对于大型的互联网应用来说,数据库单表的记录行数可能到达千万级别甚至是亿级,并且数据库面临着极高的并发访问。采用Master-Slave 复制模式的MySQL架构,只能够对数据库的读进行扩展,而对数据库的写入操作还是聚焦在Master上,并且单个Master挂载的Slave也不可能无限制多,Slave的数量受到Master能力和负载的限制。因此,需要对数据库的吞吐能力进行进一步的扩展,以满足高并发访问与海量数据存储的需要。
数据分区
在分布式系统中,需要将数据划分为多个分区,并将每个分区存储在不同的节点上。这有助于提高系统的可伸缩性和可靠性,由于不同的节点可以独立地处理自己的数据。常见的数据分区策略包括按哈希分区、按范围分区等。
分表策略
对于访问极为频繁且数据量巨大的单表来说,我们第一要做的就是减少单表的记录条数,以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表。在分表之前,第一需要选择适当的分表策略,使得数据能够较为均衡地分布到多张表中,并且不影响正常的查询。
对于互联网企业来说,大部份数据都是与用户有关联的,因此,用户ID是最常用的分表字段。由于大部分查询都需要带上用户ID,这样既不影响查询,又能够使数据较为均衡地分布到各个表中。
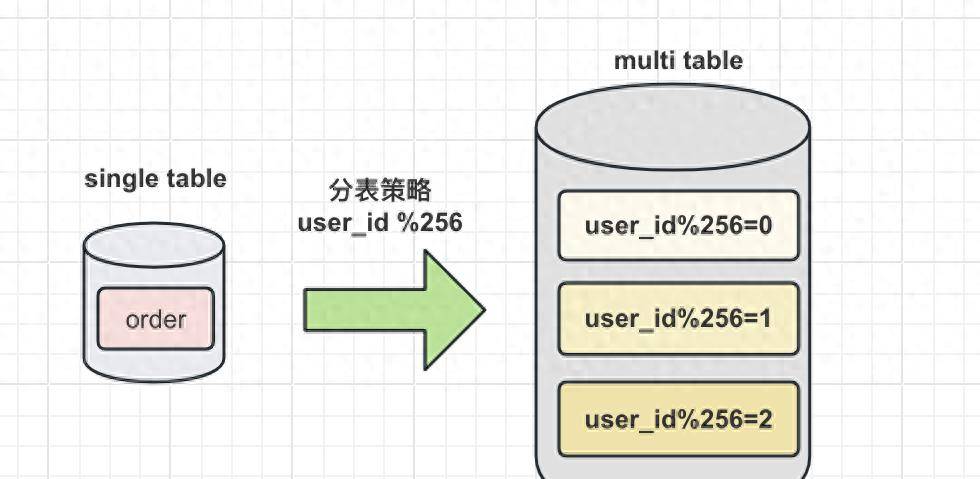
假设有一张记录用户购买信息的订单表order,由于order表记录条数太多,将被拆分成256张表。拆分的记录根据user_id%256取到对应的表进行存储,前台应用则根据对应的user_id%256,找到对应订单存储的表进行访问。这样一来,user_id便成为一个必需的查询条件,否则将会由于无法定位数据存储的表而无法对数据进行访问。
假设订单order 表结构如下:
CREATE TABLE `order` (
`order_id` bigint(20) unsigned NOT NULL COMMENT '订单ID,分布式ID',
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID',
`nick_name` varchar(32) NOT NULL COMMENT '用户昵称',
`shop_id` bigint(20) unsigned NOT NULL COMMENT '店铺ID',
`total` bigint(20) unsigned NOT NULL COMMENT '总金额,分',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表';那么分表后来,假设user_id =257,并且shop_id = 100,需要根据shop_id来查询对应的订单信息,则对应的SQL语句如下:
SELECT * FROM order_1 where user_id = 257 and shop_id = 100;DbTableUtil 分表工具类
DbTableUtil 工具类,可以生成 0001 到 9999张表记录,如订单表 order,使用DbTableUtil 生成表如下:
order_0001,order_0002,order_0003,order_0004………order_9999
public class DbTableUtil {
private static final int TABLE_SIZE = 256;
public DbTableUtil() {
}
public static String getTableIndex(Object shardKey, int sliceSize) {
int hashValue = Math.abs(shardKey.hashCode());
int tableIndex = hashValue % sliceSize + 1;
return String.format("%04d", tableIndex);
}
public static String hash(long key, int sliceSize) {
long hashValue = Math.abs(key);
int tableIndex = (int)(hashValue % (long)sliceSize + 1L);
return String.format("%04d", tableIndex);
}
public static String hash(long key) {
return hash(key, 256);
}
}分库策略
其中,order_1根据 257%256计算得出,表明分表之后的第一张order表。
分表能够解决单表数据量过大带来的查询效率低下的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库Master服务器无法承载写操作压力时,不管如何扩展Slave服务器,此时都没有意义了。因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库的写入能力,这就是所谓的分库。
与分表策略类似,分库也可以采用通过一个关键字段去取模的方式,来对数据库访问进行路由,如图:
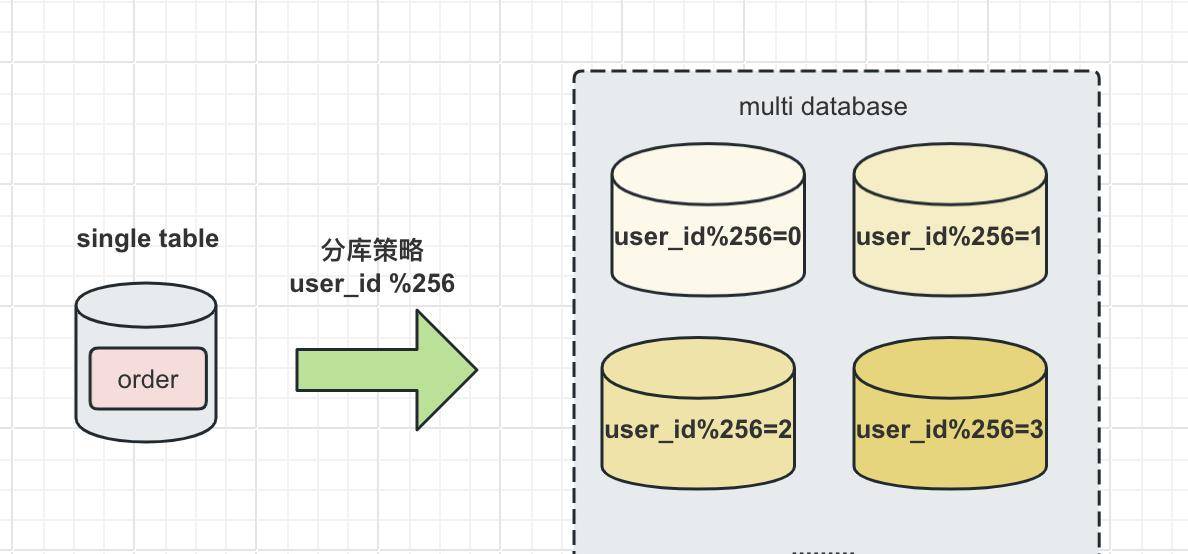
分库分表策略
还是之前的订单表,假设user_id字段的值为257,将原有的单库分为256个库,那么应用程序对数据库的访问请求将被路由到第一个库 257%256=1。
有时数据库可能既面临着并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库即采用分表策略,又采用分库策略,以便同时扩展系统的并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。
分库分表的策略比前面的仅分表的策略要更为复杂,一种分库分表的路由策略如下:
- 中间变量=user_id%(库数量 * 每个库的表数量)
- 库=取整(中间变量/每个库的表数量)
- 表=中间变量 % 每个库的表数量
同样采用user_id作为路由字段,第一使用user_id对库数量 * 每个库的表的数量取模,得到一个中间变量;然后使用中间变量除以每个库表的数量,取整,得到对应的库;而中间变量对每个库表的数量取模,即得到对应的表。分库分表策略如图:
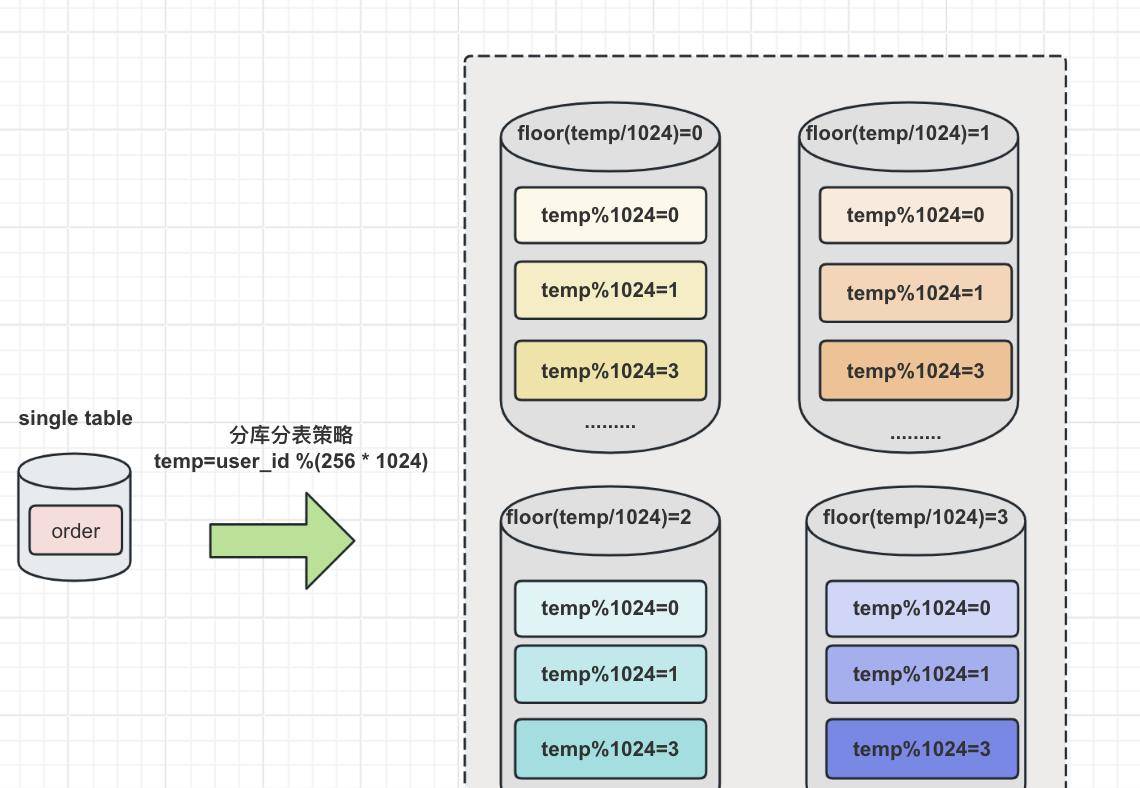
假设将原来的单库单表 order 拆分成256个库,每个库包含1024个表,那么按照前面所提到的路由策略,对于 user_id= 262145的访问,路由计算过程如下:
- 中间变量 = 262145 % (256 * 1024 ) = 1;
- 库= 取整(1/1024) = 0
- 表= 1%1024 =1
这意味着,对于 user_id= 262145 的订单记录的查询和修改,将被路由到第 0个库的第1个表中执行。
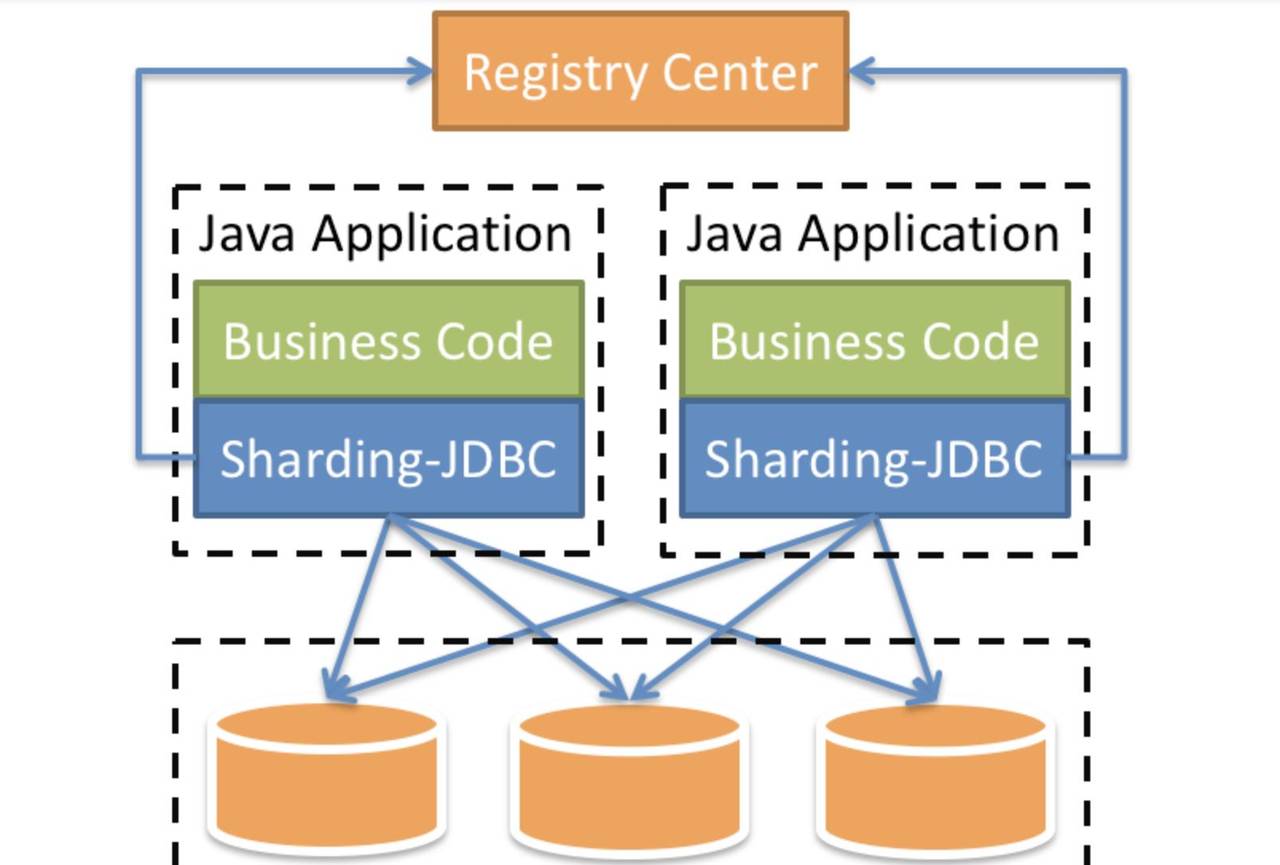
ShardingSphere
下期我们会介绍ShardingSphere,它是一套开源的分布式数据库中间件解决方案。可以大大减轻我们开发的压力。其架构图:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录






收藏了,感谢分享
亿级也叫数据?