 的所有段落连接起来,形成一个特定于主题的文本组(TTG)
的所有段落连接起来,形成一个特定于主题的文本组(TTG) ,其中包含关于一个实体的特定主题的显著信息:
,其中包含关于一个实体的特定主题的显著信息:
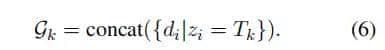

 的长度就是TTG中关于
的长度就是TTG中关于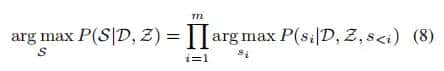
 ,作者第一用一个GRU解码器来预测每个句子
,作者第一用一个GRU解码器来预测每个句子 的主题分布。在每个时间步长
的主题分布。在每个时间步长 ,然后估计主题概率分布
,然后估计主题概率分布 。
。
 可以看作是
可以看作是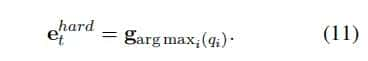
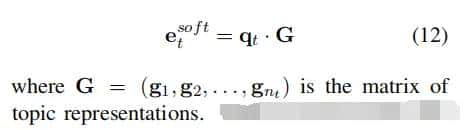
 ,它作为句子解码器的初始隐藏状态:
,它作为句子解码器的初始隐藏状态:

 的隐藏状态
的隐藏状态 ,这是通过拼接所有TTG的token隐藏状态而获得的:
,这是通过拼接所有TTG的token隐藏状态而获得的:
 ,其中每个元素
,其中每个元素 可以被视为第
可以被视为第 个token被选择的概率。
个token被选择的概率。
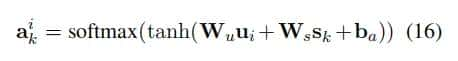
 是解码器中的隐藏状态
是解码器中的隐藏状态 表明主题感知表明包含其中,
表明主题感知表明包含其中, ,
, ,
, 是可训练的参数。
是可训练的参数。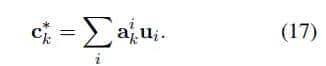
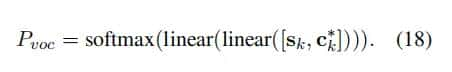
 、解码器隐藏状态
、解码器隐藏状态 计算
计算 :
: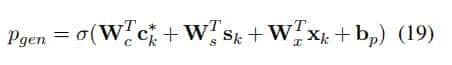
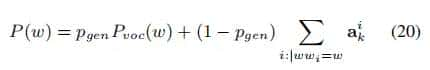
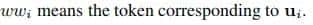

Zhu F, Tu S, Shi J, et al. TWAG: A Topic-Guided Wikipedia Abstract Generator[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 4623-4635.
注:该论文的阅读只包含对模型的记录。由于该任务笔者并不清楚。
摘要翻译
维基百科摘要生成旨在从web来源中提取出一个维基百科摘要,通过采用多文档摘要技术已经取得了重大成功。不过,以往的工作一般将抽象视为纯文本,忽略了它是对某个实体的描述,可以分解为不同的主题的实际。在本文中,作者提出了一个两阶段的模型TWAG,以指导与主题信息的抽象生成。第一,用一个对现有的维基百科文章进行训练的分类器来检测每个输入段落的主题,从而将输入文档划分为不同的主题。然后,预测每个摘要文本句的主题分布,并利用指针生成器网络对主题感知表明进行解码。该模型在维基库数据集上进行了评估,结果表明,TWAG优于各种现有的基线,并且能够生成全面的摘要。
符号定义
这里的符号定义不做完全说明。只是为了了解模型的输入以及输出目标。
输入为Wikipedia的文本段落,记为 。目标输出为:
。目标输出为: ,模型的母的是寻找最优摘要
,模型的母的是寻找最优摘要 。
。

模型浅析
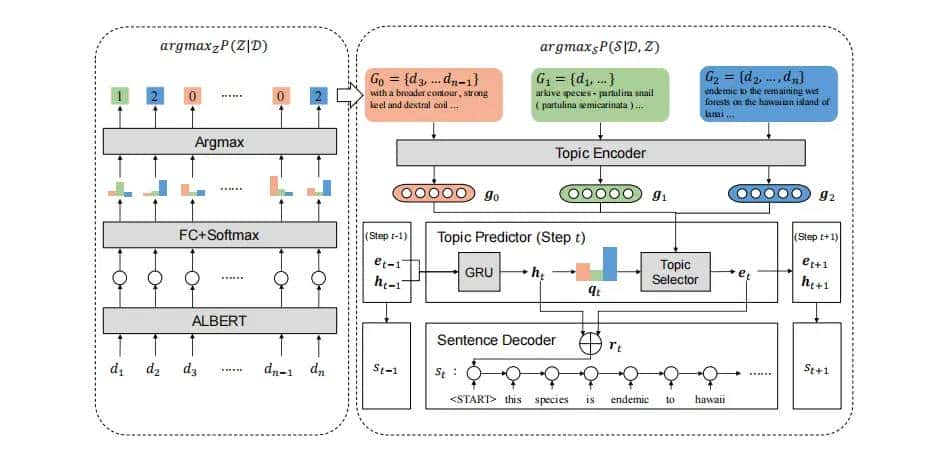
主题检测模块
主题检测器旨在用最优对应的对应主题注释输入段落。为了形式化,给定输入的段落,检测器Det返回其相应的主题 。
。

这里作者是将主题检测看做一个分类任务。
对于每一段 ,使用albert编码,然后用一个全连接层预测其主题
,使用albert编码,然后用一个全连接层预测其主题 。
。

因此对于一个输入 而言,每个段落的主题预测是相互独立的,是分别输入ALBERT进行检测。图中很容易给人造成同时输入的误解。
而言,每个段落的主题预测是相互独立的,是分别输入ALBERT进行检测。图中很容易给人造成同时输入的误解。
经过主题检测模块,可以获得中每个段落对应的主题,这部分将在文本摘要中产生主题引导效用。
基于主题感知的摘要生成模块
具有主题感知功能的摘要生成器利用输入和检测到的主题 来生成摘要。具体来说,它包含三个模块:一个主题编码器,将输入段落编码为主题表明;一个预测摘要句子的主题分布并生成主题感知句子表明的主题预测器;以及一个基于主题感知表明生成摘要句子的句子解码器。
来生成摘要。具体来说,它包含三个模块:一个主题编码器,将输入段落编码为主题表明;一个预测摘要句子的主题分布并生成主题感知句子表明的主题预测器;以及一个基于主题感知表明生成摘要句子的句子解码器。
- 主题编码器
给定输入的段落 和检测到的主题,将属于同一主题的所有段落连接起来,形成一个特定于主题的文本组(TTG),其中包含关于一个实体的特定主题的显著信息:
和检测到的主题,将属于同一主题的所有段落连接起来,形成一个特定于主题的文本组(TTG),其中包含关于一个实体的特定主题的显著信息:
为了进一步捕获隐藏的语义,我们使用一个双向GRU来对TTG进行编码:
这里
的长度就是TTG中关于所拼接的文本段落的长度,(为了和之后的生成任务匹配)这里输入GRU是一般所用的词级别的token。
这一步有点疑问,就是原本通过主题组合的文本还具有上下文联系么?? - 主题预测器
在将主题编码为隐藏状态后,TWAG以句子的方式处理解码过程:为了生成摘要
,作者第一用一个GRU解码器来预测每个句子的主题分布。在每个时间步长中,主题预测器产生一个全局隐藏状态,然后估计主题概率分布。可以看作是时刻的主题选择器,这里作者给出了两种主题选择的方式:
(1)选择概率最高的主题对应的作为表明:(2)使用软概率分布,即认为每个句子由概率不同的混合主题表明,这些主题之间按照权重叠加生成:
实则在实际的生活中,soft topic更加符合对句子的描述,即便所关注的句子主要包含一个主题,我们可以使得其他主题概率较小,就可以达到hard topic的效果。因此,soft topic更加适用。
最后,通过相加和来计算具有主题感知的隐藏状态,它作为句子解码器的初始隐藏状态:此外,在每个时间步长中都会执行一个停止确认条件:
- 句子解码器
句子解码器采用了指针生成器网络,它从输入的段落和词汇中选择标记。
为了从输入段落中复制一个token,解码器需要所有输入标记的token的隐藏状态,这是通过拼接所有TTG的token隐藏状态而获得的:
对于第k个token,解码器计算在输入段落中的token上的注意力分布,其中每个元素可以被视为第个token被选择的概率。
其中
是解码器中的隐藏状态表明主题感知表明包含其中,,,是可训练的参数。
为了从词汇表中生成一个标记,作者采取了3个步骤:
a. 使用注意机制来计算编码器隐藏状态的加权和,称为上下文向量b. 它被进一步输入到一个两层网络中,以获得词汇表上的概率分布
为了在这两种机制之间切换,从上下文向量
、解码器隐藏状态以及解码器输入计算:各权重和偏置都为可训练的参数。
最终词的概率分布为:
训练
两个主模块的训练是相互独立的:
由于主题检测的目标是一个最大化问题,因此使用负对数似然损失来优化主题检测器。
主题感知摘要生成步骤的Loss包括两部分:第一部分是每个摘要句子 的句子解码器的平均损失,第二部分是停止确认
的句子解码器的平均损失,第二部分是停止确认 的交叉熵损失。
的交叉熵损失。
关于第一部分,作者采用平均该句子中每个目标词的负对数似然值来计算一个抽象句子的损失,并通过平均所有 个句子来实现:
个句子来实现:
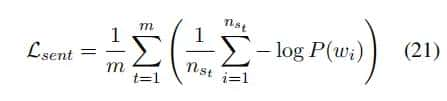
其中, 是摘要中第
是摘要中第 个句子的长度。
个句子的长度。
第二部分,采用的是交叉熵损失:

将主题巧妙的融合在生成的过程中,使得生成的文本不会造成主题语义的缺失。也就是说在生成的过程中,全面的思考了各方面的信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










