K8S 有状态应用与无状态应用:定义、区别与技术实现深度解析
在云原生时代,正确识别和管理有状态与无状态应用已成为Kubernetes架构设计的核心能力。这两种应用模式在部署、扩展、恢复和存储等方面存在着根本性差异,深刻理解这些差异对于构建稳定、可扩展的云原生架构至关重大。
1 应用类型概述:从传统架构到云原生
1.1 应用模式的演进历程
在传统单体架构时代,应用的状态管理往往被忽视或简单处理。随着分布式系统和微服务架构的普及,应用状态的管理方式逐渐成为系统设计的关键决策点。云原生理念的兴起,更是将状态问题推向了架构设计的中心舞台。
Kubernetes作为云原生计算的基石,对不同状态特征的应用提供了差异化的支持方案。从早期的简单Pod管理,到如今成熟的StatefulSet、Operator等高级抽象,Kubernetes生态系统已经形成了完整的状态应用管理解决方案。
1.2 为什么状态管理如此重大
状态管理之所以复杂,是由于它触及了分布式系统中最具挑战性的问题:
- 数据一致性:在多个副本间保持状态同步的复杂性
- 持久化存储:确保关键数据在容器重启后不会丢失
- 网络标识:维护稳定的端点发现机制
- 有序部署:保证状态依赖型应用的启动和终止顺序
正确处理这些问题是构建可靠云原生应用的前提,也是本文要深入探讨的核心内容。
2 无状态应用深度解析
2.1 无状态应用的定义与特征
无状态应用是指不保存客户端会话信息或持久化数据的应用服务,每个请求都包含处理该请求所需的全部信息。这类应用一般将状态外置到专门的存储服务中,如数据库、缓存或对象存储。
核心特征:
- 会话无关性:请求可以在任何实例上处理,无需思考之前的交互历史
- 水平扩展友善:可以轻松地增加或减少实例数量
- 快速故障恢复:实例故障不会导致数据丢失,新实例可以立即接管工作
- 标准化部署:所有实例使用一样的镜像和配置启动
2.2 技术实现机制
在Kubernetes中,无状态应用主要通过Deployment资源进行管理:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: stateless-api
labels:
app: stateless-api
spec:
replicas: 3
selector:
matchLabels:
app: stateless-api
template:
metadata:
labels:
app: stateless-api
spec:
containers:
- name: api-server
image: my-registry/api-server:v1.2.3
ports:
- containerPort: 8080
env:
- name: DATABASE_URL
value: "postgresql://user:pass@db-host:5432/appdb"
- name: REDIS_URL
value: "redis://redis-host:6379"
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
restartPolicy: Always关键实现要点:
- 副本集管理:Deployment通过ReplicaSet确保指定数量的Pod副本持续运行
- 滚动更新:支持无停机部署新版本,通过maxSurge和maxUnavailable控制更新节奏
- 就绪探针:确保流量只路由到已准备就绪的Pod实例
- 外部化配置:通过ConfigMap和Secret管理应用配置,实现配置与代码分离
2.3 存储与状态处理
虽然称为”无状态”,但这并不意味着完全不使用存储,而是指不维护本地会话状态:
yaml
apiVersion: v1
kind: Pod
metadata:
name: web-application
spec:
containers:
- name: web-app
image: nginx:latest
volumeMounts:
- name: config-volume
mountPath: /etc/nginx/conf.d
- name: temporary-storage
mountPath: /tmp
- name: logs-volume
mountPath: /var/log/nginx
volumes:
- name: config-volume
configMap:
name: nginx-config
- name: temporary-storage
emptyDir: {}
- name: logs-volume
hostPath:
path: /var/log/nginx-pods
type: DirectoryOrCreate存储使用模式:
- 配置文件:通过ConfigMap挂载,所有实例共享一样配置
- 临时存储:使用emptyDir存储临时文件,生命周期与Pod一样
- 日志收集:日志一般输出到stdout/stderr或挂载的卷,由Sidecar容器收集
- 外部状态:会话数据存储在Redis/Memcached中,业务数据存储在数据库
2.4 典型应用场景
无状态架构适用于以下场景:
- RESTful API服务:每个API请求包含完整的认证和上下文信息
- 前端Web应用:静态资源服务或服务端渲染应用,会话状态存储在客户端或专用服务
- 消息处理Worker:从消息队列获取任务,处理后将结果写入数据库
- 实时数据转换:流式数据处理,将转换后的数据推送到下游系统
- 微服务架构中的业务逻辑层:处理业务逻辑,状态持久化到共享存储
某电商平台的实践表明,将其商品搜索服务从有状态改造为无状态架构后,扩容时间从分钟级降至秒级,高峰期可自动扩展到100+个实例,有效应对了促销活动的流量冲击。
3 有状态应用深度解析

3.1 有状态应用的定义与特征
有状态应用是指需要维护客户端会话信息或持久化数据的应用,请求处理依赖于之前交互产生的状态。这类应用一般对存储、网络标识和启动顺序有严格要求。
核心特征:
- 会话保持:同一客户端的连续请求需要路由到同一实例
- 数据持久性:应用数据需要在重启、迁移后依旧可用
- 身份标识:每个实例需要有唯一且稳定的网络标识
- 有序操作:扩展、更新、终止等操作需要遵循特定顺序
3.2 技术实现机制
在Kubernetes中,有状态应用主要通过StatefulSet资源进行管理:
yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-cluster
labels:
app: mysql
spec:
serviceName: "mysql"
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: root-password
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
- name: mysql-config
mountPath: /etc/mysql/conf.d
livenessProbe:
exec:
command: ["mysqladmin", "ping", "-h", "localhost"]
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
exec:
command: ["mysql", "-h", "127.0.0.1", "-u", "root", "-p${MYSQL_ROOT_PASSWORD}", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ssd"
resources:
requests:
storage: 100Gi关键实现要点:
- 稳定的网络标识:Pod名称遵循<statefulset-name>-<ordinal-index>模式,如mysql-0、mysql-1
- 持久化存储:通过volumeClaimTemplate为每个Pod创建独立的PersistentVolumeClaim
- 有序部署:Pod按顺序创建和扩展(从0到N-1),逆序终止(从N-1到0)
- 稳定的存储映射:Pod与PersistentVolume之间保持稳定的绑定关系,即使Pod重新调度
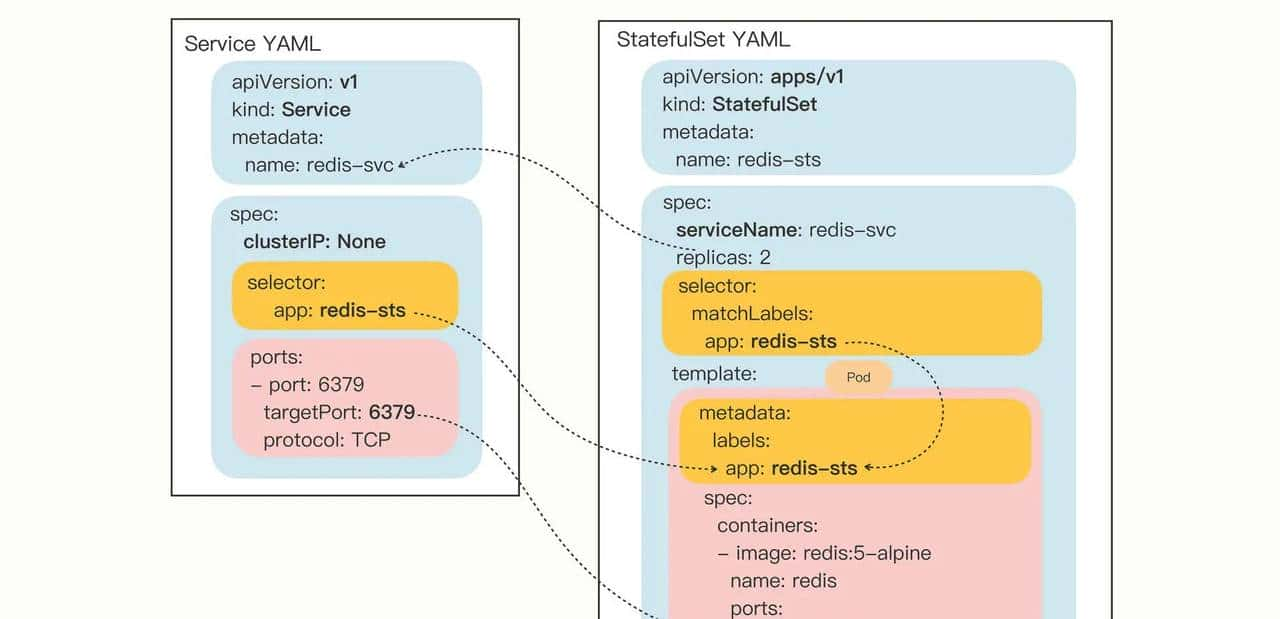
3.3 Headless Service与发现机制
有状态应用一般配合Headless Service实现服务发现:
yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- port: 3306
name: mysql
clusterIP: None # Headless Service的关键配置
selector:
app: mysql服务发现机制:
- DNS查询:通过mysql.default.svc.cluster.local域名可以解析到所有Pod的IP地址
- 稳定主机名:每个Pod可以通过mysql-0.mysql.default.svc.cluster.local格式的稳定FQDN访问
- 状态感知:应用可以通过DNS查询结果感知集群拓扑变化
3.4 典型应用场景
有状态架构适用于以下场景:
- 数据库系统:MySQL、PostgreSQL、MongoDB等需要持久化存储和主从复制的系统
- 消息队列:Kafka、RabbitMQ等需要持久化消息和集群状态协调的系统
- 分布式缓存:Redis Cluster、Hazelcast等需要数据分片和状态同步的缓存系统
- 监控与日志系统:Elasticsearch、Prometheus等需要持久化存储时序数据的系统
- 分布式协调服务:ZooKeeper、etcd等需要维护集群成员信息和一致状态的系统
某金融机构的数据库集群采用StatefulSet部署,通过稳定的网络标识和持久化存储,确保了金融交易数据的一致性和可靠性,即使节点故障也能快速恢复,满足了金融级业务连续性要求。
4 核心区别与技术对比
4.1 架构特性对比
|
特性维度 |
无状态应用 |
有状态应用 |
|
数据持久性 |
不保存本地状态,数据外置 |
维护本地持久化状态 |
|
会话保持 |
不需要,请求可路由到任意实例 |
需要,关联会话必须路由到同一实例 |
|
扩展性 |
线性扩展,简单快速 |
受状态同步限制,扩展复杂 |
|
故障恢复 |
快速,新实例立即接管工作 |
较慢,需要状态恢复或数据同步 |
|
部署复杂度 |
低,标准化部署流程 |
高,需要思考数据迁移和状态一致性 |
|
资源利用率 |
高,可按负载动态调整 |
较低,需要预留缓冲容量 |
4.2 Kubernetes资源对比
|
管理维度 |
Deployment(无状态) |
StatefulSet(有状态) |
|
Pod标识 |
随机哈希,无固定标识 |
有序索引,稳定标识(如app-0, app-1) |
|
存储管理 |
共享存储或临时存储 |
专用持久化存储,Pod与PV稳定绑定 |
|
网络标识 |
通过Service负载均衡 |
Headless Service,稳定的DNS记录 |
|
部署策略 |
滚动更新,支持最大不可用 |
顺序更新,保证应用可用性 |
|
扩展操作 |
立即创建/删除所有副本 |
顺序创建/逆序删除,保证数据安全 |
|
服务发现 |
通过Service ClusterIP |
通过Pod DNS记录直接访问 |
4.3 存储架构差异
无状态应用存储模式:
yaml
# 共享存储示例 - 多个Pod访问同一存储卷
volumes:
- name: shared-data
persistentVolumeClaim:
claimName: shared-pvc # 所有Pod使用一样的PVC有状态应用存储模式:
yaml
# StatefulSet卷声明模板 - 每个Pod获得独立存储
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Gi
# 生成的PVC名称:data-mysql-0, data-mysql-1, data-mysql-24.4 网络与服务发现对比
无状态服务访问:
bash
# 通过Service负载均衡
curl http://stateless-service/api/users/123
# 请求可能被路由到任意后端Pod有状态服务访问:
bash
# 直接访问特定Pod实例
curl http://stateful-app-2.stateful-service/api/users/123
# 请求始终到达stateful-app-2实例5 高级模式与混合架构
5.1 有状态应用的Operator模式
对于复杂的有状态应用,Kubernetes社区发展了Operator模式,通过自定义资源和控制循环来管理应用的全生命周期:
yaml
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: my-postgres-cluster
spec:
instances: 3
storage:
size: 50Gi
storageClass: fast-ssd
backup:
retentionPolicy: "30d"
monitoring:
enablePodMonitor: trueOperator提供了比原生StatefulSet更高级的能力:
- 自动备份与恢复:按策略执行数据库备份,支持时间点恢复
- 故障自动修复:检测节点故障并自动执行故障转移
- 配置管理:动态调整应用配置,无需重新创建Pod
- 版本升级:协调有状态应用的滚动升级,确保数据安全
5.2 无状态应用的服务网格集成
现代无状态应用越来越多地与服务网格技术结合,实现更精细的流量管理:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: stateless-api
spec:
hosts:
- stateless-api.example.com
http:
- match:
- headers:
user-type:
exact: premium
route:
- destination:
host: stateless-api
subset: v2
weight: 100
- route:
- destination:
host: stateless-api
subset: v1
weight: 100服务网格为无状态应用带来了:
- 智能路由:基于内容、头部的精细路由控制
- 弹性能力:断路器、重试、超时等 resiliency 模式
- 可观测性:分布式追踪、指标收集、服务依赖图谱
- 安全增强:mTLS加密、细粒度访问策略
5.3 混合状态模式
在实际生产环境中,纯无状态或有状态的架构较少,更多的是混合状态模式:
示例:电商订单处理系统
yaml
# 无状态部分 - 订单API服务
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-api
spec:
replicas: 5
template:
spec:
containers:
- name: order-api
image: order-api:latest
env:
- name: REDIS_URL
value: "redis://redis-cluster:6379"
- name: DB_URL
value: "postgresql://db-host:5432/orders"
---
# 有状态部分 - Redis集群
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
spec:
serviceName: redis-cluster
replicas: 6
template:
spec:
containers:
- name: redis
image: redis:6.2
command: ["redis-server"]
args: ["/etc/redis/redis.conf"]
volumeMounts:
- name: redis-data
mountPath: /data
- name: redis-config
mountPath: /etc/redis
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 50Gi这种架构结合了两者的优势:
- 无状态层:处理业务逻辑,实现快速弹性伸缩
- 有状态层:维护会话和缓存数据,保证数据一致性
- 分离关注点:各层专注于自己的核心职责
6 设计决策与实践提议
6.1 状态决策框架
在选择应用状态模式时,可以思考以下决策框架:
数据持久性需求:
- 数据是否需要跨重启持久化? → 是 → 有状态
- 数据是否可以重建或从外部获取? → 是 → 无状态
会话关联性:
- 请求是否必须路由到特定实例? → 是 → 有状态
- 请求是否可以在任意实例处理? → 是 → 无状态
扩展性要求:
- 是否需要秒级快速扩展? → 是 → 无状态优先
- 扩展时是否需要思考数据分片? → 是 → 有状态
运维复杂度容忍度:
- 团队是否有管理有状态应用的经验? → 否 → 无状态优先
- 是否可以接受更复杂的备份和恢复流程? → 是 → 有状态
6.2 最佳实践提议
无状态应用实践:
- 配置外部化:将所有配置、密钥、端点信息通过ConfigMap和Secret管理
- 健康检查:实现精细的就绪和存活探针,确保流量只到达健康实例
- 优雅终止:处理SIGTERM信号,完成当前请求后再终止
- 资源限制:设置合理的资源请求和限制,避免资源竞争
有状态应用实践:
- 备份策略:建立自动化的备份和恢复流程,定期测试恢复能力
- 监控告警:监控磁盘空间、IOPS、复制延迟等状态相关指标
- 容量规划:提前规划存储容量,设置自动扩展阈值
- 灾难恢复:制定跨可用区或跨区域的灾难恢复方案
6.3 迁移与现代化策略
对于传统应用向云原生架构的迁移:
- 状态外置化:将本地状态逐步迁移到外部存储服务
- 会话外部化:使用分布式缓存或专用会话存储替代本地会话
- 数据访问层抽象:通过接口抽象数据访问,便于后续存储技术迁移
- 渐进式改造:优先改造无状态部分,逐步处理有状态组件
7 未来趋势与发展方向
7.1 有状态应用的简化管理
Kubernetes生态系统正在努力降低有状态应用的管理复杂度:
- 标准化Operator:更多应用提供标准化的Operator,简化部署和运维
- 智能调度:基于存储性能、网络拓扑的智能调度策略
- 自动化运维:自动备份、修复、容量管理的智能化运维平台
7.2 无状态应用的性能优化
无状态应用在云原生环境下继续演进:
- Serverless架构:基于事件驱动的无服务器计算模式
- WebAssembly运行时:更安全、更高效的轻量级运行时环境
- 智能弹性:基于预测算法的前瞻性自动扩缩容
7.3 混合模式的创新
未来将有更多创新的混合状态管理模式:
- 状态分离架构:将状态完全分离到专门的状态服务中
- 边缘计算集成:适应边缘场景的轻量级状态管理方案
- 多集群状态同步:跨集群的状态同步和故障转移能力
总结
有状态应用和无状态应用是Kubernetes环境中两种基础且重大的应用模式,它们在设计理念、技术实现和适用场景上存在显著差异。正确识别应用的状态特征并选择合适的管理模式,是构建稳定、可扩展云原生架构的关键。
无状态应用以其简单性、弹性和易管理性成为云原生的首选模式,适合大多数业务逻辑处理场景。有状态应用虽然管理复杂,但在数据库、消息队列等需要持久化状态和数据一致性的场景中不可替代。
随着Kubernetes生态的不断成熟,StatefulSet、Operator等模式极大地简化了有状态应用的管理复杂度,而服务网格、Serverless等技术则为无状态应用提供了更强劲的能力。在实际架构设计中,混合使用两种模式,充分发挥各自优势,往往是构建复杂分布式系统的最佳实践。
在云原生旅程中,理解状态管理的本质,掌握有状态和无状态应用的设计模式,将持续为我们的系统带来更好的弹性、可靠性和可维护性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...