
上期图文教程,我们分享了Segment Anything分割一切模型的原理,Segment Anything Model 是一种以最少的人工干预构建全自动可提示图像分割模型的方法。模型提供了一键分割图片的方法,当然模型也可以运行我们输入一个坐标点,一个输入框,或者输入一个对象的文本来分割输入的对象。

它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型允许以灵活的方式使用它,只需为模型设计正确的提示(点击、分割框、文本等),就可以完成分割任务。此外,Segment Anything Meta SAM在包含超过 10 亿个掩码的多样化、高质量数据集上进行训练,这使其能够泛化到新类型的对象和图像。
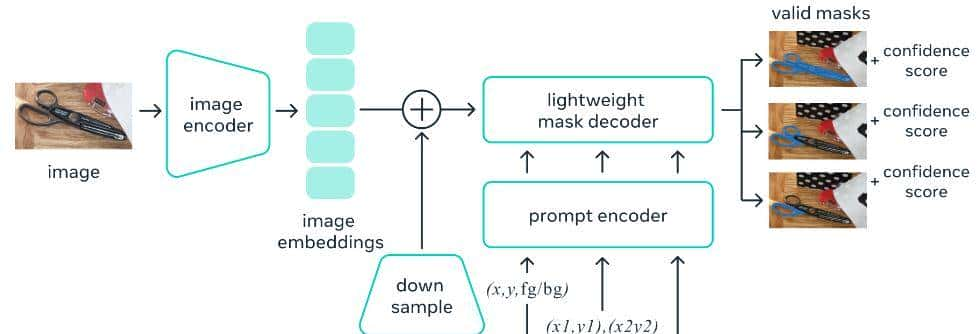
在 Segment Anything Meta SAM 中,该模式包含三个重大组成部分:
- 图像编码器。
- 提示编码器。
- 掩码解码器。

更多模型介绍,可以参考上期图文教程,本期教程,我们分享一下Segment Anything的代码实现过程。在运行代码前,第一需要确认一下有N卡的驱动,且成功安装了torch等第三方库
import torch
import torchvision
import sys
!{sys.executable} -m pip install opencv-python matplotlib
!{sys.executable} -m pip install 'git+https://github.com/facebookresearch/segment-anything.git'
!wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth第一我们需要使用到torch与torchvision库,并使用Facebook开源的segment-anything模型,安装相关的第三方库文件,并下载预训练模型。

import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_anns(anns):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:,:,3] = 0
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.35]])
img[m] = color_mask
ax.imshow(img)然后我们建立一个show函数,此函数主要用于可视化Segment Anything模型预测的结果。
image = cv2.imread('112233.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20,20))
plt.imshow(image)
plt.axis('off')
plt.show()
然后我们读取一张本地的照片,上张照片是transformer进行对象检测的结果,我们使用原图片上传给模型。在模型读取图片前,我们需要把图片转换到RGB空间,当然这里可以show一下图片。
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
然后我们就可以把图片传递给模型了,这里我们使用sam_vit_h_4b8939.pth预训练模型中的vit模型,SamAutomaticMaskGenerator函数帮我们建立了一个自动分割的函数,此函数会自动分割图片中的所有检测到的分类,当然此模型可以根据自己输入的坐标信息,对象种类来单独分割某个单独的对象,此部分代码我们后期进行分享。最后我们就可以把图片传递给mask generator函数进行预测了,预测后的结果保存在mask里面。

print(len(masks))
print(masks[0].keys())
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show() 模型预测完成后,我们可以打印出来模型预测的种类以及模型预测的结果,这里模型输出如下

segmentation : the mask
area : mask区域
bbox : XYWH format 格式的边框
predicted_iou : 模型自己对掩模质量的预测
point_coords : 生成此掩码的采样输入点
stability_score : 掩码质量的附加度量
crop_box : 用于生成 XYWH 格式蒙版的图像裁剪区域
192
dict_keys(['segmentation', 'area', 'bbox', 'predicted_iou', 'point_coords', 'stability_score', 'crop_box'])有了以上的输出,我们可以使用前面建立的可视化函数来进行mask图片的可视化操作

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录







收藏了,感谢分享
代码为完整代码,可以实现一下