统在不同需求场景下的效能(如模拟“新用户”“高价值用户”的交互路径);价值评估因果化:从“相关性”(如推荐与点击的关联)到“因果性”(如确定“推荐多样性”是否直接导致复购率提升),需引入因果推断模型(如Do-Calculus)。
3. 企业落地建议
组织层面:成立“用户需求中心”,统筹跨部门需求采集与对齐;工具层面:构建一站式“需求-评估-迭代”平台(集成用户研究、指标监控、A/B测试功能);人才层面:培养“懂业务+懂技术+懂用户”的复合型AI架构师,避免“技术孤岛”。
延伸阅读
《Inspired:如何创造用户喜爱的产品》(Marty Cagan):需求挖掘与产品设计的经典指南;《Aligning AI with Business Objectives》(Gartner报告):企业AI战略对齐方法论;阿里技术博客:《电商推荐系统的用户需求对齐实践》《智能客服满意度提升的闭环机制》。
结语:企业AI效能评估的本质,是“以用户为中心”的价值判断。唯有将“对齐用户需求”贯穿于评估的全流程,才能避免AI项目“为技术而技术”,真正实现“技术创造价值”的初心。未来,随着大模型技术的成熟,“需求对齐”将从“方法论”进化为“系统能力”,成为企业AI竞争力的核心壁垒。<|FCResponseEnd|># 企业AI效能评估的关键:以“用户需求”为锚点的深度解构与实践指南
引言
背景介绍:AI项目的“冰火两重天”与效能评估的迷失
近年来,企业AI化已成为数字化转型的核心战略。据德勤《2023全球AI现状报告》显示,79%的企业已投入AI项目,但仅有23%的项目能持续产生业务价值;Gartner更指出,到2025年,60%的AI项目将因“效能评估与业务需求脱节”而终止。这种“高投入低产出”的困境背后,隐藏着一个被广泛忽视的核心问题:AI效能评估的锚点错位。
传统AI项目中,技术团队沉迷于模型精度(如准确率、F1-score)、工程团队关注系统吞吐量(QPS)、研发团队追逐新技术(如大模型、多模态),却鲜少追问:这些指标是否真的解决了用户的问题? 以某电商平台的商品推荐系统为例,初期团队将“CTR(点击率)提升20%”作为核心目标,通过优化模型特征工程实现了指标达标,但上线后用户投诉“推荐同质化严重”“想买的搜不到”,最终导致用户留存率下降5%——这正是“技术指标对齐”而非“用户需求对齐”的典型失效案例。
核心问题:AI效能评估,到底在评估什么?
要破解这一困境,首先需要重新定义“AI效能”。从本质上看,AI系统是一种“通过数据和算法为用户创造价值的工具”,其效能的核心衡量标准应当是**“满足用户需求的程度”**。因此,企业AI效能评估的关键命题可拆解为:
什么是“用户需求”?如何精准识别和建模不同层级用户的真实需求?如何构建与用户需求强绑定的效能评估体系,避免“为评估而评估”?如何建立“用户需求-效能评估-系统迭代”的闭环机制,实现动态对齐?
文章脉络:从理论到实践的“需求对齐”方法论
本文将围绕“对齐用户需求”这一核心,系统拆解企业AI效能评估的方法论:
基础概念:厘清“用户需求”“AI效能评估”“对齐”的内涵与外延,揭示传统评估方法的局限性;核心原理:构建“需求分层建模-多维度评估体系-闭环反馈机制”的三阶对齐框架,并通过数学模型、算法流程量化实现路径;实践案例:结合阿里电商推荐、智能客服等真实项目,详解需求对齐的落地步骤与避坑指南;未来趋势:展望大模型时代用户需求的新特征,以及AI效能评估的智能化演进方向。
基础概念:重新理解“用户需求”与“AI效能评估”
核心概念界定
1. AI效能评估:从“技术指标”到“价值创造”
传统定义中,AI效能评估常被等同于“技术性能评估”,聚焦模型精度(如分类任务的Top-1准确率、NLP任务的BLEU分数)、工程效率(如训练耗时、推理延迟)、资源消耗(如GPU利用率、TCO成本)。这种视角的局限性在于:技术指标仅反映系统“能做什么”,而非“做出了什么价值”。
重新定义:AI效能评估是“以用户需求为导向,通过多维度指标衡量AI系统为用户创造价值的能力”。其核心特征包括:
价值导向:评估终点是“用户问题是否解决”,而非“技术指标是否达标”;多主体参与:需覆盖业务方(需求提出者)、终端用户(直接使用者)、技术团队(系统构建者)等多角色需求;动态演进:用户需求随场景、时间变化,评估体系需具备迭代能力。
2. 用户需求:分层、动态、多模态的复杂系统
“用户需求”并非单一维度的概念,而是由不同层级、不同主体、不同场景构成的复杂系统。基于阿里多年实践,我们将其划分为**“三层需求模型”**:
| 需求层级 | 定义 | 主体用户 | 核心关注点 | 示例(电商推荐场景) |
|---|---|---|---|---|
| 业务需求 | 驱动组织目标的战略级需求 | 业务方(如运营、产品) | 商业价值(GMV、留存率、成本降低) | “提升女装品类复购率10%” |
| 功能需求 | 为满足业务需求需实现的功能点 | 产品/技术团队 | 功能完整性、流程合理性 | “支持‘风格偏好’‘价格敏感’等维度的精准筛选” |
| 体验需求 | 用户使用系统时的主观感受 | 终端用户(消费者) | 易用性、满意度、情感共鸣 | “推荐结果多样性高,能发现小众设计师品牌” |
关键洞察:三层需求并非孤立,而是存在传递关系——体验需求支撑功能需求实现,功能需求服务于业务需求达成。例如,终端用户的“多样性推荐体验需求”(体验层)→ 需系统实现“多兴趣召回算法”(功能层)→ 最终支撑“女装复购率提升”(业务层)。若某一层需求缺失或错位,整个效能评估体系将失去根基。
3. “对齐”:目标、过程、结果的三维统一
“对齐用户需求”中的“对齐”(Alignment),是指AI系统的目标设定、开发过程、输出结果与用户需求保持一致。具体可分解为:
目标对齐:AI项目的核心目标(如“提升用户满意度”)与用户需求(如“推荐多样性”)一致;过程对齐:系统设计(如算法选型、数据采集)、评估指标(如多样性得分)服务于需求满足;结果对齐:系统输出(如推荐列表)实际解决了用户问题,且用户认可其价值。
传统效能评估方法的局限性
为凸显“对齐用户需求”的必要性,我们通过对比表格揭示传统评估方法的核心缺陷:
| 评估维度 | 传统方法 | 对齐用户需求的方法 | 本质差异 |
|---|---|---|---|
| 评估主体 | 技术团队主导(“我们认为用户需要什么”) | 多主体协同(业务方+用户+技术团队) | 从“闭门造车”到“用户参与” |
| 核心指标 | 单一技术指标(如模型精度、QPS) | 多维度价值指标(业务+体验+技术) | 从“技术驱动”到“价值驱动” |
| 用户参与度 | 事后调研(如上线后问卷调查) | 全程参与(需求采集→原型验证→迭代反馈) | 从“被动接受”到“主动共创” |
| 反馈机制 | 静态指标(指标一旦设定很少调整) | 动态闭环(根据用户反馈实时调优指标) | 从“一次性评估”到“持续优化” |
典型案例:某金融AI风控系统的评估失效
某银行信用卡中心曾上线“智能风控模型”,技术团队以“坏账率降低15%”为核心指标,采用XGBoost模型实现了指标达标。但上线后发现,大量优质用户(如年轻白领)因模型误判被拒贷,引发客诉率上升30%——原因在于传统评估仅关注“坏账率”(技术指标),而忽略了业务需求中的“用户覆盖率”(需覆盖80%潜在优质用户)和体验需求中的“解释性”(用户需知道拒贷原因)。
前置知识:需求工程与价值流理论
理解“对齐用户需求”需具备两个领域的基础知识:
需求工程(Requirements Engineering):涵盖需求采集(如用户访谈、问卷调研)、需求分析(如KANO模型、用户画像)、需求建模(如用例图、用户故事)等方法,是
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...
