
Meta 最近发布了 SAM 的第三代,我们借此机会来学习一下这个系列技术的演进过程。
一、什么是 CV 中的「分割」?
SAM 系列主要解决的问题是计算机视觉中的「分割」(Segmentation)任务,通俗讲就是 AI 把图片里的物体「抠」出来。
图像分割的目标:为图像中的每个像素赋予「属于哪个物体」的标签。实例分割需要区分不同实例(列如三只猫是三个不同的掩码),语义分割只区分类别不区分实例。
区分一下检测(Detection)和分割(Segmentation)这两个关联紧密的概念:
-
检测:输出的是边界框(框出了「在哪里」)。
-
分割:输出的是像素掩码(精细到每个像素「属于谁」)。
传统检测/分割模型在训练时只见过固定类别(例如 80 个 COCO 类别)。但现实世界里概念是无限的,需要模型能「理解新词」,这就需要视觉 – 语言联合的表明(类似 CLIP)。这就是典型的「开放词汇」(Open Vocabulary)问题。
二、第一阶段:前 SAM 时代
在 SAM 出现之前,情况是这样的:
-
闭集限制 (Closed-Set): 模型只能识别训练时见过的类别。如果你训练了「猫、狗」,给它一张「草泥马」的照片,它不认识,也无法抠图。
-
任务单一: 就像早期的 NLP 模型,有的专门做分词,有的专门做情感分析。CV 里有的专门做「语义分割」(把像素涂色),有的做「实例分割」(把每只猫区分开)。
三、第二阶段:SAM 1 & SAM 2
2023 年,Meta 发布了 SAM (Segment Anything Model) 。其核心理念是:可提示分割(Promptable Segmentation)。
如果你熟悉 LLM,对 Prompt(提示词)这个概念必定不陌生,SAM 1 就是把这个概念引入了视觉。
SAM 1 的任务设定是这样的:给一个静态图像,再加上「视觉提示」(列如一个点、一个框、多边形),模型返回对应物体的掩码(Mark)。所谓掩码,也就是那个物体的轮廓。这种任务被称作
这就像你用 LLM 做「抽取」任务时给了一个「锚点」(列如说「把这段里提到的公司名提取出来」),SAM 1 是图像里的「锚点分割器」。
技术要点:
-
强劲的图像编码器把图像嵌入。
-
一个提示编码器把「点/框」编码为向量。
-
一个掩码解码器把「图像特征 + 提示特征」转成像素级掩码。
这个技术为什么强呢?主要在于模型学会了一个抽象的物体概念,它不在乎这个物体是猫还是显微镜下的细胞,哪怕它根本不懂这个物体具体是什么东西,只要你给它一个点,它就能根据纹理、边缘,把这个物体从背景里抠出来。
后来的 SAM 2 增加了视频追踪功能,你在第一帧点一下/框一下,SAM 2 基于「记忆」把这个掩码在后续帧继续跟踪下去。
技术要点:
-
记忆编码器 + 记忆库:把过去出现过的掩码和外观特征保存起来。
-
掩码传播(Mask Propagation):把上一帧的掩码迁移到当前帧,再细化。
但和 SAM 1 和 SAM 2 都存在一个巨大的缺陷,它们不懂语义 (Semantically Blind)。
-
你不能告知它「把所有黄色的车抠出来」。
-
你必须手动在每辆车上点一下,或者画个框。如果你想抠视频里的一群鸟,你得点几百下。
也就是说,只能分割「你点到的那个实例」,不能根据「一个概念词」把图像里的所有实例一次性找全。
四、第三阶段:SAM 3
SAM 3 的目标是在解决 PVS(Promptable Visual Segmentation,也就是 SAM 1 和 SAM 2 的主要任务)的同时,可以支持 PCS (Promptable Concept Segmentation) 任务,即用自然语言概念(Concept)来控制分割。
换句话说,核心挑战是同时具备识别 (Recognition) 和 定位 (Localization) 的能力。在 CV 里,这两个目标一般对应两个流派:
-
CLIP 路线(懂语义,不懂位置): 知道图里有「猫」,但不知道猫的准确像素边界在哪里。
-
SAM 1 路线(懂位置,不懂语义): 知道这有个东西,但不知道它是猫。
SAM 3 就是要把这两者结合起来: 给一句「黄色的校车」,它能自动检测、分割并追踪视频里所有符合描述的校车。

五、SAM 3 的核心技术
SAM 3 用一个「解耦的检测器 – 追踪器架构」,共享一个强视觉 – 语言编码器(Perception Encoder,类似 CLIP/SigLIP 的多模态 encoder)。
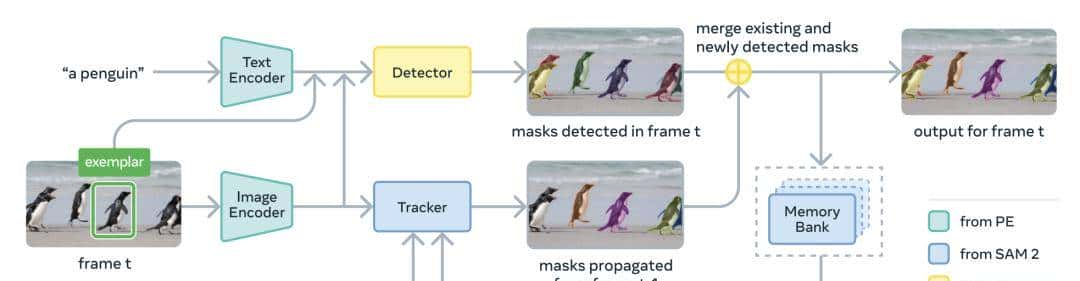
4.1 检测器 DETR:单帧上从概念找所有实例
主干是 DETR(DEtection TRansformer):你可以把它当作「序列到序列」的 Transformer,只不过目标是把「图像特征序列」解码成一系列对象查询(Object Query),每个查询尝试对齐图像里的一个实例。
主要组件:
-
Perception Encoder:把图像 + 文本提示编码成向量。
-
Fusion Encoder:让图像特征与提示特征做交叉注意力(Cross-Attention),让图像「知道要找什么」。
-
DETR Decoder:用一组对象查询,从融合后的特征中「拉出」若干实例(每个查询预测一个框和得分)。
这里有一个比较重大的创新: 存在感头(Presence Head) 。
开放词汇场景中,检测器既要判断「这个概念是否出目前这张图」(全局识别),又要「具体在哪里」(局部定位)。这两件事混在一个头里会相互干扰。这就导致传统的检测模型很容易出现「幻觉」 (Hallucination)。即使图里没有「校车」,那些 Object Queries 也会强行在图里找一个最像校车的东西(列如一辆黄色的小轿车)指出来。
SAM 3 的解法:把任务解耦成两个概率问题。
对于每一个 Query ,它是否匹配目标,取决于两个因子:
其中全局识别 (Presence Head) 引入一个特殊的「存在感 Token」,它先看一眼整张图,回答一个问题:「图里有校车吗?」。如果它说 ,那么后面所有的 Object Queries 的得分都会被压零。
SAM 3 的存在感头就是 CV 里的「检索门」,把「是否存在这个概念」的全局问题与「在哪里」的局部问题分开做。这有点像 LLM 领域中的 RAG (检索增强生成) 系统。在回答用户问题前,先判断「知识库里有没有相关文档」。如果没有,直接回答「不知道」,而不是强行编造一个答案。
这样一来,大幅减少了「困难负例」(图像里没有这个概念但模型容易误判)导致的误检。
4.2 追踪器:跨帧保持身份
这部分思想承接自 SAM 2:用记忆库记录已追踪对象的外观与掩码,在下一帧进行传播与更新。
视频每一帧的步骤:
-
Propagate:把上一帧的掩码传播到当前帧,得到预测位置。
-
Detect:用检测器在当前帧上根据概念提示再找新实例。
-
Match & Update:把传播来的老目标与新检测到的实例进行匹配,更新轨迹,给新目标分配新的 ID。
解耦的好处:
-
检测器只关心「当前帧找到所有匹配概念的实例」(身份不敏感)。
-
追踪器关心「在时间上身份一致」(身份敏感)。
-
避免把「全局识别」和「跨帧身份」揉进一个巨型网络里导致优化冲突。
4.3 概念提示的两种形式
-
文本短语(NP):如「striped cat」「a yellow school bus」。这是「全局提示」,影响整张图。
-
图像范例(Exemplar box):
-
正例:框住一个你想要的实例,用它作为「概念原型」的参考。
-
负例:框住一个类似但不想要的实例(列如「狼」),用于「排除误检」。
4.4 SAM 3 的数据引擎
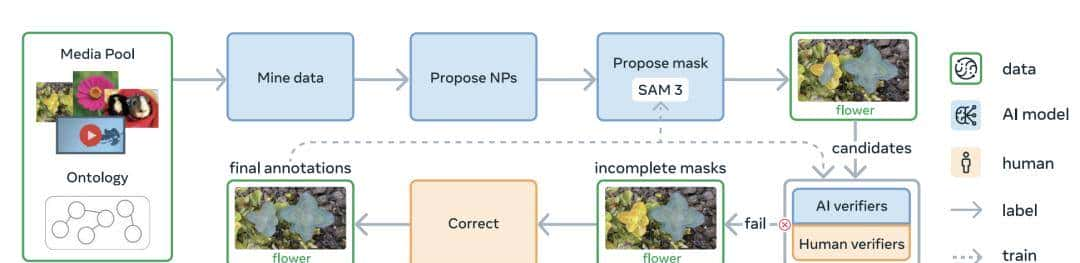
开放词汇视觉模型的瓶颈一般在数据。NLP 领域一般依赖互联网上海量的文本数据,但 CV 的高质量分割数据(Mask)超级稀缺,由于人工去描边太慢了。
SAM 3 用了一个「人 + AI 验证」的数据引擎来生产大规模高质量数据集:
-
Proposal: 用弱一点的模型或者 LLM 猜测图里有什么。
-
Generation: 用旧版的 SAM 生成 Mask。
-
Verification: 用强劲的 多模态大模型(MLLM)充当「老师」。把生成的 Mask 和原图喂给它,问它:「这个绿色的 Mask 真的对应‘校车’吗?」
-
Correction: 只有 MLLM 拿不准的「难例」,才交给人类去修。
这使得他们能搞出 SA-Co 这个包含 400 万概念的巨大数据集。
五、cgF1 指标:如何评估这类开放词汇「概念分割」?
传统指标在「概念不存在时」没那么敏感。SAM 3 引入了一个联合指标 cgF1,用来同时衡量「全局识别」和「局部分割质量」。
这个指标包含两个分量:
-
图像级分类能力(IL_MCC) :判断「这个概念是否出目前这张图里」,用 Matthews Correlation Coefficient,能处理类不平衡。
-
定位质量(pmF1) :只在「概念的确 存在」的图像上,衡量掩码的精度与召回。
两者都要好才有高分,任何一侧弱都会显著拉低总分。这对「开放词汇」的现实场景很重大,由于许多图片根本没这个概念——先「识别」再「定位」是更合理的流程。
六、推理步骤
综上所述,我们大致过一下这个模型在推理时,内部发生了什么。
对于单张图像(单帧):
-
文本提示编码(或范例编码)。
-
图像编码。
-
融合编码器把「图像 + 提示」做交叉注意力。
-
DETR 解码器用对象查询输出若干候选(框、分数)。
-
存在感头给出全局存在概率,乘上每个查询的条件概率得到最终得分。
-
掩码头/细化模块输出像素掩码。
对于一段视频(逐帧):
-
传播上一帧的掩码到当前帧(记忆库辅助)。
-
在当前帧跑一次「图像 PCS 检测器」,找新实例。
-
关联匹配:把传播来的「旧目标」和「新检测」对齐,更新 ID;没有匹配的就新建轨迹。
总结
SAM 3 的技术传承脉络大致是:
-
Transformer: 就像 Transformer 统一了 NLP,ViT (Vision Transformer) 和 DETR 统一了 CV 的底层。
-
SAM 1 (2023): 解决了 怎么切 (Geometric Segmentation) 。它是一个极致的「多边形生成工具」,但需要人手把手教它切哪里。
-
SAM 2 (2024): 把 SAM 1 扩展到了 时间维度 (Video) 。切一帧,自动管全视频。
-
SAM 3 (2025): 解决了 切什么 (Semantic/Concept Segmentation) 。它把 语义理解(CLIP/LLM 的能力)和 几何分割(SAM 的能力)融合了。
可以和 LLM 的相关技术做个对照,来加深记忆:
-
架构层面:
-
多模态编码器(图像 + 文本)类似 CLIP;DETR 解码器的对象查询类似 Transformer 解码器的查询。
-
「存在感头」像一个专门的
[CLS] 分类器,把全局相关性与局部抽取(对象查询)解耦。 -
追踪器的记忆库像是跨时间的 KV cache + 检索,保持身份一致性。
-
数据层面:
-
数据引擎就是视觉版「AI 生成 + AI 验证 + 人在环路」,与 RLHF/人类偏好对齐有共通理念。
-
困难负例就是对抗/困难样本挖掘,提升模型在「容易混淆」的边界上的判定力。
-
评估层面:
-
cgF1 用「识别 × 定位」的乘法结构,强调联合能力;像我们在抽取任务里既要看「是否找到对的类型」,也要看「边界是否精准」。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...