
Spring
单例bean是线程安全的吗?
简短的回答是:默认情况下,Spring容器中的单例Bean不是线程安全的。
为什么默认不是线程安全的?
单例模式的本性:Spring的单例Bean是指,在Spring IoC容器中,对于每个Bean ID,只存在一个对象实例。这意味着所有请求该Bean的线程,都在共享同一个实例。状态(State)问题:线程安全的根本问题在于“状态”,特别是“可变状态”。如果一个单例Bean包含了可变的成员变量(比如一个普通的
int
List
Map
一个不安全的例子:
@Component // 默认是单例的
public class UnsafeCounterService {
private int count = 0; // 可变的状态
public void increment() {
count++; // 非原子操作,线程不安全
}
public int getCount() {
return count;
}
}
假设两个线程A和B同时调用
increment()
它们从主内存中读取的
count
0 + 1 = 1
1
如何确保单例Bean的线程安全?
有多种策略可以解决这个问题,需要根据具体场景选择:
1. 无状态Bean(推荐)
这是最简单、最有效的方法。设计Bean时,不包含任何可变的成员变量。
@Component
public class StatelessService {
// 这个方法是线程安全的,因为它不修改任何共享状态。
// 它的结果只依赖于传入的参数。
public String process(String input) {
return "Processed: " + input.toUpperCase();
}
}
这种“无状态”的Bean,比如各种Service、Util,是Spring应用中最常见的,它们天然就是线程安全的。
2. 使用不可变对象(Immutable Objects)
如果Bean有状态,但状态在创建后就不会改变,那么它也是线程安全的。
@Component
public class AppConfig {
private final String appName;
private final String version;
// 通过构造函数注入,并且字段是final的
public AppConfig(@Value("${app.name}") String appName,
@Value("${app.version}") String version) {
this.appName = appName;
this.version = version;
}
// 只有getter,没有setter
public String getAppName() { return appName; }
public String getVersion() { return version; }
}
3. 使用同步机制(Synchronization)
当确实需要可变状态时,可以使用Java提供的同步工具。
synchronized
@Component
public class SynchronizedCounterService {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
缺点:
synchronized
使用
java.util.concurrent.atomic
@Component
public class AtomicCounterService {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 原子操作,线程安全
}
public int getCount() {
return count.get();
}
}
对于计数器这类场景,使用
AtomicInteger
使用
ReentrantLock
提供比
synchronized
4. 使用ThreadLocal
如果一个Bean需要为每个线程维护独立的状态,
ThreadLocal
RequestContextHolder
ThreadLocal
@Component
public class UserContextHolder {
private static final ThreadLocal<User> currentUser = new ThreadLocal<>();
public void setCurrentUser(User user) {
currentUser.set(user);
}
public User getCurrentUser() {
return currentUser.get();
}
public void clear() {
currentUser.remove(); // 非常重要!防止内存泄漏,尤其是在Web容器中。
}
}
5. 改变Bean的作用域
如果某个有状态的Bean确实不适合作为单例,可以考虑将其作用域改为
prototype
request
@Component
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
// 或者对于Web应用: @Scope(WebApplicationContext.SCOPE_REQUEST)
public class StatefulComponent {
private Object state;
// ... getter and setter
}
这样每次注入或从容器中获取时,都会创建一个新的实例,从而避免了共享。
总结
| 策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 无状态Bean | 业务逻辑处理、工具类 | 简单、高效、天然安全 | 不适用于需要状态的场景 |
| 不可变对象 | 配置类、常量数据 | 安全、易于理解 | 状态在创建后无法修改 |
| 同步机制 | 需要共享可变状态 | 保证数据强一致性 | 可能带来性能开销和死锁风险 |
| ThreadLocal | 需要在线程生命周期内保持状态(如用户上下文) | 高效,线程隔离 | 需要小心清理,防止内存泄漏 |
| 改变作用域 | 有状态且不适合共享的Bean | 彻底解决共享问题 | 创建和销毁开销大,可能不符合设计初衷 |
最佳实践是:尽可能将Spring Bean设计为无状态的。 这是保证线程安全最根本、最有效的方法。当无法避免有状态时,再根据具体情况选择上述的其他策略。
AOP
1. 什么是AOP?
AOP(Aspect-Oriented Programming),即面向切面编程,是一种编程范式。它的核心思想是:将那些遍布在应用多个模块中的、与核心业务逻辑无关的横切关注点(Cross-cutting Concerns)分离出来,形成独立的、可重用的模块,我们称之为“切面”(Aspect)。
一个生动的比喻:
想象一下,你的核心业务逻辑(比如用户管理、订单处理)是一串珍珠项链上的每一颗珍珠。而像日志、安全、事务这些功能,就像是穿起所有珍珠的线。AOP的作用就是把这根“线”抽离出来,进行统一管理,而不是让每颗“珍珠”自己去处理这根线。
OOP(面向对象编程) 的单元是类(Class)。AOP(面向切面编程) 的单元是切面(Aspect)。
2. AOP的作用
AOP的主要作用可以归结为两点:
代码复用与模块化:将分散在各个业务逻辑中的通用功能(如日志、事务)集中到一个地方实现,避免了代码的重复和分散。这使得代码更易于维护和理解。业务逻辑纯净化:开发者可以更专注于核心业务逻辑的开发,而无需被非功能性的需求(如记录日志、开始事务)所干扰。业务类中不再充斥着
try-catch
3. AOP的核心概念
要理解AOP,必须先理解以下几个核心术语:
Aspect(切面):横切关注点的模块化。它包含了 Advice 和 Pointcut。例如,一个“日志切面”或“事务切面”。Join Point(连接点):在程序执行过程中一个明确的点,如方法的调用、异常的抛出等。在Spring AOP中,连接点总是代表一个方法的执行。Advice(通知):切面在特定的连接点上执行的动作。有几种类型:
Before:在目标方法被调用之前执行。After:在目标方法完成之后执行(无论正常返回还是异常抛出)。After-returning:仅在目标方法成功完成后执行。After-throwing:仅在目标方法抛出异常后执行。Around:最强大的通知。它包围了连接点,可以在方法调用前后执行自定义行为,并决定是否继续执行连接点或者直接返回它自己的返回值或抛出异常。
Pointcut(切点):一个匹配连接点的谓词(表达式)。通知(Advice)会与一个切点表达式关联。切点定义了“在哪里(Where)”执行通知。Target Object(目标对象):被一个或多个切面所通知的对象。也就是我们真正的业务逻辑对象。Weaving(织入):将切面应用到目标对象,并创建代理对象的过程。Spring AOP在运行时完成织入。
4. Spring AOP的实现原理
Spring AOP的底层是通过动态代理来实现的。它并不修改目标类的字节码,而是在运行时动态地生成一个代理对象,这个代理对象会包裹目标对象,并在调用目标方法的前后,执行切面中定义的逻辑。
Spring AOP根据目标对象是否实现了接口,来选择使用哪种代理方式:
a) JDK 动态代理(默认策略)
条件:如果目标对象实现了至少一个接口。原理:Spring会使用JDK内置的
java.lang.reflect.Proxy
InvocationHandler
invoke
b) CGLIB 代理
条件:如果目标对象没有实现任何接口。原理:Spring会使用CGLIB库,通过继承目标类来生成其子类,并重写父类的方法。这个子类就是代理对象。调用流程:当调用代理对象的方法时,会调用重写后的方法,在这个方法中,Spring会执行相关的通知链,并最终通过
super
final
重要结论:Spring AOP创建的代理对象,在调用方法时,实际上是在调用代理对象的方法,代理对象在内部负责调用通知链和目标方法。
5. 常见的使用场景
AOP在实际项目中应用非常广泛,以下是一些经典场景:
声明式事务管理(@Transactional)
这是Spring AOP最成功、最经典的应用。通过在方法或类上添加
@Transactional
beginTransaction()
commit()
日志记录
统一为所有Service层的方法记录入参、出参、执行时间等,而无需在每个方法中编写
log.info(...)
安全和权限检查
在方法执行前,通过
@Before
性能监控
使用
@Around
异常处理和统一响应封装
使用
@AfterThrowing
缓存
在方法执行前检查缓存,如果缓存中存在数据则直接返回;方法执行后将结果放入缓存。
示例代码:一个简单的日志切面
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
@Aspect // 声明这是一个切面
@Component // 让Spring管理这个Bean
public class LoggingAspect {
// 定义切点:匹配 com.example.service 包下所有类的所有方法
@Pointcut("execution(* com.example.service.*.*(..))")
public void serviceLayer() {}
// Around通知是最强大的,可以控制是否执行目标方法
@Around("serviceLayer()")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
// 继续执行目标方法
Object result = joinPoint.proceed();
long executionTime = System.currentTimeMillis() - start;
// 记录日志
System.out.println(joinPoint.getSignature() + " executed in " + executionTime + "ms");
return result;
}
// Before通知,在目标方法执行前运行
@Before("serviceLayer()")
public void logMethodCall(JoinPoint joinPoint) {
System.out.println("Calling method: " + joinPoint.getSignature().getName());
}
// AfterThrowing通知,在目标方法抛出异常时运行
@AfterThrowing(pointcut = "serviceLayer()", throwing = "ex")
public void logException(JoinPoint joinPoint, Exception ex) {
System.out.println("Method " + joinPoint.getSignature().getName() + " threw exception: " + ex.getMessage());
}
}
总结
| 特性 | 描述 |
|---|---|
| 目标 | 解耦横切关注点,使业务逻辑更纯净。 |
| 核心概念 | Aspect, Joinpoint, Advice, Pointcut, Weaving。 |
| 实现机制 | 动态代理(JDK代理 或 CGLIB代理)。 |
| 织入时机 | 运行时。 |
| 适用范围 | Spring管理的Bean(单例为主)。 |
| 能力限制 | 只能对方法级别的连接点进行拦截(如方法调用),不能拦截字段访问。 |
| 常见场景 | 事务、日志、安全、缓存、性能监控、异常处理。 |
Spring中的事务
Spring事务的实现原理
Spring事务的本质是 声明式事务管理,其核心实现原理可以概括为:通过AOP(面向切面编程)在运行时为目标方法创建代理对象,并在方法调用前后拦截,根据事务属性(如传播行为、隔离级别等)来开启、提交或回滚事务。
核心实现步骤:
解析注解(@Transactional)
当Spring容器启动时,它会扫描所有Bean。如果发现某个类或方法上存在
@Transactional
propagation
isolation
创建代理对象
Spring使用AOP机制,为这个目标Bean动态地创建一个代理对象(Proxy)。这个代理对象包装了原始的目标对象。和我们之前讨论的一样,如果目标对象实现了接口,默认使用JDK动态代理;否则使用CGLIB代理。
执行拦截(核心)
当客户端(比如Controller)调用这个Bean的某个方法时,实际上调用的是代理对象的方法。代理对象会检查当前被调用的方法是否需要开启事务(通过之前解析的注解信息)。如果需要,代理对象会通过事务管理器(PlatformTransactionManager) 在方法执行前开启一个数据库连接并设置事务属性(比如设置隔离级别,将
autoCommit
false
执行目标方法
在事务上下文中,代理对象通过反射调用原始目标对象的方法。
提交或回滚
如果目标方法成功执行完毕,没有抛出异常,事务管理器会提交事务(
connection.commit()
RuntimeException
Error
connection.rollback()
核心组件:
@Transactional
PlatformTransactionManager
getTransaction()
commit()
rollback()
常用实现类:
DataSourceTransactionManager
JpaTransactionManager
HibernateTransactionManager
TransactionInterceptor
PlatformTransactionManager
Spring事务常见的失效场景
事务失效是一个非常常见且令人困惑的问题。以下场景是导致事务失效的“重灾区”,需要特别注意。
1. 事务方法非
public
public
原因:Spring AOP(基于CGLIB或JDK代理)默认只为
public
@Transactional
protected
private
public
2. 自调用(Method Call Within The Same Class)
这是最常见的失效场景之一。
原因:在一个Bean的内部,一个非事务方法A直接调用同一个Bean内部的事务方法B。此时,调用的是
this.B()
proxy.B()
示例:
@Service
public class OrderService {
public void createOrder(Order order) { // 非事务方法
// ... 一些逻辑
this.updateStock(order); // 自调用,事务失效!
}
@Transactional
public void updateStock(Order order) {
// 更新库存...
}
}
解决方案:
将事务方法
updateStock
@EnableAspectJAutoProxy(exposeProxy = true)
3. 异常类型不正确或被“吞掉”
原因1:异常类型非
RuntimeException
默认情况下,Spring事务只在抛出未检查的异常(即
RuntimeException
Error
Exception
IOException
@Transactional
rollbackFor
@Transactional(rollbackFor = Exception.class)
原因2:异常被捕获(“吞掉”)
如果在事务方法内部使用
try-catch
catch
示例:
@Transactional
public void updateUser(User user) {
try {
userMapper.update(user);
int i = 1 / 0; // 这里会抛出ArithmeticException
} catch (Exception e) {
// 捕获了异常,但没有重新抛出!
log.error("更新用户失败", e);
}
// 事务会在这里被提交,尽管发生了异常
}
解决方案:在
catch
throw new RuntimeException(e);
4. 数据库引擎不支持事务
原因:如果你使用的是MySQL,并且数据表使用的存储引擎是MyISAM,那么事务是不支持的。MyISAM不支持事务。解决方案:将表引擎切换为InnoDB。
5. 在非受管Bean中使用
@Transactional
@Transactional
原因:
@Transactional
@Component
@Service
@Repository
new
@Transactional
6. 传播行为(Propagation)设置不当
原因:如果事务的传播行为设置为
Propagation.NOT_SUPPORTED
Propagation.NEVER
Propagation.SUPPORTS
示例:
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void doSomething() {
// 这个方法将在非事务环境下执行,无论是否存在外部事务
}
解决方案:根据业务需求正确设置传播行为。
7. 多线程环境下
原因:Spring事务是通过
ThreadLocal
Connection
总结
Spring事务的实现是AOP动态代理的完美应用。要避免事务失效,请牢记以下几点:
检查方法修饰符:必须是
public
rollbackFor
Bean的生命周期
Spring Bean的生命周期指的是一个Bean从被创建、初始化、服务到最终被销毁的完整过程。这个过程由Spring IoC容器精心管理。
为了更直观地理解,我们可以将整个生命周期分为四个主要阶段:实例化 -> 属性赋值 -> 初始化 -> 销毁。
下面是一个非常详细的步骤分解,其中包含了容器级(BeanFactory)和Bean级的关键节点。
Bean生命周期的详细步骤(以AnnotationConfigApplicationContext为例)
第一阶段:Bean的实例化与属性赋值
实例化(Instantiate)
动作:Spring容器首先调用Bean的构造器(默认是无参构造,或指定的有参构造),在JVM堆上分配内存空间,创建一个原始的、未初始化的对象。这步就像是
new Object()
getBean()
属性赋值(Populate Properties)
动作:Spring解析Bean的依赖关系,并通过以下方式为Bean的属性(字段)注入值:
通过
@Autowired
@Inject
@Value
<property>
注意:此时Bean的依赖对象(其他Bean)也会被递归地创建和注入。
第二阶段:Bean的初始化
这是生命周期中最复杂、最可扩展的阶段,充满了各种“回调”机制。
检查Aware系列接口(Aware Interface Injection)
动作:如果Bean实现了各种
Aware
BeanNameAware
setBeanName(String name)
BeanFactoryAware
setBeanFactory(BeanFactory beanFactory)
ApplicationContextAware
setApplicationContext(ApplicationContext applicationContext)
EnvironmentAware
ResourceLoaderAware
BeanPostProcessor前置处理
动作:Spring容器中所有实现了
BeanPostProcessor
postProcessBeforeInitialization(Object bean, String beanName)
AnnotationAwareAspectJAutoProxyCreator
BeanPostProcessor
@PostConstruct注解方法
动作:如果Bean的方法上标注了
@PostConstruct
InitializingBean接口
动作:如果Bean实现了
InitializingBean
afterPropertiesSet()
自定义初始化方法(init-method)
动作:如果在Bean定义中指定了自定义的初始化方法(如通过
@Bean(initMethod = "myInit")
init-method
BeanPostProcessor后置处理
动作:所有
BeanPostProcessor
postProcessAfterInitialization(Object bean, String beanName)
至此,一个Bean已经完全准备就绪,被放在了Spring的单例缓存池中,可以被应用程序请求和使用了。
第三阶段:Bean的使用期
Bean的存活期
Bean驻留在应用上下文中,处理业务逻辑,直到应用上下文被销毁。
第四阶段:Bean的销毁
当Spring容器(通常是
ApplicationContext
close()
@PreDestroy注解方法
动作:如果Bean的方法上标注了
@PreDestroy
DisposableBean接口
动作:如果Bean实现了
DisposableBean
destroy()
自定义销毁方法(destroy-method)
动作:如果在Bean定义中指定了自定义的销毁方法(如通过
@Bean(destroyMethod = "myDestroy")
destroy-method
注意:对于原型(prototype) Bean,Spring容器只负责到初始化阶段结束,之后就将完整的Bean交给客户端管理,不会调用其任何销毁方法。
流程图总结
flowchart TD
A[开始: 容器启动] --> B[1、实例化 Bean:调用Bean的构造器]
B --> C[2、填充属性/依赖注入]
C --> L
subgraph L [Aware 接口]
direction TB
D1[3、BeanNameAware]
D1 --> D2[4、BeanFactoryAware]
D2 --> D3[5、ApplicationContextAware]
end
D3 --> E[6、BeanPostProcessor<br>postProcessBeforeInitialization]
E --> F[初始化阶段]
F --> F1[7、@PostConstruct]
F1 --> F2[8、InitializingBean<br>afterPropertiesSet]
F2 --> F3[9、自定义 init-method]
F3 --> G[10、BeanPostProcessor<br>postProcessAfterInitialization]
G --> H[✅ Bean 就绪, 可使用]
H --> I{容器关闭}
I --> J[销毁阶段]
J --> J1[11、@PreDestroy]
J1 --> J2[12、DisposableBean destroy]
J2 --> J3[13、自定义 destroy-method]
J3 --> K[结束: Bean 被销毁]
代码示例
@Component
public class MyBean implements BeanNameAware, ApplicationContextAware, InitializingBean, DisposableBean {
@Autowired
private AnotherBean anotherBean;
public MyBean() {
System.out.println("1. 构造器调用");
}
@Override
public void setBeanName(String name) {
System.out.println("3.1 BeanNameAware: " + name);
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
System.out.println("3.2 ApplicationContextAware");
}
@PostConstruct
public void postConstruct() {
System.out.println("5. @PostConstruct方法调用");
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("6. InitializingBean.afterPropertiesSet()调用");
}
// 通过@Bean的initMethod指定
public void myInit() {
System.out.println("7. 自定义init-method调用");
}
@PreDestroy
public void preDestroy() {
System.out.println("9. @PreDestroy方法调用");
}
@Override
public void destroy() throws Exception {
System.out.println("10. DisposableBean.destroy()调用");
}
// 通过@Bean的destroyMethod指定
public void myDestroy() {
System.out.println("11. 自定义destroy-method调用");
}
}
// 一个BeanPostProcessor的实现
@Component
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("4. BeanPostProcessor.postProcessBeforeInitialization");
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("8. BeanPostProcessor.postProcessAfterInitialization");
}
return bean;
}
}
运行输出顺序将与上述流程图中的编号完全对应。
总结
Spring Bean的生命周期是一个精心设计的、可高度扩展的过程。理解它有助于你:
精准定位问题:当Bean的创建、依赖注入或销毁出现问题时,你可以清楚地知道在哪个环节出了错。高效进行扩展:知道在什么时候、通过什么方式(
Aware
BeanPostProcessor
@PostConstruct
Bean的循环依赖
好的,我们来详细探讨Spring中一个经典且重要的问题——Bean的循环依赖。
1. 什么是循环依赖?
循环依赖指的是两个或多个Bean之间相互依赖,形成一个闭环的依赖关系。
常见的三种情况:
相互依赖:A依赖B,同时B也依赖A
@Component
public class A {
@Autowired
private B b;
}
@Component
public class B {
@Autowired
private A a;
}
自我依赖:A依赖A自身(理论上存在,实践中较少)
@Component
public class A {
@Autowired
private A a; // 自己依赖自己
}
间接循环依赖:A依赖B,B依赖C,C依赖A
// A -> B -> C -> A
2. Spring如何解决循环依赖?
Spring通过三级缓存的机制来解决单例Bean的循环依赖问题。这是Spring框架中非常精妙的设计。
三级缓存结构:
Spring在
DefaultSingletonBeanRegistry
一级缓存(singletonObjects):
ConcurrentHashMap<String, Object>
存放完全初始化好的Bean实例”成品”缓存
二级缓存(earlySingletonObjects):
HashMap<String, Object>
存放早期暴露的Bean实例(刚实例化,但未完成属性注入和初始化)”半成品”缓存
三级缓存(singletonFactories):
HashMap<String, ObjectFactory<?>>
存放Bean的对象工厂,用于生成早期引用”工厂”缓存
3. 详细解决流程(以A、B相互依赖为例)
让我们通过一个具体的流程来看Spring如何破解这个”死循环”:
@Component
public class A {
@Autowired
private B b;
}
@Component
public class B {
@Autowired
private A a;
}
创建流程如下:
步骤1:开始创建A
Spring发现需要创建Bean A在创建之前,先将A的对象工厂放入三级缓存标记A为”正在创建中”
步骤2:实例化A
调用A的构造器,创建一个原始对象(此时b=null)注意:此时A还不是完整的Bean,但对象已经存在了
步骤3:属性注入A → 发现需要B
Spring准备为A注入属性,发现需要Bean B于是暂停A的创建,转去创建B
步骤4:开始创建B
同样,在创建B之前,将B的对象工厂放入三级缓存标记B为”正在创建中”
步骤5:实例化B
调用B的构造器,创建B的原始对象(此时a=null)
步骤6:属性注入B → 发现需要A(关键步骤!)
Spring准备为B注入属性,发现需要Bean A此时Spring不会从头创建A,而是去缓存中查找A
步骤7:从缓存中获取A的早期引用
查找顺序:
一级缓存:没有A(A还没创建完成)二级缓存:没有A三级缓存:找到了A的对象工厂!
Spring通过A的对象工厂获取A的早期引用(可能是原始对象,也可能是代理对象)将这个早期引用移动到二级缓存,同时从三级缓存移除A的对象工厂将这个早期引用注入到B中
步骤8:完成B的创建
B成功注入A的早期引用后,继续完成B的初始化B创建完成后,放入一级缓存,并从二级、三级缓存中移除B的相关信息
步骤9:回到A的创建
此时B已经创建完成,Spring将完整的B实例注入到A中继续完成A的初始化过程A创建完成后,放入一级缓存,并从二级缓存中移除A
最终结果:A和B都成功创建,并且相互注入成功!
4. 为什么需要三级缓存?
这是一个很自然的问题:为什么需要三级缓存?二级缓存不够吗?
关键在于:有些Bean可能需要被代理(如AOP),而代理对象的创建时机。
如果只有二级缓存:
当B需要A的早期引用时,如果直接返回A的原始对象但A最终可能需要被AOP代理这样B中持有的就是A的原始对象,而不是代理对象,导致问题
三级缓存的作用:
三级缓存中存储的是
ObjectFactory
// 简化的逻辑
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
// 如果Bean需要被代理(如有AOP),这里会返回代理对象
// 否则返回原始对象
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
bean = ibp.getEarlyBeanReference(bean, beanName);
}
}
}
return bean;
}
总结:三级缓存的核心价值在于延迟决策——直到真正需要早期引用时,才决定返回原始对象还是代理对象。
5. 循环依赖的局限性
Spring并非能解决所有类型的循环依赖:
✅ 可以解决的情况:
Setter注入的循环依赖字段注入(@Autowired) 的循环依赖
❌ 无法解决的情况:
构造器注入的循环依赖
@Component
public class A {
private final B b;
public A(B b) { // 构造器注入
this.b = b;
}
}
@Component
public class B {
private final A a;
public B(A a) { // 构造器注入
this.a = a;
}
}
原因:在实例化阶段就需要完整的依赖对象,但此时Bean还没创建,无法提供早期引用。
原型Bean(prototype)的循环依赖
原因:Spring不缓存原型Bean,无法提供早期引用。
@Async方法的循环依赖
原因:@Async也需要创建代理,但代理创建时机较晚。
6. 如何避免和解决循环依赖?
设计层面:
代码重构:重新设计类之间的关系,消除循环依赖使用接口:依赖接口而非具体实现应用分层:遵循清晰的分层架构(Controller → Service → Repository)
技术层面:
使用Setter/字段注入替代构造器注入
使用@Lazy注解:
@Component
public class A {
@Autowired
@Lazy // 延迟加载
private B b;
}
使用ApplicationContext.getBean()(不推荐,破坏IoC)
使用@DependsOn明确依赖顺序
总结
| 关键点 | 说明 |
|---|---|
| 解决范围 | 仅支持单例Bean的Setter/字段注入循环依赖 |
| 核心机制 | 三级缓存:singletonObjects, earlySingletonObjects, singletonFactories |
| 解决时机 | 在属性注入阶段通过暴露”早期引用”来打破循环 |
| 无法解决 | 构造器注入、原型Bean、@Async等的循环依赖 |
| 设计建议 | 优先使用构造器注入(可暴露设计问题),避免循环依赖 |
Spring MVC
Spring MVC的执行流程
好的,这是一个非常核心的面试题和知识点。我会详细拆解SpringMVC的执行流程,并分别阐述在传统JSP开发模式和前后端分离开发模式下的不同。
一、 SpringMVC 核心执行流程(通用原理)
首先,我们需要理解SpringMVC的核心架构,这个架构在两种模式下是基本一致的。它的核心是前端控制器(Front Controller)模式,所有请求都会先经过一个统一的入口。
下图清晰地展示了SpringMVC的核心执行流程:

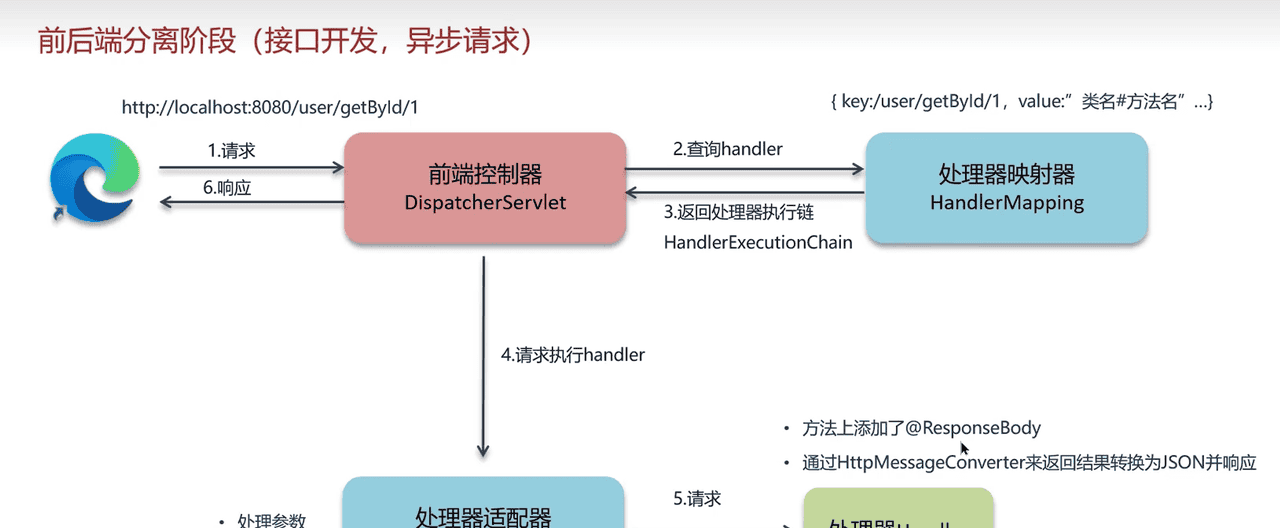
注:图片来源于黑马课件资料,如侵删
下面我们来详细解释图中的每一个步骤:
Http 请求:
用户通过浏览器或其他客户端发起一个HTTP请求。
DispatcherServlet(前端控制器):
这是整个流程的心脏。它在
web.xml
/
HandlerMapping(处理器映射器):
DispatcherServlet
HandlerMapping
/user/list
@Controller
HandlerExecutionChain
HandlerAdapter(处理器适配器):
DispatcherServlet
HandlerAdapter
Controller
@Controller
DispatcherServlet
执行处理器(Controller):
HandlerAdapter
preHandle
ModelAndView
"userList"
@ResponseBody
处理返回的Model和View:
Model(模型): Controller方法可以将数据放入Model(一个Map结构)中,这些数据最终会暴露给视图使用。View(视图): Controller返回的视图名(如
"userList"
ViewResolver(视图解析器):
DispatcherServlet
"userList"
ViewResolver
ViewResolver
View
InternalResourceViewResolver
"userList"
/WEB-INF/jsp/userList.jsp
视图渲染(View Render):
DispatcherServlet
View
postHandle
返回响应:
将渲染好的HTML内容作为HTTP响应返回给客户端。最终,会触发拦截器的
afterCompletion
二、 传统JSP开发模式下的执行流程
在这种模式下,前端(JSP)和后端(Controller)是强耦合的。Controller负责处理业务逻辑,并准备数据,最后跳转到一个JSP页面来展示。
特点:
Controller方法返回类型通常是
String
ModelAndView
InternalResourceViewResolver
Model
ModelMap
HttpServletRequest
流程示例(以查询用户列表为例):
请求
http://localhost:8080/app/user/list
DispatcherServlet
HandlerMapping
UserController
listUsers()
HandlerAdapter
listUsers()
在
listUsers()
@RequestMapping("/list")
public String listUsers(Model model) {
// 调用Service层获取用户列表
List<User> userList = userService.getAllUsers();
// 将数据放入Model,供JSP使用
model.addAttribute("users", userList);
// 返回视图名 "userList"
return "userList";
}
ViewResolver
/WEB-INF/jsp/
.jsp
"userList"
/WEB-INF/jsp/userList.jsp
DispatcherServlet
users
/WEB-INF/jsp/userList.jsp
JSP 文件使用EL表达式和JSTL标签渲染页面:
<c:forEach items="${users}" var="user">
<tr>
<td>${user.name}</td>
<td>${user.email}</td>
</tr>
</c:forEach>
生成的HTML被返回给浏览器。
三、 前后端分离开发模式下的执行流程
在这种模式下,后端(SpringMVC)只负责提供RESTful API,返回纯数据(通常是JSON/XML),不再负责视图渲染。前端(如Vue, React, Angular)是一个独立的工程,通过Ajax调用后端的API获取数据,然后在浏览器中动态渲染页面。
特点:
Controller方法上使用
@RestController
@ResponseBody
HttpMessageConverter
MappingJackson2HttpMessageConverter
流程示例(同样以查询用户列表为例):
前端Vue应用发起一个Ajax请求:
GET http://localhost:8080/api/users
DispatcherServlet
HandlerMapping
UserApiController
getUsers()
HandlerAdapter
getUsers()
在
getUsers()
@RestController // 等同于 @Controller + @ResponseBody
@RequestMapping("/api")
public class UserApiController {
@GetMapping("/users")
public List<User> getUsers() {
// 调用Service层获取用户列表
List<User> userList = userService.getAllUsers();
// 直接返回对象,而不是视图名
return userList;
}
}
因为类上有
@RestController
SpringMVC会遍历所有已配置的
HttpMessageConverter
application/json
MappingJackson2HttpMessageConverter
该转换器调用Jackson库,将
List<User>
关键区别:
ViewResolver
生成的JSON数据(如
[{"name":"张三", "email":"zhangsan@example.com"}, ...]
前端Vue应用接收到JSON数据后,使用JavaScript动态更新DOM,将用户列表展示在页面上。
总结对比
| 特性 | JSP模式 | 前后端分离模式 |
|---|---|---|
| 耦合性 | 前后端耦合,后端控制页面跳转 | 前后端解耦,独立开发、部署 |
| Controller返回值 | |
任意对象(被 |
| 视图技术 | JSP, Thymeleaf, Freemarker等 | 无(后端不关心视图) |
| 数据传递 | 通过 |
通过HTTP响应体(JSON/XML)直接返回 |
| 核心组件 | |
|
| 流程关键点 | 最终会走到 |
跳过 |
Spring Boot
Spring Boot的自动配置原理
核心思想:约定优于配置
Spring Boot 自动配置的核心理念是 “约定优于配置”。它预先定义了一整套默认的 Bean 配置和应用程序结构,只要你的项目符合这些约定,就可以零配置或极简配置地运行起来。比如,当你在类路径下发现了
HikariDataSource
那么,这套“魔法”是如何实现的呢?其核心可以概括为以下几个关键步骤和注解:
@SpringBootApplication
@EnableAutoConfiguration
spring.factories
@Conditional
下面我们通过一个流程图和详细步骤来拆解这个过程。
flowchart TD
A[“主类: @SpringBootApplication”] --> B[“开启: @EnableAutoConfiguration”]
B --> C[“加载: META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports”]
C --> D{遍历所有自动配置类<br>XxxAutoConfiguration}
subgraph E [条件化装配]
direction TB
D --> F[“评估条件注解<br>@ConditionalOnClass, <br>@ConditionalOnBean, <br>@ConditionalOnProperty等”]
F --> G{所有条件满足?}
end
G -- 是 --> H[“装配该自动配置类<br>将@Bean加入IoC容器”]
G -- 否 --> I[“忽略该自动配置类”]
H --> J[“应用成功启动<br>具备所有所需功能”]
I --> J
详细执行流程拆解
第1步:起点 –
@SpringBootApplication
@SpringBootApplication
一切的起点都是我们的 Spring Boot 主类上的
@SpringBootApplication
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
这个注解是一个复合注解,它包含了三个核心注解:
@SpringBootConfiguration // 实质上就是 @Configuration,标记该类为配置类
@EnableAutoConfiguration // 核心!启用自动配置机制
@ComponentScan // 扫描当前包及其子包下的组件(@Component, @Service, @Controller等)
其中,
@EnableAutoConfiguration
第2步:激活 –
@EnableAutoConfiguration
@EnableAutoConfiguration
@EnableAutoConfiguration
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
// ...
}
这里的核心是
AutoConfigurationImportSelector
@Import
AutoConfigurationImportSelector
第3步:加载 –
AutoConfigurationImportSelector
spring.factories
AutoConfiguration.imports
AutoConfigurationImportSelector
spring.factories
AutoConfiguration.imports
AutoConfigurationImportSelector
SpringFactoriesLoader
在 Spring Boot 2.7 之前:这个文件是
META-INF/spring.factories
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
spring.factories
在这个文件中,以
EnableAutoConfiguration
示例 (
AutoConfiguration.imports
...
org.springframework.boot.autoconfigure.web.servlet.DispatcherServletAutoConfiguration
org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
org.springframework.boot.autoconfigure.web.servlet.HttpEncodingAutoConfiguration
...
这个过程会加载上百个自动配置类,它们覆盖了几乎所有的常见场景。
第4步:筛选 – 条件化配置(真正的魔法所在)
如果直接把
AutoConfiguration.imports
@Conditional
每个自动配置类上都标注了若干个条件注解,只有在所有条件都满足时,这个配置类才会被启用。
常见的条件注解有:
| 注解 | 作用 |
|---|---|
|
类路径下存在指定的类时才生效。这是最常用的一个。 |
|
容器中存在指定的 Bean 时才生效。 |
|
容器中不存在指定的 Bean 时才生效。这是实现配置覆盖的关键。 |
|
指定的配置属性有特定值时才生效。 |
|
当前应用是 Web 应用时才生效。 |
|
类路径下存在指定的资源文件时才生效。 |
让我们以
DataSourceAutoConfiguration
// 1. 这是一个自动配置类
@AutoConfiguration
// 2. 条件:类路径下必须存在 DataSource.class 和 EmbeddedDatabaseType.class
@ConditionalOnClass({ DataSource.class, EmbeddedDatabaseType.class })
// 3. 条件:必须配置了 spring.datasource 相关的属性
@ConditionalOnProperty(prefix = "spring.datasource", name = "name")
public class DataSourceAutoConfiguration {
// 4. 条件:只有当容器中不存在 DataSource 类型的 Bean 时,才配置这个基本的 Hikari 数据源
@ConditionalOnMissingBean
@ConditionalOnProperty(prefix = "spring.datasource", name = "type", havingValue = "com.zaxxer.hikari.HikariDataSource", matchIfMissing = true)
public HikariDataSource dataSource(DataSourceProperties properties) {
// ... 利用 properties 创建并配置 HikariDataSource
return dataSource;
}
}
执行逻辑:
Spring Boot 尝试加载
DataSourceAutoConfiguration
我的类路径下有
DataSource
spring-boot-starter-jdbc
spring-boot-starter-data-jpa
spring.datasource.name
application.properties
spring.datasource.url
DataSource
所有条件都满足,于是
DataSourceAutoConfiguration
dataSource()
HikariDataSource
第5步:结果 – Bean 被装配到 IoC 容器
经过上述条件的层层筛选,最终只有那些符合当前应用环境和开发者配置的自动配置类会被真正启用。这些配置类中通过
@Bean
DataSource
DispatcherServlet
Jackson2ObjectMapperBuilder
如何自定义和覆盖?
自动配置并不意味着僵化。它提供了非常灵活的覆盖机制:
使用配置属性 (
application.properties/yml
spring.*
server.port=8081
显式声明自己的
@Bean
@ConditionalOnMissingBean
@Configuration
DataSource
DataSource
@ConditionalOnMissingBean
总结
Spring Boot 自动配置的原理可以精炼为:
通过
触发,读取
@EnableAutoConfiguration文件中的预定义配置类列表,并利用一套基于
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports的条件判断机制,智能地、按需地将这些配置类及其定义的 Bean 装配到当前的 Spring 容器中。
@Conditional
这套机制极大地减少了样板化的 XML 和 Java 配置,让开发者能够专注于业务逻辑,是 Spring Boot “开箱即用”体验的技术基石。
Spring中常用注解
一、 Spring Framework 核心注解
这些是Spring容器的基石,用于依赖注入(DI)和控制反转(IoC),在任何使用Spring的场景下都会用到。
1. 组件扫描与声明
| 注解 | 说明 | 对比 |
|---|---|---|
|
通用组件注解。标记一个类为Spring容器管理的Bean。 | 泛化概念 |
|
数据访问层(DAO)组件。是 |
专用于DAO层 |
|
业务逻辑层(Service)组件。是 |
专用于Service层 |
|
表现层组件。是 |
专用于Web层,可与 |
|
配置类注解。标记一个类为配置类,其内部包含多个 |
与 |
|
方法级别注解。在 |
与 |
2. 依赖注入(DI)
| 注解 | 说明 | 对比 |
|---|---|---|
|
按类型自动装配。可以用于构造器、字段、Setter方法等。是Spring的注解。 | 默认必须存在依赖,可配 |
|
按名称装配。与 |
解决 |
|
按名称自动装配。JSR-250标准注解,功能类似于 |
Java标准注解,非Spring特有 |
|
注入简单值、表达式或配置属性。可以注入基本类型、String、SpEL表达式或通过 |
用于注入简单值,而非Bean引用 |
3. 作用域与生命周期
| 注解 | 说明 |
|---|---|
|
指定Bean的作用域,如 |
|
JSR-250注解,标记一个方法在Bean初始化后执行(构造器执行之后,依赖注入完成后)。 |
|
JSR-250注解,标记一个方法在Bean被容器销毁之前执行。 |
二、 Spring MVC 注解
这些注解专门用于Web开发,处理HTTP请求和响应。
1. 请求映射
| 注解 | 说明 | 对比 |
|---|---|---|
|
通用请求映射。可以配置URL、方法(GET/POST等)、请求参数等。 | 最基础,可被其他注解替代 |
|
|
专用于处理GET请求 |
|
|
专用于处理POST请求 |
|
专用于处理PUT请求。 | RESTful风格 |
|
专用于处理DELETE请求。 | RESTful风格 |
|
专用于处理PATCH请求。 | RESTful风格 |
2. 请求参数处理
| 注解 | 说明 | 对比 |
|---|---|---|
|
获取URL查询参数或表单参数。将请求参数绑定到方法参数。 | 主要用于 |
|
获取URL路径中的变量。用于RESTful风格的URL。 | 从URL模板中提取值,如 |
|
将请求体内容(如JSON)转换为Java对象。通常用于接收前端传来的JSON数据。 | 主要用于 |
|
将请求头信息绑定到方法参数。 | 获取HTTP Header的值 |
|
将Cookie的值绑定到方法参数。 | 获取Cookie的值 |
|
1. 用于方法:将数据添加到Model。 2. 用于参数:从Model中获取数据。 |
在JSP/Thymeleaf开发中常用 |
3. 响应处理
| 注解 | 说明 | 对比 |
|---|---|---|
|
将方法返回值直接写入HTTP响应体,而不是视图名。通常用于返回JSON/XML数据。 | 前后端分离的关键 |
|
|
前后端分离开发的标准控制器注解 |
|
指定响应的HTTP状态码。 | 用于自定义返回状态码 |
4. 其他Web相关
| 注解 | 说明 |
|---|---|
|
全局异常处理。定义一个全局的、组件式的异常处理类。 |
|
方法级别注解,在 |
|
启用跨域请求支持。 |
三、 Spring Boot 核心注解
Spring Boot的注解大多以自动配置、简化部署、外部化配置为核心。
1. 启动与配置
| 注解 | 说明 | 对比 |
|---|---|---|
|
核心启动注解。它是一个复合注解,包含: 1. 2. 3. |
Spring Boot应用的入口标志 |
|
启用自动配置机制。Spring Boot会根据类路径中的jar包,自动配置应用程序。 | Spring Boot魔法的核心 |
|
标记该类是一个Spring Boot的配置类。本质上就是 |
通常由 |
2. 外部化配置
| 注解 | 说明 | 对比 |
|---|---|---|
|
将配置文件(如 |
用于将一组配置映射为一个对象 |
|
见Spring部分。在Boot中,它更常用于注入单个属性,如 |
与 |
|
指定要加载的配置文件(不限于 |
加载自定义配置文件 |
3. 条件化配置(理解自动配置的关键)
| 注解 | 说明 |
|---|---|
|
当类路径下存在指定的类时,配置才生效。 |
|
当容器中不存在指定Bean时,配置才生效。这是用户自定义Bean覆盖默认配置的关键。 |
|
当指定的配置属性有特定值时,配置才生效。 |
|
当当前应用是Web应用时,配置才生效。 |
4. 测试相关
| 注解 | 说明 |
|---|---|
|
Spring Boot应用的测试注解。它会启动一个完整的应用程序上下文,用于集成测试。 |
|
用于测试JPA切片,只配置JPA相关的部分。 |
|
用于测试Spring MVC控制器切片,不会启动完整的服务。 |
总结与区分
| 范畴 | 核心关注点 | 代表性注解 |
|---|---|---|
| Spring Framework | IoC容器、依赖注入、Bean管理 | |
| Spring MVC | Web请求处理、响应、模型视图 | |
| Spring Boot | 自动配置、快速启动、简化部署 | |
关系梳理:
Spring Framework 是基石,提供了核心的容器和DI功能。Spring MVC 是构建在 Spring Framework 之上的一个Web框架。Spring Boot 是构建在 Spring Framework 和 Spring MVC 之上的一个脚手架,它通过自动配置和一系列 Starter 依赖,极大地简化了 Spring 应用的搭建和开发。因此,一个 Spring Boot 应用会同时使用到以上三大部分的注解。
Mybatis与Mybatis Plus
Mybatis与Mybatis Plus的执行流程
一、 MyBatis 原生执行流程
MyBatis 的执行流程可以看作是 “通过接口方法调用,最终执行数据库SQL并返回结果” 的一系列精妙协作。其核心在于将 JDBC 繁琐的操作封装起来,并通过动态代理、反射等机制,让开发者能够以面向接口的方式进行数据库操作。
下图清晰地展示了 MyBatis 的核心执行流程:
flowchart TD
A[“调用Mapper接口方法”] --> B[“MyBatis代理对象”]
B --> C[“SqlSession接口<br>(如DefaultSqlSession)”]
C --> D[“Executor执行器<br>(缓存/事务管理)”]
D --> E[“MappedStatement<br>(存储SQL/参数/结果映射)”]
E --> F[“StatementHandler<br>(操作Statement对象)”]
F --> G[“ParameterHandler<br>(设置SQL参数)”]
G --> H[“TypeHandler<br>(Java-SQL类型转换)”]
H --> I[“执行JDBC操作”]
I --> J[“ResultSetHandler<br>(处理结果集)”]
J --> K[“TypeHandler<br>(SQL-Java类型转换)”]
K --> L[“返回结果对象”]
下面我们来详细解释图中的每一个步骤:
获取 SqlSessionFactory:
这是起点。MyBatis 通过读取
mybatis-config.xml
SqlSessionFactoryBuilder
SqlSessionFactory
创建 SqlSession:
通过
SqlSessionFactory.openSession()
SqlSession
selectOne
insert
update
try-with-resources
finally
获取 Mapper 接口的代理对象:
通过
sqlSession.getMapper(UserMapper.class)
执行 Mapper 接口方法:
当我们调用
userMapper.selectById(1)
invoke
内部执行流程(核心):
代理对象会找到对应的方法,并转而调用
SqlSession
selectOne
Executor(执行器):
这是核心的调度者。它负责整个 SQL 执行的流程。它维护了一级缓存(
SqlSession
StatementHandler
ParameterHandler
ResultSetHandler
MappedStatement:
这是一个非常重要的对象,它封装了我们在 Mapper XML 文件中定义的所有信息:SQL 语句、参数映射、结果集映射、缓存配置等。它通过
namespace.id
com.example.UserMapper.selectById
StatementHandler(语句处理器):
它负责创建
PreparedStatement
ParameterHandler
PreparedStatement
ParameterHandler(参数处理器):
它负责将用户传入的 Java 参数,按照
MappedStatement
PreparedStatement
TypeHandler
TypeHandler(类型处理器):
它是 Java类型 与 JDBC类型 相互转换的桥梁。例如,将
Java String
JDBC VARCHAR
java.util.Date
JDBC TIMESTAMP
执行 SQL:
StatementHandler
PreparedStatement.execute()
ResultSet
ResultSetHandler(结果集处理器):
这是最复杂的一步。它负责将
ResultSet
TypeHandler
MappedStatement
<resultMap>
返回结果:
结果被
ResultSetHandler
提交事务与关闭 SqlSession:
如果是写操作,需要手动
sqlSession.commit()
sqlSession.close()
二、 MyBatis-Plus 的执行流程
MyBatis-Plus(MP)是在 MyBatis 基础上进行增强,而非重写。因此,它的执行流程完全包含了上述 MyBatis 的原生流程,并在关键节点上插入了自己的扩展逻辑。
MP 的核心思想是:通过内置的
BaseMapper
IService
MP 对 MyBatis 流程的增强点:
启动阶段的增强:
自动扫描与注入:在应用启动时,MP 会扫描带有
@Mapper
BaseMapper
MybatisMapperProxyFactory
BaseMapper
selectById
insert
MappedStatement
执行阶段的增强(核心区别):
自定义的
SqlInjector
BaseMapper
AbstractMethod
selectById
AbstractMethod
MappedStatement
MetaObjectHandler
create_time
update_time
ParameterHandler
Interceptor
PaginationInnerInterceptor
COUNT(1)
LIMIT
Executor
三、 MyBatis 与 MyBatis-Plus 的核心区别总结
| 特性 | MyBatis(原生) | MyBatis-Plus(增强) | 区别核心 |
|---|---|---|---|
| CRUD 开发 | 需要手动编写 Mapper.java 接口和 Mapper.xml 文件,定义 SQL。 | 继承 |
MP 实现了通用 CRUD 的自动化 |
| SQL 生成方式 | 完全由开发者编写。 | 1. 通用方法由 MP 自动生成。 2. 复杂查询使用 |
MP 提供了 SQL 的自动生成与动态构建能力 |
| 分页功能 | 需要引入第三方插件(如 PageHelper)或手写分页 SQL。 | 原生支持分页插件,使用简单,与 |
MP 将分页作为内置功能 |
| 代码生成器 | 无官方工具,需依赖第三方。 | 提供强大的官方代码生成器,可快速生成 Entity、Mapper、Service、Controller 代码。 | MP 提供了标准化的开发脚手架 |
| 自动填充 | 需要手动在代码中设置,如 |
通过实现 |
MP 提供了声明式的字段填充能力 |
| 性能分析插件 | 无内置。 | 提供内置的性能分析插件,可用于输出 SQL 执行时间,帮助发现慢查询。 | MP 提供了开箱即用的运维工具 |
| 逻辑删除 | 需要手动在 SQL 中添加条件,如 |
通过 |
MP 将逻辑删除从业务逻辑提升为框架功能 |
结论
你可以将 MyBatis-Plus 理解为 MyBatis 的“超级外挂”或“自动驾驶模式”。
MyBatis 给了你一辆手动挡汽车,动力强劲、控制精准(你可以编写任意复杂的SQL),但所有操作都需要你亲力亲为。MyBatis-Plus 是在这辆手动挡汽车上,加装了一套“自动挡系统”、“自动泊车”、“定速巡航”等。你依然可以随时切换回手动模式(编写自定义XML),但在大部分平坦道路(通用CRUD)上,你可以享受自动挡的轻松与便捷。
MP 的执行流程本质上是 MyBatis 流程的扩展,它在启动时自动装配,在执行时通过拦截器和处理器进行干预,最终的目的就是极大地减少开发者的样板代码编写量,提升开发效率。
Mybatis的延迟加载
一、 什么是延迟加载?
延迟加载,也称为“懒加载”,其核心思想是:只有在真正需要使用关联对象的数据时,才去执行查询加载该对象数据的 SQL 语句。
举个经典的例子:
我们有一个
Order
User
public class Order {
private Integer id;
private String orderNo;
private Integer userId;
// 关联的用户对象
private User user; // 这是一个关联对象
}
场景对比:
非延迟加载(急切加载,Eager Loading):
当你查询一个
Order
User
-- 1. 查询订单
SELECT * FROM orders WHERE id = #{id};
-- 2. 立即查询关联用户
SELECT * FROM users WHERE id = #{userId};
缺点:即使你后续的代码根本不需要使用
order.getUser()
延迟加载:
当你查询一个
Order
Order
user
-- 1. 查询订单
SELECT * FROM orders WHERE id = #{id};
只有当你的代码第一次访问这个
user
order.getUser().getName()
-- 2. 直到调用 getUser() 时才执行
SELECT * FROM users WHERE id = #{userId};
优点:按需加载,避免了不必要的数据库查询,提升了性能。
二、 如何配置延迟加载?
延迟加载需要在 MyBatis 的全局配置文件中进行开启,并在映射文件中具体指定。
1. 全局配置(mybatis-config.xml)
<configuration>
<settings>
<!-- 开启延迟加载的全局开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为按需加载。
3.4.1版本后默认为 false,通常无需配置 -->
<setting name="aggressiveLazyLoading" value="false"/>
<!-- 设置哪些对象的方法触发加载。
true:任何方法(如toString)都会触发。
false:只有直接调用延迟对象的属性才会触发。推荐false -->
<setting name="lazyLoadTriggerMethods" value=""/>
</settings>
</configuration>
lazyLoadingEnabled
true
aggressiveLazyLoading
true
false
lazyLoadTriggerMethods
equals,clone,hashCode,toString
order.getUser().getName()
2. 映射文件配置(Mapper.xml)
在
<association>
<collection>
fetchType
<resultMap id="OrderWithUserResultMap" type="Order">
<id property="id" column="id"/>
<result property="orderNo" column="order_no"/>
<result property="userId" column="user_id"/>
<!-- 配置 user 对象的关联,并设置为延迟加载 -->
<association
property="user"
column="user_id"
javaType="User"
select="com.example.mapper.UserMapper.selectById"
fetchType="lazy"/> <!-- 关键在此:fetchType="lazy" -->
</resultMap>
<select id="selectOrderWithUser" resultMap="OrderWithUserResultMap">
SELECT * FROM orders WHERE id = #{id}
</select>
fetchType="lazy"
fetchType="eager"
select
三、 延迟加载的实现原理(核心)
MyBatis 的延迟加载是通过 动态代理(Javassist 或 CGLIB) 和 拦截器 相结合来实现的。其核心流程可以概括为以下几个步骤:
flowchart TD
A[“主查询执行<br>得到主体对象”] --> B[“为关联属性创建<br>代理对象(Proxy)”]
B --> C[“返回主体对象<br>代理对象占位关联属性”]
C --> D[“程序首次访问<br>关联属性(如.getUser)”]
D --> E[“拦截器介入<br>执行额外查询”]
E --> F[“用查询结果<br>替换代理对象”]
F --> G[“返回真实的<br>关联对象”]
下面我们来详细解释这一流程:
创建代理对象
当 MyBatis 执行主查询(例如
selectOrderWithUser
user
lazy
UserMapper.selectById
User
User_$$_jvstXX_0
Order
user
代理对象的行为
这个代理对象内部包含了加载真实数据所需的所有元信息,例如:要执行的SQL语句ID(
UserMapper.selectById
orders
user_id
SqlSession
触发加载(拦截)
当你的程序第一次访问这个代理对象的任何方法时(例如
order.getUser().getName()
MethodHandler
执行额外查询
这个
MethodHandler
SqlSession
UserMapper.selectById
User
替换与返回
一旦查询到真实的
User
order.getUser()
User
简单来说,这个代理对象就像一个“陷阱”或“哨兵”。你第一次访问它时,它就会“开枪”去数据库拉取数据,然后把真正的对象请出来,自己则退居幕后。
四、 使用延迟加载的注意事项
N+1 问题依然存在:
延迟加载并没有从根本上解决 N+1 问题,它只是将问题的发生推迟了。如果你遍历100个订单,并且每个订单都访问了
getUser()
JOIN
序列化问题:
如果一个被延迟加载的对象被序列化(例如,在RPC调用中通过网络传输),那么在其反序列化的另一端,当访问延迟属性时,可能会因为缺少
SqlSession
关联深度:
要小心复杂的延迟加载关联链(如 A->B->C->D),这可能会导致在你不经意的时候触发多次数据库查询,使得性能问题在后期才暴露。
总结
MyBatis 的延迟加载是一个通过动态代理实现的、按需加载关联数据的机制。它通过在访问时拦截方法调用来触发额外的SQL查询。
优点:对于不确定是否需要使用关联数据的场景,能有效减少初始数据库查询的负载,提升性能。缺点:可能将 N+1 问题后置,需要在设计和编码时明确知道数据的访问路径,避免在循环中触发。
Mybatis的一级、二级缓存
好的,这是一个非常关键的话题,尤其是在涉及高并发和数据一致性场景时。下面我将详细解析 MyBatis 的一级缓存和二级缓存,并重点探讨它们可能带来的数据一致性问题。
一、 MyBatis 一级缓存
1. 定义与范围
范围:SqlSession 级别。生命周期:与一个
SqlSession
SqlSession
clearCache()
2. 工作机制
在同一个
SqlSession
flowchart TD
A[“第一次查询<br>selectById”] --> B[“查询一级缓存<br>是否存在?”]
B -- 缓存未命中 --> C[“执行数据库查询”]
C --> D[“将结果存入<br>一级缓存”]
D --> E[返回结果]
F[“第二次查询<br>selectById”] --> G[“查询一级缓存<br>是否存在?”]
G -- 缓存命中 --> H[“直接从缓存中<br>返回结果”]
H --> I[返回结果]
第一次查询:执行
selectById(1)
selectById(1)
3. 缓存失效时机
一级缓存并非一直有效,在以下操作后会自动清空:
执行了 INSERT、UPDATE、DELETE 语句:无论这些语句是否修改了缓存中的数据,只要执行了,整个
SqlSession
sqlSession.clearCache()
<select flushCache="true">
二、 MyBatis 二级缓存
1. 定义与范围
范围:Mapper (Namespace) 级别。生命周期:与应用生命周期相同。多个
SqlSession
2. 工作机制与配置
二级缓存的工作流程比一级缓存更复杂,涉及事务提交:
flowchart TD
A[“SqlSession1<br>查询数据”] --> B[“查询二级缓存?”]
B -- 未命中 --> C[“查询数据库”]
C --> D[“在事务提交后<br>将数据存入二级缓存”]
E[“SqlSession2<br>查询相同数据”] --> F[“查询二级缓存?”]
F -- 命中 --> G[“从二级缓存<br>返回数据”]
H[“SqlSession3<br>执行更新”] --> I[“更新数据库”]
I --> J[“在事务提交后<br>清空整个Mapper二级缓存”]
开启步骤:
全局开关(mybatis-config.xml):
<settings>
<!-- 默认是false -->
<setting name="cacheEnabled" value="true"/>
</settings>
在 Mapper.xml 中开启:
<mapper namespace="com.example.mapper.UserMapper">
<!-- 启用二级缓存 -->
<cache
eviction="LRU"
flushInterval="60000"
size="512"
readOnly="true"/>
<!-- 或者简单使用 <cache/> 用默认配置 -->
<select id="selectById" resultType="User" useCache="true">
select * from user where id = #{id}
</select>
</mapper>
eviction
LRU
FIFO
flushInterval
size
readOnly
true
false
实体类序列化:由于二级缓存可能将数据写入磁盘或通过网络传输(在分布式缓存中),因此对应的实体类(如
User
Serializable
3. 二级缓存的关键特性
事务性:只有当
SqlSession
commit()
close()
SqlSession1
SqlSession2
三、 数据一致性问题
答案是:会,如果使用不当,MyBatis 的缓存确实会造成数据一致性问题。
1. 一级缓存的数据一致性问题
场景:在同一个
SqlSession
你查询了 id=1 的用户,用户名为 “Alice”。这个结果被存入一级缓存。随后,另一个应用程序或另一个
SqlSession
SqlSession
结论:一级缓存导致了脏读。你读到的数据是一个过时的副本。
解决方案:
对于要求强一致性的操作,可以在查询语句上配置
flushCache="true"
sqlSession.clearCache()
SqlSession
SqlSessionTemplate
SqlSession
2. 二级缓存的数据一致性问题
二级缓存的问题更为严重和复杂。
场景1:多表关联操作
假设你有
OrderMapper
UserMapper
OrderMapper
JOIN
User
OrderMapper
UserMapper
UserMapper
OrderMapper
OrderMapper
结论:因为跨了不同的 Mapper Namespace,导致了缓存数据与数据库不一致。
场景2:多系统共享数据库
在分布式或微服务架构下,多个应用实例共享同一个数据库。
服务A通过 MyBatis 更新了数据,并清空了它自己进程内的二级缓存。服务B的 MyBatis 二级缓存对此一无所知,它仍然持有旧的缓存数据。服务B后续的查询会返回脏数据。
结论:进程内的缓存无法感知其他进程对数据的修改。
四、 如何应对一致性问题?(最佳实践)
审慎使用二级缓存:
二级缓存适用于 读多写少、数据更新频率低、对数据一致性要求不苛刻 的场景,比如配置信息、静态数据。对于交易、订单等核心业务数据,强烈不建议使用二级缓存,因为一致性问题带来的风险远高于性能提升。
使用更高级的分布式缓存:
如果确实需要缓存且是分布式环境,应放弃 MyBatis 自带的二级缓存。集成 Redis、Memcached 等分布式缓存作为二级缓存。这样所有应用实例都连接同一个缓存中间件,可以保证缓存的一致性。MyBatis 提供了
org.apache.ibatis.cache.Cache
设计清晰的缓存策略:
对于一级缓存,保持
SqlSession
<association>
<collection>
在查询语句上精细控制:
对于实时性要求高的查询,在
<select>
useCache="false"
flushCache="true"
<select id="selectRealTimeData" useCache="false" flushCache="true">
...
</select>
总结
| 缓存级别 | 范围 | 默认 | 一致性风险 | 使用建议 |
|---|---|---|---|---|
| 一级缓存 | |
开启 | 高(在长会话中) | 保持 |
| 二级缓存 | |
关闭 | 非常高(跨命名空间、分布式) | 谨慎使用。仅用于只读或低一致性场景。生产环境建议用 Redis 等替代。 |
核心结论:MyBatis 的缓存,尤其是二级缓存,在带来性能提升的同时,引入了显著的数据一致性风险。在现代应用开发中,对于需要强一致性的业务,普遍的做法是禁用二级缓存,并通过外部集中式缓存(如Redis) 来承担缓存职责,从而在性能和一致性之间取得更好的平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...






