序
“前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。https://www.captainbed.cn/gy
一、引言:大模型时代的架构演进
2025年,人工智能领域正经历着从通用模型向专业化、高效化方向的深刻变革。Transformer架构作为自然语言处理(NLP)的基石,其自注意力机制通过并行计算捕捉序列中的全局依赖关系,成为机器翻译、文本生成等任务的核心技术。然而,随着模型规模突破万亿参数,传统Transformer的计算效率瓶颈日益凸显。混合专家模型(MoE)通过引入“条件计算”机制,将单一前馈网络(FFN)重构为多个专家网络,仅激活部分参数子集,实现计算效率与模型容量的平衡。本文将从核心原理、技术差异、应用场景及最新发展四个维度,系统对比这两种架构的演进路径与实践价值。
二、核心原理:从密集计算到稀疏激活
(一)Transformer架构的全局建模
Transformer采用编码器-解码器结构,其核心创新在于自注意力机制。通过计算输入序列中每个token与其他token的关联权重,模型能够并行处理长距离依赖关系,避免传统循环神经网络(RNN)的序列化计算瓶颈。例如,在机器翻译任务中,编码器通过多头注意力层捕捉源语言句子的语义关联,解码器则利用跨注意力机制将目标语言生成与源语言对齐。这种设计使Transformer在保持高精度的同时,显著提升训练效率。
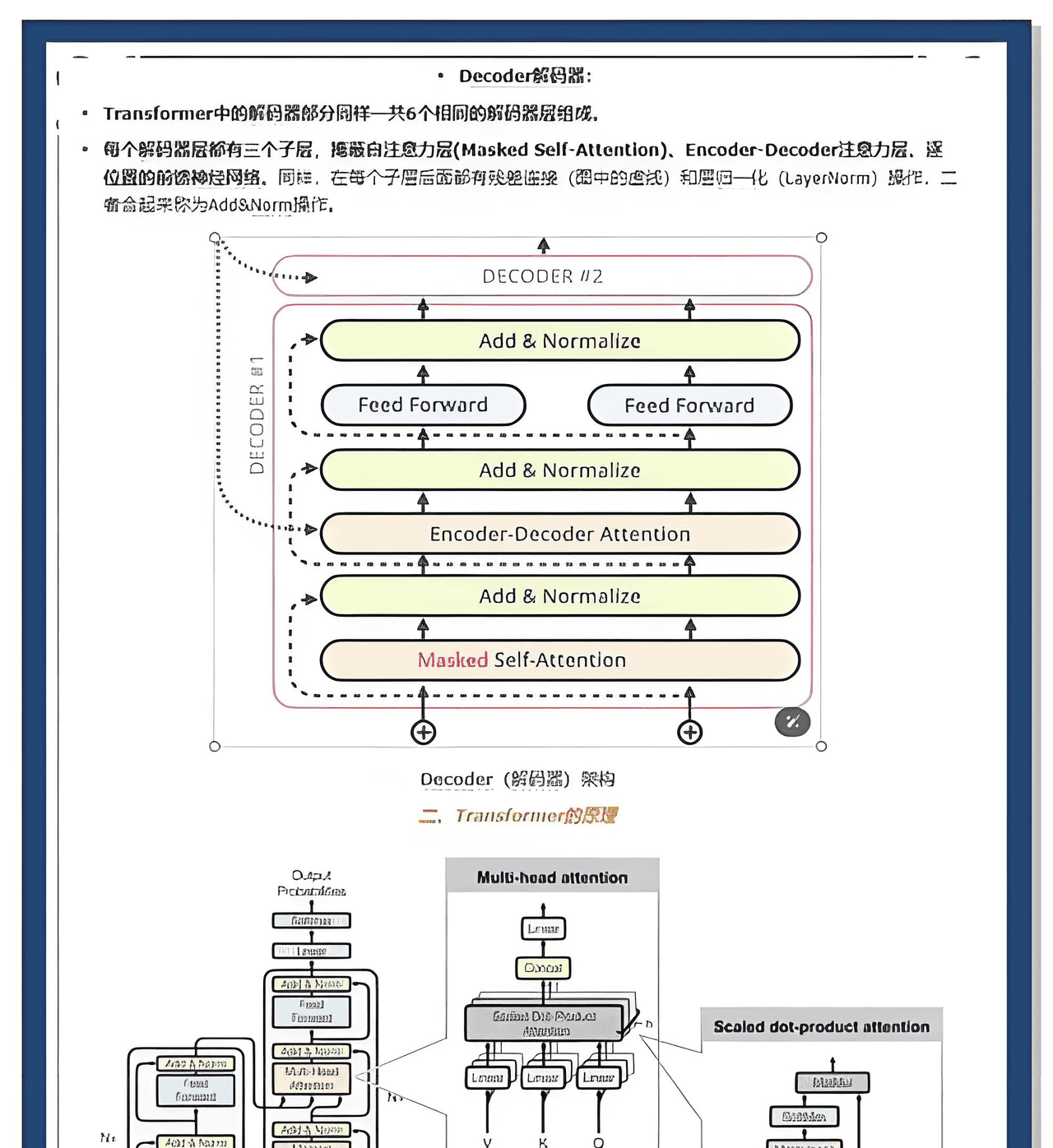
(二)MoE架构的条件计算
MoE通过稀疏激活机制突破Transformer的密集计算限制。其核心组件包括:
专家网络:每个专家为独立的FFN,负责处理特定类型的输入特征(如语法结构或语义主题)。
路由机制:门控网络根据输入动态选择专家,仅激活相关子集。例如,在文本分类任务中,路由器可能将“科技类”文本分配给擅长技术术语的专家,而“文学类”文本则由文化背景专家处理。
负载均衡:通过损失函数约束专家使用频率,避免“偏科”现象(如某些专家过度激活)。
MoE的稀疏性使其在扩展模型规模时,计算成本仅线性增长而非平方增长,为万亿参数模型提供可行性。
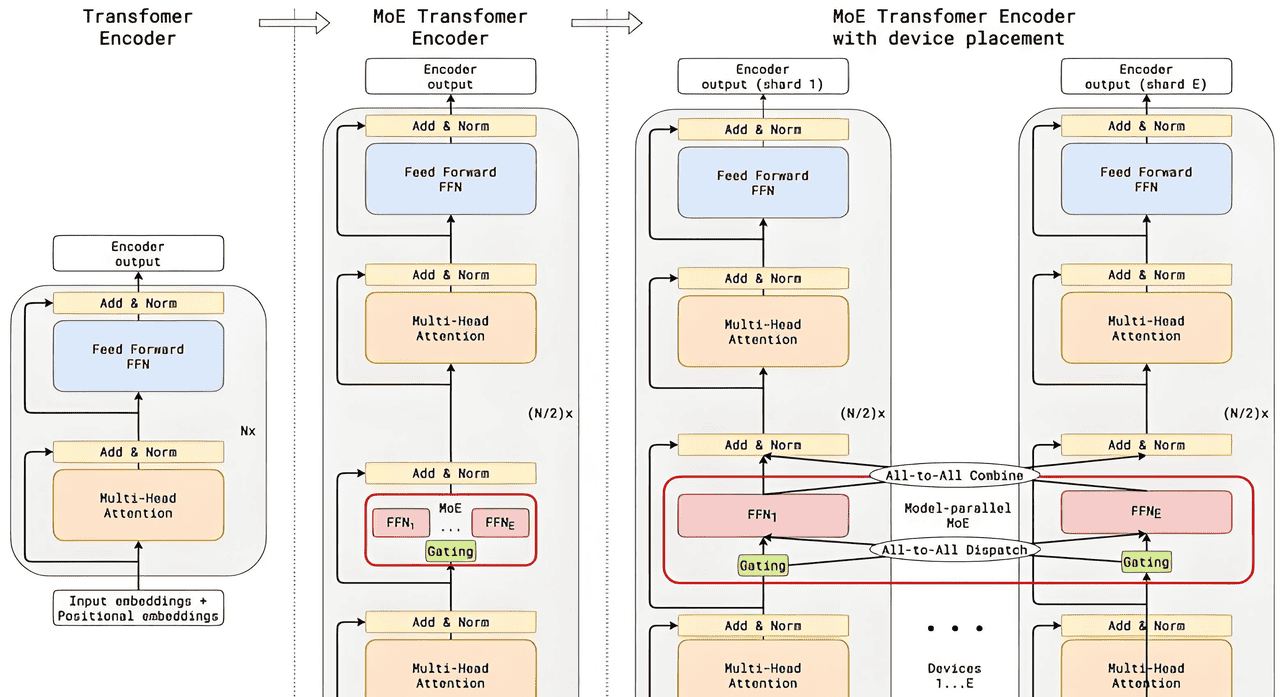
三、技术差异:效率与扩展性的博弈
维度
Transformer
MoE
计算模式
密集计算(所有参数参与推理)
稀疏计算(仅激活2-4个专家)
参数效率
参数量固定,扩展性受限
专家数量可动态扩展(如64个专家)
训练复杂度
优化稳定,易收敛
需设计负载均衡损失函数
推理速度
延迟较高(O(n²)复杂度)
通过稀疏激活提升效率(如GShard模型)
(一)计算效率的对比
Transformer的自注意力机制在长序列处理中面临计算复杂度激增的问题。例如,处理10个token的序列时,注意力矩阵的计算量达10次浮点运算。而MoE通过专家路由,将计算量压缩至仅激活部分专家。在DeepSeek-v3等模型中,万亿参数规模下推理延迟降低40%以上。
(二)扩展性的差异
MoE的专家网络设计支持模型规模的灵活扩展。例如,Google的Switch Transformer通过动态路由,将模型容量提升至万亿级,同时保持推理成本可控。相比之下,传统Transformer的扩展需依赖硬件升级(如GPU集群),成本呈指数增长。
四、应用场景:通用任务与专业需求的平衡
(一)Transformer的适用领域
通用NLP任务:如文本生成、问答系统,其全局建模能力可处理多样化输入。
边缘计算:轻量化变体(如TinyBERT)适合手机等设备,实现本地化部署。
(二)MoE的突破性应用
超大规模模型:如Grok-1通过MoE架构实现千亿参数训练,在多模态任务中超越传统模型。
企业级知识管理:结合检索增强生成(RAG)技术,MoE可动态调用专家库,优化文档摘要与决策支持。
边缘-云协同:在智能家居场景中,MoE模型通过边云协作框架,实现低延迟推理与隐私保护。
五、最新发展:MoE的演进与挑战
(一)技术优化方向
超稀疏MoE:如Google的Pathways-2架构,通过200万亿参数动态路由,稀疏激活比例低于5%。
混合架构:腾讯混元T1结合Transformer与Mamba,提升长序列处理效率。
非Transformer探索:如MiniMax-01借鉴生物神经网络特性,在工业验证中展现潜力。
(二)核心挑战
专家负载均衡:需通过损失函数约束专家使用频率,避免“偏科”。
路由机制优化:动态选择专家需平衡计算开销与模型精度。
端侧部署适配:MoE的稀疏性需与硬件加速器(如TPU)深度集成。
六、结论:架构演进的未来图景
Transformer与MoE的对比,本质是效率与扩展性的权衡。前者以稳定性和通用性见长,后者通过稀疏激活突破规模瓶颈。随着AI向具身智能与边缘计算延伸,MoE架构将成为万亿参数模型的核心技术。未来,混合专家模型可能进一步融合递归计算(如MoR架构)或类脑设计,推动AI从“被动响应”向“主动决策”跃迁。这场架构革命不仅重塑技术边界,更催生了对算法工程师、边缘计算专家的迫切需求,为AI产业注入新动能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...