
文本分类是NLP中最常见的任务之一。 一种常见的文本分类是情感分析,其目的是识别特定文本的倾向性。
目前想象一下,你是一个数据科学家,需要建立一个系统,能够自动识别人们在某网站上对你公司的产品所表达的情绪状态,如 “愤怒 “或 “喜悦”。 在这一章中,我们将使用BERT的一个变种DistilBERT来解决这一任务。 这种模式的主要优点是,它实现了与BERT相当的性能,同时明显更小、更有效率。 这使我们能够在几分钟内训练一个分类器,如果你想训练一个更大的BERT模型,你可以简单地改变预训练模型的检查点。 一个检查点对应于被加载到一个给定的Transformers架构中的权重集。
这次需要用到Hugging Face生态系统中的三个核心库:数据集、标记化器和Transformers。
数据集
为了建立我们的情绪检测器,我们将使用一个伟大的数据集。数据集包含六种基本**情感。 愤怒、厌恶、恐惧、喜悦、悲伤和惊讶**。 给定一条句子或段落,我们的任务是训练一个可以将其归类为这些情绪之一的模型。
**对Hugging face数据集的初步了解**
我们将使用Datasets 类库从Hugging Face Hub下载数据。 我们可以使用list_datasets()函数来查看Hub上有哪些数据集可用。
我们看到每个数据集都有一个名字,所以让我们用load_dataset()函数加载情感数据集。
如果我们看一下我们的emotion对象的内部:
**如果我的数据集不在模型仓库中怎么办?**
我们将使用Hugging Face Hub来下载本书中大多数例子的数据集。 但在许多情况下,你会发现自己的工作数据要么存储在你的笔记本电脑上,要么存储在你组织的远程服务器上。 数据集提供了几个加载脚本来处理本地和远程数据集。 最常见的数据格式的例子见表2-1:
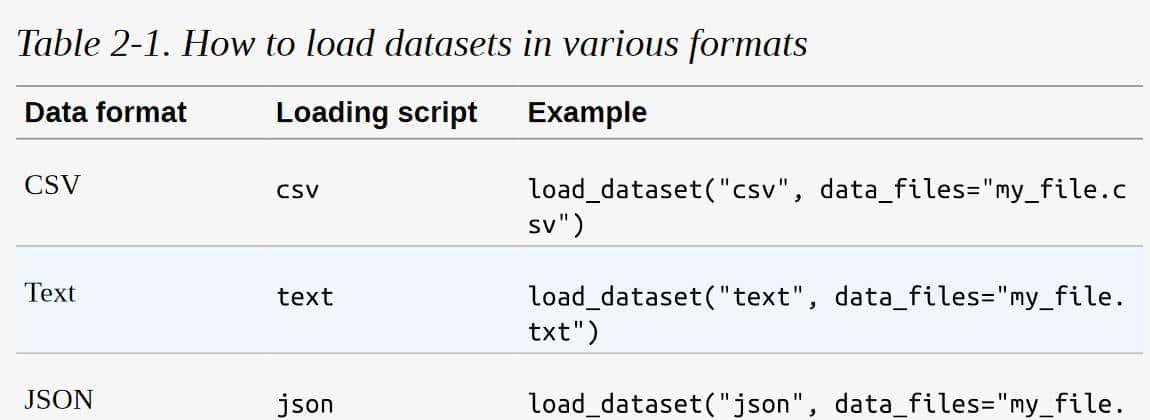
正如你所看到的,对于每一种数据格式,我们只需要将相关的加载脚本传递给load_dataset()函数,以及指定一个或多个文件的路径或URL的 data_files 参数。 例如,情感数据集的源文件实际上托管在Dropbox上,所以加载数据集的另一种方法是先下载其中一个分割文件。
**从 Datasets 类 到 DataFrames 类**
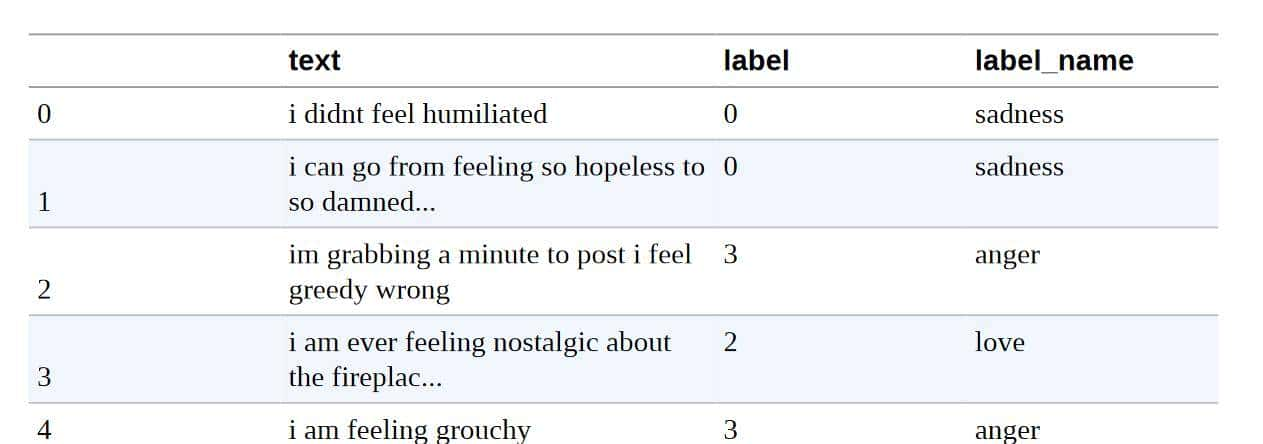
虽然Datasets提供了许多底层的功能来切分我们的数据,但将Dataset对象转换为Pandas DataFrame一般是很方便的,这样我们就可以访问高层的API来实现数据可视化。 为了实现转换,数据集提供了一个set_format()方法,允许我们改变数据集的输出格式。 请注意,这并不改变底层的数据格式(这是一个箭头表),如果需要,你可以在后来切换到另一种格式:
查看类分布
每当你在处理文本分类问题时,检查例子在各个类别中的分布是一个好主意。 一个具有倾斜类分布的数据集在训练损失和评价指标方面可能需要与平衡的数据集有不同的处理。
通过Pandas和Matplotlib,我们可以快速地将类的分布可视化,如下所示:
import matplotlib.pyplot as plt df[“label_name”].value_counts(ascending=True).plot.barh() plt.title(“Frequency of Classes”) plt.show()
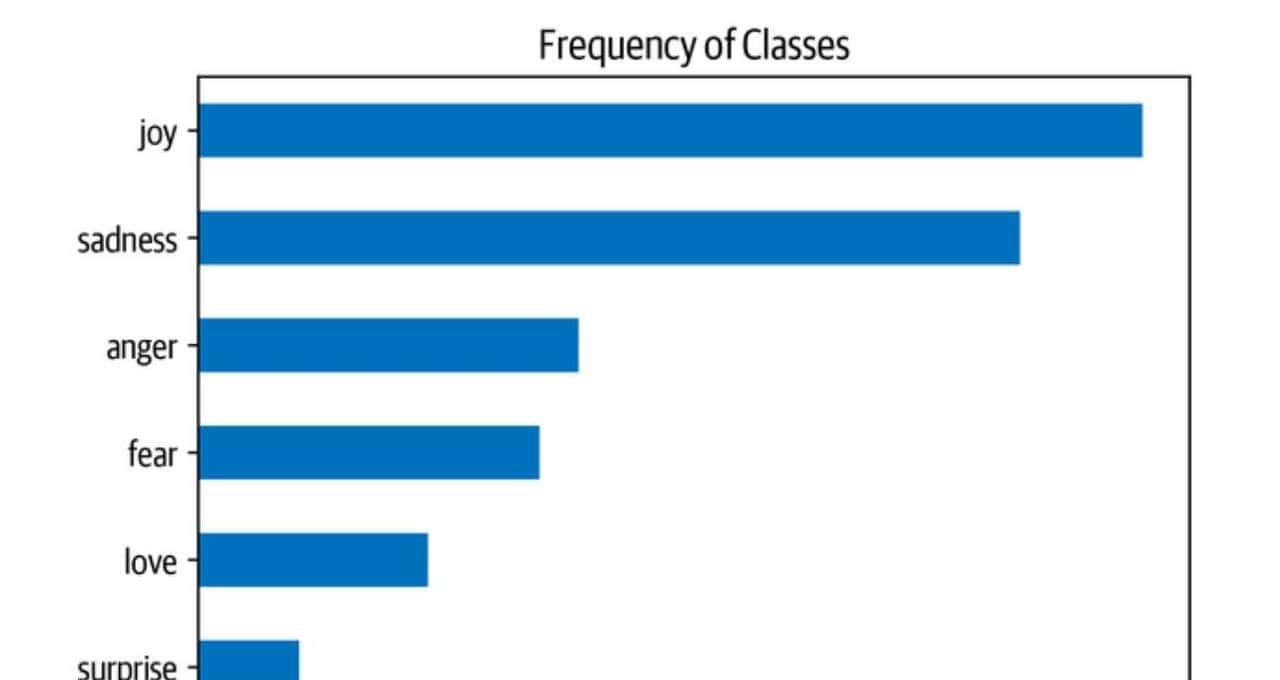
在这种情况下,我们可以看到数据集是严重不平衡的。 喜悦和悲伤的类别常常出现,而爱和惊喜则大约罕见5-10倍。 有几种方法来处理不平衡的数据,包括:
随机地对少样本类别进行超采样。 随机地对多样本类别进行欠采样。 从代表性不足的类别收集更多的标签数据。
从文本到标记
像DistilBERT这样的转化器模型不能接收原始字符串作为输入。 相反,他们假设文本已被标记化并被编码为数字向量。 符号化是将字符串分解为模型中使用的原子单元的步骤。 有几种标记化策略可以采用,而且一般从语料库中学习到最佳的单词拆分成子单元的方法。 在研究用于DistilBERT的标记器之前,让我们思考两个极端情况。 字符和词的标记化。
**字符标记**
最简单的标记化方案是将每个字符单独送入模型。 在Python中,str对象实际上就是引擎盖下的数组,这使得我们只需一行代码就可以快速实现字符级的标记化:
text = “Tokenizing text is a core task of NLP.” tokenized_text = list(text) print(tokenized_text) ['T', 'o', 'k', 'e', 'n', 'i', 'z', 'i', 'n', 'g', ' ', 't', 'e', 'x', 't', ' ', 'i', 's', ' ', 'a', ' ', 'c', 'o', 'r', 'e', ' ', 't', 'a', 's', 'k', ' ', 'o', 'f', ' ', 'N', 'L', 'P', '.'] 这是一个好的开始,但我们还没有完成。 我们的模型希望每个字符都被转换为一个整数,这个过程有时被称为数值化。 做到这一点的一个简单方法是对每个独特的标记(在这种情况下是字符)用一个独特的整数进行编码:
token2idx = {ch: idx for idx, ch in enumerate(sorted(set(tokenized_text)))} print(token2idx) {' ': 0, '.': 1, 'L': 2, 'N': 3, 'P': 4, 'T': 5, 'a': 6, 'c': 7, 'e': 8, 'f': 9, 'g': 10, 'i': 11, 'k': 12, 'n': 13, 'o': 14, 'r': 15, 's': 16, 't': 17, 'x': 18, 'z': 19} 这给了我们一个从词汇表中的每个字符到一个唯一的整数的映射。 目前我们可以使用token2idx将标记化的文本转换为一个整数的列表:
input_ids = [token2idx[token] for token in tokenized_text] print(input_ids)
[5, 14, 12, 8, 13, 11, 19, 11, 13, 10, 0, 17, 8, 18, 17, 0, 11, 16, 0, 6, 0, 7, 14, 15, 8, 0, 17, 6, 16, 12, 0, 14, 9, 0, 3, 2, 4, 1] 每个标记目前都被映射到一个唯一的数字标识符(因此被称为input_ids)。 最后一步是将input_ids转换为二维独热向量的张量。 一热向量在机器学习中常常被用来编码分类数据,这些数据可以是顺序的,也可以是名义的。 例如,假设我们想对《变形金刚》电视剧中的人物名称进行编码。 一种方法是将每个名字映射到一个唯一的ID,如下所示:
categorical_df = pd.DataFrame( {“Name”: [“Bumblebee”, “Optimus Prime”, “Megatron”], “Label ID”: [0,1,2]})
categorical_df
**词标记化**
我们可以不把文本分割成字符,而是把它分割成单词,并把每个单词映射成一个整数。 从一开始就使用单词,使模型能够跳过从字符中学习单词的步骤,从而降低训练过程的复杂性。
一类简单的单词标记器使用空白处对文本进行标记。 我们可以通过在原始文本上直接应用Python的split()函数来做到这一点(就像我们在测量推文长度时一样):
tokenized_text = text.split() print(tokenized_text)
['Tokenizing', 'text', 'is', 'a', 'core', 'task', 'of', 'NLP.'] 从这里,我们可以采取与字符标记器一样的步骤,将每个词映射到一个ID。 不过,我们已经可以看到这种标记化方案的一个潜在问题。 标点符号没有被计算在内,所以NLP。 被视为一个单一的标记。 思考到单词可以包括分词、变体或拼写错误,词汇量可以很容易地增长到数百万!
**子词标记化**
子词标记化的基本思路是结合字符和词的标记化的最佳方面。 一方面,我们想把罕见的词分成更小的单元,以使模型能够处理复杂的词和拼写错误。 另一方面,我们希望把频繁出现的词作为唯一的实体,这样我们就可以把输入的长度保持在一个可控的规模。 子词标记化(以及单词标记化)的主要区别在于,它是利用统计规则和算法的混合,从预训练语料库中学习的。
在NLP中,有几种常用的子词标记化算法,但让我们从WordPiece开始,它被BERT和DistilBERT标记化程序所使用。 了解WordPiece如何工作的最简单方法是看它的运行情况。Transformers提供了一个方便的AutoTokenizer类,允许你快速加载与预训练模型相关的标记器–我们只需调用其from_pretrained()方法,提供Hub上模型的ID或本地文件路径。 让我们从加载DistilBERT的标记器开始:
from transformers import AutoTokenizer model_ckpt = “distilbert-base-uncased” tokenizer =
AutoTokenizer.from_pretrained(model_ckpt) AutoTokenizer类属于一个更大的 “auto “类集合,其工作是自动检索模型的配置、预训练的权重或来自检查点名称的词汇。 这允许你在不同的模型之间快速切换,但如果你想手动加载特定的类,你也可以这样做。 例如,我们可以按以下方式加载DistilBERT标记器:
from transformers import DistilBertTokenizer distilbert_tokenizer = DistilBertTokenizer.from_pretrained(model_ckpt)
注意事项
当你第一次运行
AutoTokenizer.from_pretrained()方法时,你会看到一个进度条,显示预训练标记器的哪些参数从Hugging Face Hub加载。 当你第二次运行该代码时,它将从缓存中加载标记器,一般在~/.cache/huggingface。
让我们通过向它输入简单的 “对文本进行标记是NLP的一项核心任务 “的例子文本,来检查这个标记器是如何工作的:
encoded_text = tokenizer(text) print(encoded_text)
{'input_ids': [101, 19204, 6026, 3793, 2003, 1037, 4563, 4708, 1997, 17953, 2361, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]} 就像字符标记化一样,我们可以看到单词已经被映射到input_ids字段中的唯一整数。 我们将在下一节讨论attention_mask字段的作用。 目前我们有了input_ids,我们可以通过使用tokenizer的convert_ids_to_tokens()方法将它们转换为tokens:
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids) print(tokens)
['[CLS]', 'token', '##izing', 'text', 'is', 'a', 'core', 'task', 'of', 'nl', '##p', '.', '[SEP]'] 我们在这里可以观察到三件事。 第一,一些特殊的[CLS]和[SEP]标记已被添加到序列的开始和结束。 这些标记因模型而异,但它们的主要作用是指示序列的开始和结束。 第二,代币都被小写了,这是这个特定检查点的一个特点。 最后,我们可以看到,”tokenizing “和 “NLP “被分成了两个标记,这是有道理的,由于它们不是常见的词。 ##izing和##p中的##前缀意味着前面的字符串不是空白。 任何带有此前缀的标记在你将标记转换为字符串时,应与前一个标记合并。 AutoTokenizer类有一个convert_tokens_to_string()方法来做这件事,所以让我们把它应用到我们的tokens中:
print(tokenizer.convert_tokens_to_string(tokens))
[CLS] tokenizing text is a core task of nlp. [SEP] AutoTokenizer类也有几个属性,提供关于标记器的信息。 例如,我们可以检查词汇量的大小:
tokenizer.vocab_size
30522 和相应模型的最大上下文大小:
tokenizer.model_max_length
512 另一个需要了解的有趣属性是模型在其前向传递中期望的字段的名称:
tokenizer.model_input_names
['input_ids', 'attention_mask'] 目前我们对单个字符串的标记化过程有了基本了解,让我们看看如何对整个数据集进行标记化:
警告
当使用预训练的模型时,确保你使用与模型训练时一样的标记器是超级重大的。 从模型的角度来看,切换标记器就像更换词汇表一样。 如果你周围的人都开始把 “房子 “换成 “猫 “这样的随机词汇,你也会很难理解发生了什么事!
**对整个数据集进行标记化**
为了对整个语料库进行标记,我们将使用DatasetDict对象的map()方法。 在本书中,我们会多次遇到这种方法,由于它提供了一种方便的方法,可以对数据聚焦的每个元素应用处理函数。 我们很快就会看到,map()方法也可以用来创建新的行和列。
为了开始工作,我们第一需要一个处理函数来对我们的例子进行标记:
def tokenize(batch): return tokenizer(batch[“text”], padding=True, truncation=True) 这个函数将标记器应用于一批例子。 padding=True将用零填充例子,使其达到一个批次中最长的一个的大小,truncation=True将把例子截断到模型的最大上下文大小。 为了看看tokenize()的作用,让我们从训练聚焦传递一批两个例子:
print(tokenize(emotions[“train”][:2])) {'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625, 2000, 2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998, 2003, 8300, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 ,,,,],[,,,,,,,,,,,,,,,,,,,, 1, 1, 1]]} 这里我们可以看到填充的结果。 input_ids的第一个元素比第二个短,所以在这个元素上加了零,使它们的长度一样。 这些零在词汇中都有一个相应的[PAD]标记,特殊标记集还包括我们之前遇到的[CLS]和[SEP]标记:

还要注意的是,除了返回编码后的推文作为input_ids外,tokenizer还返回一个attention_mask数组的列表。 这是由于我们不希望模型被额外的填充标记所迷惑。 注意力掩码允许模型忽略输入的填充部分。 图2-3直观地解释了输入ID和注意掩码的填充方式。
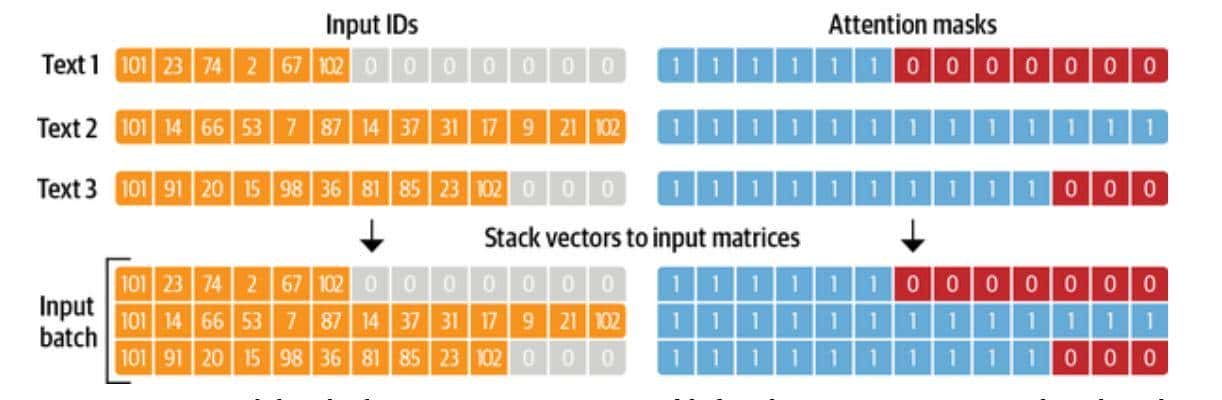
一旦我们定义了一个处理函数,我们就可以用一行代码将其应用于语料库中的所有分片:
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None) 默认情况下,map()方法对语料库中的每个例子进行单独操作,所以设置batched=True将对推文进行分批编码。 由于我们设置了batch_size=None,我们的tokenize()函数将作为一个批次应用于整个数据集。 这确保了输入张量和注意力掩码在全球范围内具有一样的形状,我们可以看到这个操作为数据集增加了新的输入_ids和注意力掩码列:
print(emotions_encoded[“train”].column_names)
['attention_mask', 'input_ids', 'label', 'text']
术语普及
**1)公开数据集构成**

train训练集相当于上课学知识,用来训练模型使用的。 validation验证集相当于课后的的练习题,用来纠正和强化学到的知识。通过调整超参数,让模型处于最好的状态。 test测试集相当于期末考试,用来最终评估学习效果。通过测试集(Test Dataset)来做最终的评估。
**2)数据集格式之arrow**
.arrow是Apache Arrow的文件格式,它是一种内存数据结构序列化和传输的标准化格式。Arrow旨在提供跨不同编程语言和计算平台的统一数据格式,以便
**3)Pandas DataFrame**
Pandas DataFrame是一种二维表格数据结构,可以理解为Excel中的工作表或SQL中的表。Pandas是Python中的一个开源数据分析库,提供了各种数据操作和分析的功能,而DataFrame是其中最重大和最常用的数据结构之一。
DataFrame主要有以下特点:
1)由行和列组成,每个列可以有不同的数据类型。 2)可以通过行名和列名来访问元素。 3)支持对数据进行切片、过滤、聚合等操作。 4)可以读取多种文件格式(如CSV、Excel、SQL等)并生成DataFrame对象。 创建DataFrame的方法许多,下面是一个简单的示例代码:
输出结果为:
以上示例中,创建了一个包含三列(name、age、gender)和三行(Alice、Bob、Charlie)的DataFrame。其中,每一列对应字典data中一样键名下的值。可以用print(df)输出整个DataFrame。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录







收藏了,感谢分享