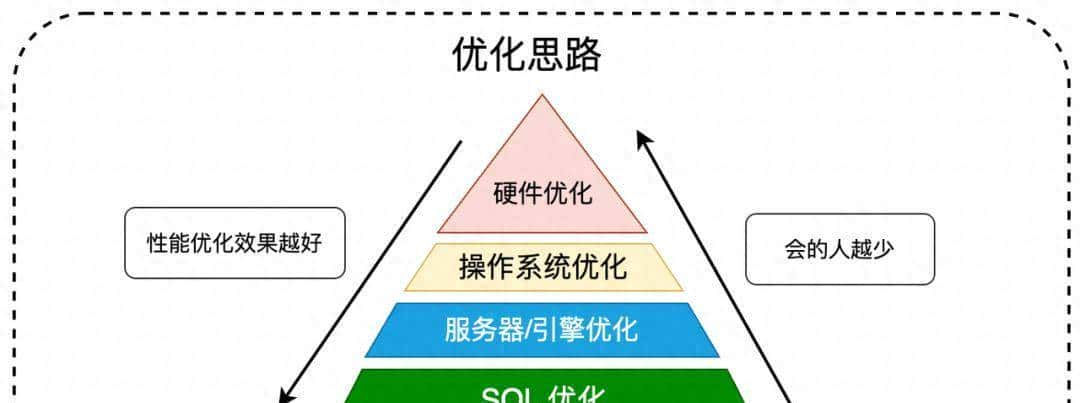
要把这些效果做到位,需要一套常规的工作流程:先看现状、再猜缘由、接着改法、最后验收。说白了就是像做体检一样,先查出哪里不舒服,再对症下药,最后复查确认没毛病。下面把我们实际干的事按顺序说清楚,细节别急着跳过去,许多看似小的点儿恰恰是性能瓶颈的根源。
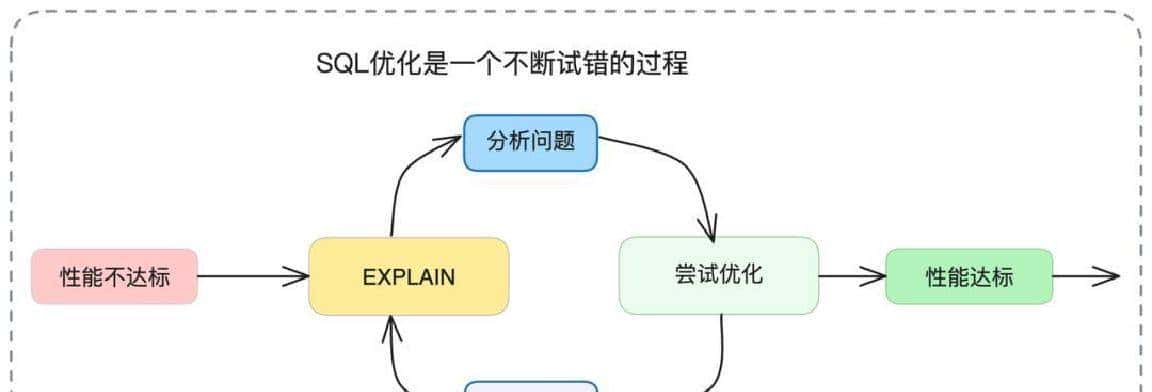
第一步是看SQL“怎么跑”。这个活儿靠执行计划,别嫌它复杂,能告知你查询走了哪条路、用没用上索引、估计要读多少行。这东西别省,许多问题就是在这一步清楚了。执行计划里有几样东西要盯着看:访问类型(好到差大致是 system、const、eq_ref、ref、range、index、ALL,出现ALL基本能认定是全表扫描),key字段告知你用了哪个索引,rows给出估算要扫描的行数,数字越小越省事,filtered显示WHERE条件能过滤掉多少数据,数值越高说明索引选择性好。把这些指标连起来看,问题范围能缩得很小。
举个最常见的例子。有人写SQL习惯性用SELECT *,业务实则只要order_id、amount、create_time三列。执行计划一看,索引没覆盖查询,执行器得回表,大量随机I/O就上来了。我们把SQL改成只选那三列,然后配合覆盖索引,回表消失了。结果很直观:延迟从大约100ms砍到不到1ms。这事儿看起来简单,可公司里还有不少人图方便直接*,这习惯挺坑的。
还有一种瓶颈是排序。随着数据变多,ORDER BY会把filesort搞出来,写盘、CPU飙升。我们调成用联合索引解决:发现user_id和action_time组合很适合建索引,B+树在同一个user_id下本身就是按action_time有序的,于是把索引改成(user_id, action_time)。查询不再触发额外排序,CPU和磁盘占用都降下来了,响应也稳了。关键在于用索引的物理有序性替代临时排序,省下了一大笔开销。
分组聚合也是常见问题。某条统计SQL在做GROUP BY前处理了太多无关数据,聚合阶段背上大包袱。改法就是在走到聚合前把数据量砍小:把过滤条件尽量前置,用索引列做预筛选,或者把一部分聚合下推到子查询里。调整后,分组查询耗时降了大约40%。但改SQL的时候必定要小心,别改出语义错误,边改边测是常态。
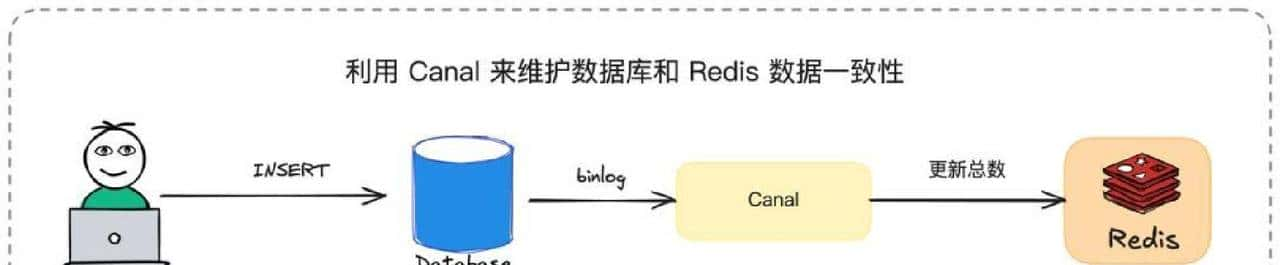
COUNT(*)的问题老生常谈,InnoDB直接跑会全表扫描,随着表长大成本线性增长。我们对比了几种方案:用EXPLAIN的rows字段做近似估算,速度快但不准确;用外部计数器能保证准确但实现复杂;用Redis维护计数器能做到实时读写,但一致性要自己做保证。最终落地的方案是:写操作仍走数据库,不改变现有逻辑,把变更通过binlog订阅异步更新Redis计数器,读的时候优先返回Redis的值,必要时可回查数据库做最终一致校验。这样在读性能和数据一致性之间找到一个折中点。实现里必须有异常补偿逻辑,避免计数漂移——列如定时全量校对、遇到回滚或异常写入时做回补。
分页问题在海量数据面前也会露馅。OFFSET分页看似方便,但页码越往后,数据库得扫描越多行,延迟随之走高。改成基于游标的分页(记住上一页最后一条记录的主键或排序列,下一页用 WHERE > last_id LIMIT N)后,查询性能保持平稳,不会随页码增长线性退化。落地时要保证排序字段有合适的索引,而且游标列能覆盖业务场景,别拿不稳定的列当游标。
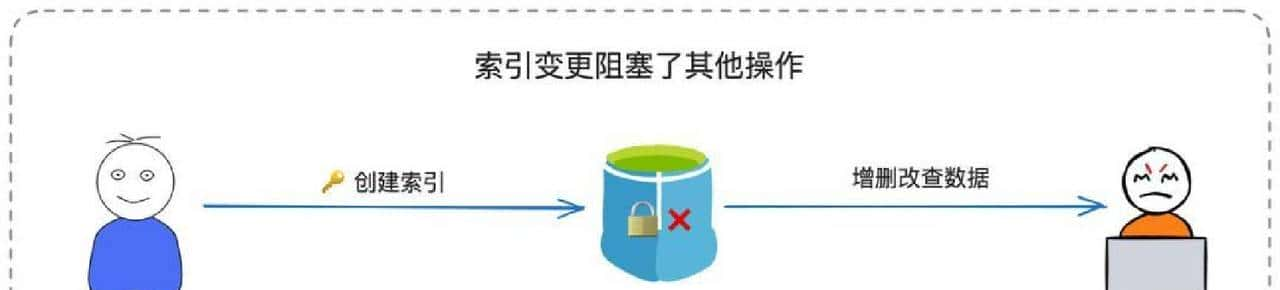
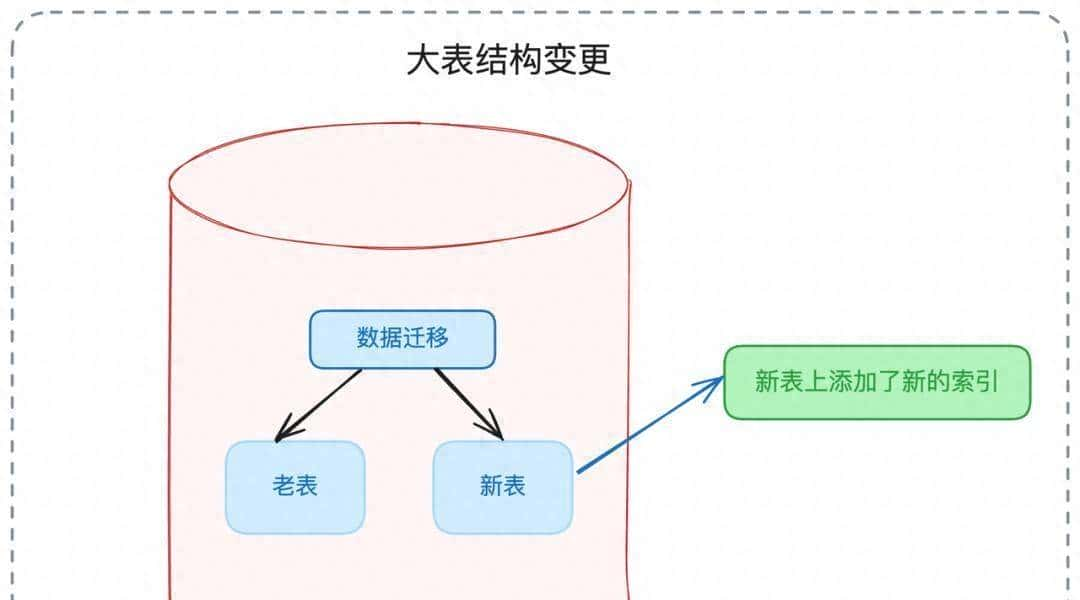
说到表结构变更,直接大规模执行ALTER TABLE很危险,会导致长时间锁表,线上服务会吃疼。我们用影子表做在线DDL:先在新结构上建表,把旧表按可控速率同步数据,或者用专门的在线复制工具,等数据一致后一次性切换表名。这样可以把锁窗压到最低。注意,这里要设计好一致性和回滚方案,别图省事在高峰期直接alter,容易闹出事故。
整个调优实则是一个闭环:用执行计划定位问题点,提出假设(列如慢是回表还是排序),在非生产环境验证改法,评估效果并检查是否有回归,然后在生产上灰度发布并监控一段时间。数据量大、并发高的系统会放大任何一个小失误,所以每次改动都要留个保险。我们上线后连续观察了监控和慢查询样本,有的老慢查询消失了,有的变得更稳定,锁等待指标下降。但过程中也遇到反复:某次索引调整在特定条件下反而触发了计划变化,导致某些查询变慢,不得不回滚并重新评估索引设计。这类来回是常态,调优不是一步到位,而是反复试验和修正的过程。
为了把这些步骤落地,需要一些具体习惯和工具配合。日常我们会把慢查询样本按频率和延迟分级,优先处理影响最大、最常见的几条。遇到复杂问题,先在测试环境还原数据量较小的场景跑执行计划,按计划分析是否存在回表、全表扫描或文件排序。改SQL或者建索引后,先在预发布环境进行压力测试,看查询延迟、CPU、IO的变化,再在生产做灰度并持续采样慢查询日志。任何一次改动上线都配备回滚脚本和快速恢复流程,万一出现异常可以迅速收手。
细节决定成败。列如覆盖索引这事儿,常常有人懂但不会落实:不单是建索引,还得把查询字段和排序字段一并思考,避免索引无法覆盖导致回表。还有联合索引的顺序要按过滤和排序的优先级来定,不是随意拼凑。再列如用Redis做计数器,设计时就要思考并发写入下的幂等性、binlog丢失或延迟的补偿策略,这些都要提前想好。
实践里也有一些经验教训值得记录。一次我们把某个查询的索引调整后,平时表现良好,但在某个稀有查询条件下,优化器选择了另一条执行计划,结果导致该查询延迟反而上升。排查发现是统计信息和索引选择性的变化影响了优化器决策。解决办法是补充更准确的统计信息,或者在必要时写出优化器可以喜爱的SQL形态,或者把索引策略再微调。这里的教训是:任何改变都可能带来意外,需要观测和回滚能力。
再说运维层面的配合。如果单靠开发改SQL不够,还要和DBA、运维通力合作。列如在线DDL工具的选择、数据同步速率的控制、切换时机的判定,这些都需要运维参与决策。灰度发布时,流量路由策略、熔断机制要准备好,防止改动在高并发时放大问题。
有人问我们用的具体排错节奏是什么。一般是这样:先看监控快速定位是哪类查询变慢(是单条慢还是大量查询延迟升高),再抓慢查询样本和执行计划,对症下药(改字段、改索引、改SQL或加缓存),在测试环境回放并验证,最后生产灰度并观察。每一步都要记录改动理由、回滚方案和观测指标,这样哪怕出了事也能回溯。
工具方面,EXPLAIN是第一步,慢查询日志、A/B对比工具、binlog订阅工具、Redis监控、在线复制或数据同步工具,这些都少不了。每种工具都有短板,关键是组合使用,用数据说话,不靠感觉决策。
我们也把许多常犯的“懒毛病”列成清单给同事了:别随手SELECT *、别在大表上用无索引的过滤、分页别滥用OFFSET、不要在高峰期直接alter表、写统计类功能时想好异步计数和补偿机制。把这些细节内化,能避免大量低级错误。
改动上线后的观测很重大。上线后一周是关键期,我们会把慢查询采样、锁等待、CPU和磁盘IO都盯着,若出现异常能在可控范围内回滚。多数时候,改动带来的收益会在监控上直接体现:慢查询减少、延迟分布变窄、锁等待下降。但也要准备好面对意外,像那次索引调整导致计划变化的教训提醒我们,耐心和反复试验比一锤子投资更靠谱。
调优的路子并不复杂,步骤清楚、工具到位、流程严谨就行。实际工作里更多是琢磨细节、踩坑、改写、再看效果。只要把执行计划、索引设计、SQL写法、在线变更和灰度发布这几块儿当成日常功课,性能问题就不会成为长期的灾难。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...







