
(CVPR2024)DemosaicFormer:用于HybridEVS相机的粗到细去马赛克网络

原文链接:paper
混合基于事件的视觉传感器(HybridEVS)是一种新型传感器,集成了传统的基于帧和基于事件的传感器,为需要低光照、高动态范围和低延迟环境的应用提供了巨大的优势,例如智能手机和可穿戴设备。
尽管它有潜力,但缺乏专门为HybridEVS设计的图像信号处理(ISP)管道构成了一个重大挑战。为了解决这个挑战,在这项研究中,提出了一种由粗到精的去马赛克框架DemosaicFormer,它包括粗去马赛克和像素校正两部分,粗去马赛克网络用于产生初步的高分辨率图像,像素校正网络增强了图像恢复的性能,减轻了缺陷像素的影响。我们的关键创新是多尺度选通模块(MSGM)的设计。应用跨尺度特征的集成,这允许特征信息在不同尺度之间流动。
实验结果表明,与现有方法相比,该方法在定性和视觉上都具有上级性能,并且在MIPI 2024 Hybridevs Camera Democracy挑战赛中,该方法在所有评价指标上都达到了最佳性能。
代码可以在此存储库中找到。
Introduction
基于事件的视觉传感器(Event-Based Vision Sensor,EVS)异步检测亮度变化并立即输出事件数据,具有低功耗、高灵敏度的优点,适合捕捉高动态范围的视觉信息而不产生模糊,但无法捕捉颜色信息极大地限制了事件摄像机的应用范围。
混合基于事件的视觉传感器(HybridEVS)[11]是一种新颖的混合传感器由传统的基于帧的传感器和基于事件的传感器结合而成。它结合了这些传感器的优点,提供高时间分辨率、低延迟和出色的动态范围,同时仍然以更高的信噪比(SNR)捕获颜色信息。与传统传感器相比,HybridEVS由于其混合设计,在更广泛的应用中表现得更好。四拜耳模式,如图1(a)所示,是智能手机摄像头中广泛采用的一种常见模式,因为它能够通过对2 × 2邻域内的四个像素进行平均来获得低光照下的高质量图像。虽然在合并模式下信噪比(SNR)得到了改善,但空间分辨率作为折衷而降低。缺陷像素是由传感器的制造工艺造成的缺陷,在光电转换过程中某些像素值不准确。
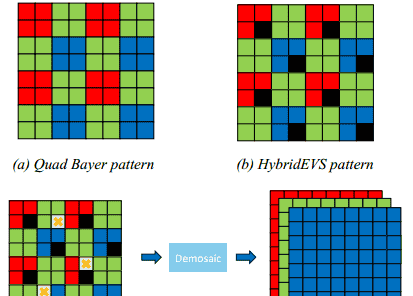
图1.两种不同模式和去马赛克任务的图示。(a)四拜耳模式。(B)HybridEVS模式。(c)HybridEVS相机任务的去马赛克是指将HybridEVS模式原始数据转换为RGB图像。
如图1(B)所示,HybridEVS模式基于四拜耳模式,其用事件像素(由黑色像素表示)替换4 × 4模式中的两个正常像素。
然而,传统的通用方法面临挑战,在对HybridEVS原始数据进行去马赛克时,会发生错误。由于四拜耳模式牺牲了空间分辨率,并且事件像素无法记录颜色信息,因此与常规原始数据的去马赛克相比,HybridEVS原始数据的去马赛克具有更少的空间和颜色信息。另一方面,与任何传感器一样,可能会出现缺陷像素。因此,使用HybridEVS模式,识别和纠正这些像素更具挑战性。
为了解决这个问题,我们提出了一个由粗到细的框架,名为DemosaicFormer,它包括一个粗略的去马赛克网络和像素校正网络。
对于粗去马赛克阶段,为了从HybridEVS原始数据产生RGB图像的初步高质量估计,
我们引入了递归残差组(RRG)[28],其采用多个双注意块(DAB)来逐步细化特征表示。对于像素校正阶段,旨在提高图像恢复的性能并减轻缺陷像素的影响,本文介绍了由多Dconv头转置注意力(MDTA)和门控Dconv前馈网络(GDFN)组成的Transformer模块,提出了一种新的多尺度门控模块(MSGM),该模块集成了跨尺度特征,允许特征信息在不同尺度之间流动。
贡献:
本文提出了一种新的由粗到精的去马赛克框架(DemosaicFormer),用于对含有缺陷像素的HybridEVS原始图像进行去马赛克,该框架将任务分解为两个子任务:粗去马赛克和像素校正我们设计了多尺度选通模块(MSGM),通过改善不同尺度之间特征信息流的交互来增强网络。实验结果表明,该方法的性能明显优于其他已有的方法,在MIPI-challenge 2024 Democracy for HybridEVS Camera track中,该方法在所有评价分数(PSNR,SSIM)中均获得第一名,并大幅优于其他方法。
2.Related Work
2.1. Image Signal Processing Pipeline
图像信号处理(ISP)流水线是数字图像处理中的一系列处理步骤,用于将从相机或其他图像采集设备获得的原始图像转换为最终可用的图像。
该流水线通常由多个阶段组成,每个阶段执行特定的图像处理任务,以改善图像质量,增强特定的图像特征,或为后续的处理或显示做好准备。ISP包括一系列处理原始图像以获得RGB图像的处理算法,如去噪,去噪,伽马校正等。随着深度神经网络(DNN)的发展,许多研究[9,13,16]使用DNN直接取代ISP的主要处理流程,并将原始图像端到端转换为RGB图像。,CycleISP [28]使用循环方法构建真实的场景的噪声数据集,在正向(RGB2RAW)和反向(RAW2RGB)方向上对相机成像管道进行建模。
[9] Andrey Ignatov, Luc Van Gool, and Radu Timofte. Replacing mobile camera isp with a single deep learning model. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 536–537, 2020. 2, 3
[13] Zhetong Liang, Jianrui Cai, Zisheng Cao, and Lei Zhang. Cameranet: A two-stage framework for effective camera isp learning. IEEE Transactions on Image Processing, 30:22482262, 2021. 2, 3, 5, 6
[16] Eli Schwartz, Raja Giryes, and Alex M Bronstein. Deepisp: Toward learning an end-to-end image processing pipeline. IEEE Transactions on Image Processing, 28(2):912–923, 2018. 2, 3
2.2.图像恢复的深度学习图像恢复旨在从退化图像中恢复其干净的对应物。
一种流行的方案是使用CNN结构来学习有效的模型以捕获图像的局部特征并学习可推广的图像先验。CNN已广泛用于各种图像恢复任务,包括图像去噪[3,26],去马赛克[14,31]和超分辨率[19,31]。Chen等人[2]使用乘法来替换或删除不必要的激活函数,如Sigmoid,ReLU,GELU和Softmax,Zhu等人[36]提出了ECFNet,以多尺度图像作为输入,有效地恢复UDC图像。MIRNet [27]是一种新颖的架构,它学习了一组丰富的功能,并从多个尺度结合上下文信息,同时保持高分辨率。
在Transformer模型在自然语言处理领域大放异彩之后,Vision Transformer(ViT)[5]也在高级视觉任务中得到了广泛的探索,如对象检测[1,35],图像分割[24,33]等。Transformer具有捕获图像块之间的长距离依赖关系并适应给定输入内容的能力。由于这些特性,Transformer也用于图像恢复领域[12,21,34]。ShuffleFormer [23]提出了一种基于随机混洗策略的局部窗口Transformer,以模拟具有线性复杂度的非局部交互。Restormer [29]提出了一种基于高效Transformer的模型
2.3. HybridEVS Visions
基于事件的视觉传感器相机具有低功耗和高灵敏度的优点,并且适合于捕获高动态范围的视觉信息而不模糊。已经有相关的工作使用具有RGB和事件数据的深度神经网络(DNN)来进行有效的图像增强(例如去模糊和视频帧插值)[10,17]。
但是这些图像处理技术需要与高级移动的RGB传感器等效的RGB特性,以及传感器上RGB和事件像素之间的焦点对准。基于此,Kodama等人[11]提出了混合基于事件的视觉传感器,它可以在移动的应用处理器中实现混合数据的图像增强。然而,传感器的制造过程会产生缺陷,光电转换过程中也会出现一些像素值不准确,导致缺陷像素的出现,目前将包含事件像素和缺陷像素的HybridEVS原始数据重建成RGB图像的探索较少。。
3. Method
我们提出的DemosaicFormer采用两阶段级联框架构建,该框架以由粗到精的方式逐渐为Hybridevs相机生成所需的高质量结果。
如图2所示,所提出的框架由粗去马赛克和像素校正网络组成,分别基于CycleISP [28]和Restormer [29]。与这些方法不同,我们的两阶段框架可以将复杂的任务分解成单个的子任务,这可以提高每个网络的学习能力,使整个框架更容易收敛。此外,我们设计了多尺度选通模块(MSGM)来在交叉尺度的Transformer块之间传递特征信息流。接着,我们对我们的管道和拟议方法中包含的关键组件进行了详细解释。
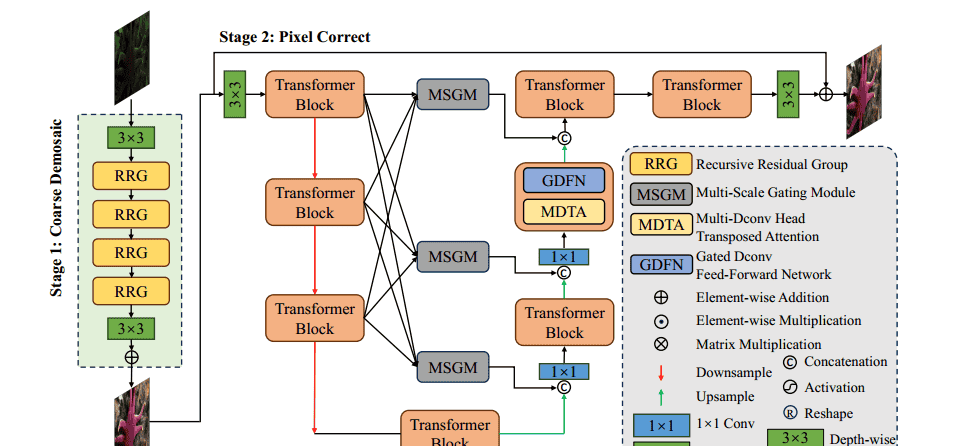
3.1. Overall Pipeline
在一些学习ISP方法[9,13,16]中,由于它们之间的相关性,缺陷像素去除和去马赛克通常在一个阶段中实现。因此,我们首先将原始原始图像送入粗去马赛克网络以获得在RGB空间中的一个不完美的图像。然后,RGB图像将通过像素校正网络,以粗略到精细的方式逐渐恢复损坏的RGB图像。第二阶段最终输出所需的高质量RGB图像
在粗去马赛克阶段,给定一幅Iraw ∈ RH ×W×1的HybridEVS原始图像,将其扩展到RGB空间IRGB raw ∈ RH ×W×3,利用Fcd粗去马赛克网络简单地去除缺陷像素,将原始图像恢复到RGB空间IRGB rest。
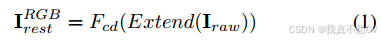
在此基础上,将RGB残差作为像素校正级的输入,采用像素校正网络Fpc对像素进行校正,并对不完美图像进行细化。
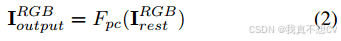
最后得到所需图像I RGB输出∈ R H×W×3。
整个两阶段框架可表述为:
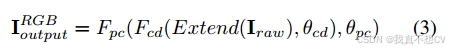
这里θcd,θpc表示Fcd和Fpc中的可学习参数。通过分解复杂的演示任务,我们的DomisaicFormer取得了出色的效果
3.2.粗去马赛克网络
粗去马赛克网络旨在从原始数据中产生RGB图像的初步高质量估计。受[6,15,30]的启发,我们引入了递归残差组(RRG)[28],它采用多个双注意块(DAB)来逐步细化特征表示。如图3所示,
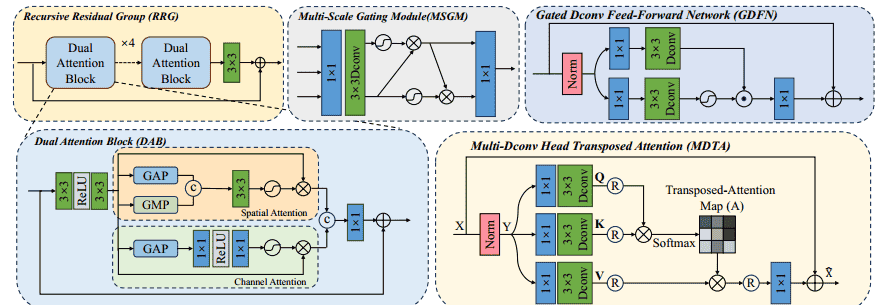
DAB是RRG中的一个综合注意单元,它利用空间[22]和通道[8]注意机制。DAB的整个过程是:

其中U ∈ RH ×W×C表示通过在输入张量Tin ∈ RH ×W×C上应用两个3 × 3 conv层而获得的特征映射张量,Conv(·)是最后一个1 × 1 conv层
3.3.像素校正网络
由于第一阶段不能完美地处理联合去噪和缺陷像素去除任务,因此粗去噪阶段的输出仍然受到缺陷像素的影响。像素校正网络旨在提高图像恢复的性能并减轻缺陷像素的影响。现有的基于CNN的图像恢复方法已经取得了令人印象深刻的结果[2,4,27,36]。然而,这些方法在捕获长范围依赖和非局部相似性方面存在不足,相比之下,Transformer方法在过去几年中表现出了卓越的能力,具有很好的性能,但是,直接应用传统的Transformer具有来自自注意层的更多计算开销。
此外,常规的Transformer架构总是忽略跨尺度特征的集成,这对于有效的图像恢复至关重要。为了解决这个问题,受[29]的启发,我们引入了Transformer块,该块由多Dconv头转置注意力(MDTA)、门控Dconv前馈网络(GDFN)和多尺度门控模块(MSGM)组成。
图3所示的多Dconv头转置注意力(MDTA)具有线性复杂度,通过在通道维度上应用常规SA [18]来实现,这是MDTA的关键设计。作为MDTA的另一个重要组成部分,深度卷积在计算注意力之前生成强调局部上下文的全局注意力地图。
图3所示的Gated-Dconv前馈网络(GDFN)用于在MDTA之后转换特征,这与常规前馈网络(FN)不同[5]。为了改善表示学习,GDFN中应用了门控机制和深度卷积。门控机制被构造为由线性变换层组成的两个并行路径的Hadamard乘积(逐元素乘法)。
与MDTA类似,所有路径都包括3 × 3深度卷积,以编码空间相邻像素位置的信息,用于学习局部图像结构以进行有效恢复。其中一条路径由高斯误差线性单元(GELU)激活[7]。
多尺度选通模块(MSGM)受ResNet的启发,有些方法通过跳过连接将编码器中的原始特征补充到解码器中。这可以降低网络优化的难度,提高网络性能。在某些情况下,特征甚至跨尺度传输,将特征从编码器馈送到解码器的不同尺度。本文受NAFNet [2]的启发,我们还在跨尺度特征融合中引入了一种简单的选通机制,增加了融合的非线性,基于该选通机制,我们可以提取不同尺度解码器所需的特征,提高了网络的校正效果,具体如图3所示,我们的多尺度选通模块(MCGM)根据模块输出的所需形状以不同尺度对特征进行上采样或下采样,然后在通道维度上将它们连接起来,并使用1×1卷积调整通道数量。受NAFNet中简单门的启发,我们将它们分成两个相等的部分进行3×3深度卷积。每个特征乘以另一个特征的S形变化,最后使用1×1卷积将两部分特征转换为所需的增强特征。形式上,最浅尺度下的MCGM可以表示为
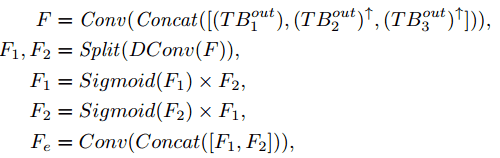
其中,T Bout i,i = 1,2,3表示第n个缩放Transformer块的输出,↑表示上采样操作,Concat(·)表示沿信道维度沿着的级联操作,Dconv(·)表示沿深度方向的级联操作卷积,Split(·)表示块操作。
3.4. DemosaicFormer联合培训
考虑到粗去马赛克和像素校正的内在相互依赖性,将它们完全分解为单独的子任务是不切实际的。因此,在我们的DemosaicFormer中,我们采用了一种联合训练方法,将在第4.4节中讨论。我们利用了在许多图像恢复和增强任务中广泛使用的101损失[2,13,27-29,联合优化的损失函数为:
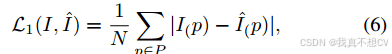
其中p是像素的索引,P是补丁; I和I分别表示我们的DemosaicFormer使用N个像素的地面实况和恢复结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





