
CUDA Cores 和 Tensor Cores 是 NVIDIA GPU 内的专用单元;前者专为各种通用 GPU 任务而设计,而后者经过专门优化,可通过高效的矩阵运算加速 AI 和深度学习

介绍
在快速发展的现代工程领域,图形处理单元 (GPU) 计算正在彻底改变各个领域的计算能力。这一转变的核心是 NVIDIA GPU 的两个关键组件:Tensor 核心 / Tensor 处理单元 (TPU) 和 CUDA 核心。这些专用处理单元与传统 CPU 核心有着根本的不同,已成为工程师解决人工智能、机器学习、科学模拟和高性能计算中复杂问题的不可或缺的工具。
随着对计算能力的需求不断增长,了解 Tensor Core 和 CUDA Core 对于寻求优化性能并突破各自领域可能性界限的工程师来说至关重大。这两种核心之间的区别常常引起专业人士的疑问,我们将在下一节中解答有关它们关系的常见问题。通过深入研究这些 GPU 强劲功能的复杂性,工程师可以充分发挥它们的潜力并推动各自领域的创新。
CUDA 核心与 Tensor 核心:消除混淆
CUDA 核心和 Tensor 核心并不一样。虽然两者都是 NVIDIA 显卡的组成部分,但它们的用途不同,并且专为不同类型的计算任务而设计。
CUDA(统一计算设备架构)核心由 NVIDIA 于 2007 年开发,是其 GPU 的基本处理单元。它们是多功能通用核心,能够处理各种并行计算任务。CUDA 核心擅长顺序处理,是传统图形渲染、物理模拟和通用 GPU 计算的主力。
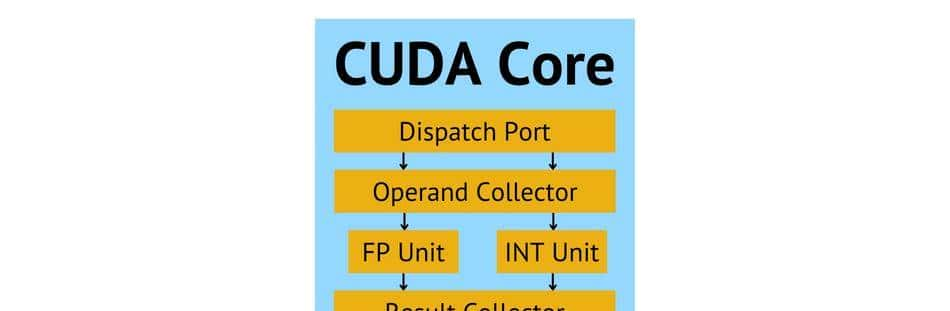
CUDA 核心的框图
Tensor Core 是 NVIDIA Volta 架构于 2017 年引入的专用处理单元,并在后续几代中得到进一步完善。这些核心专门用于加速深度学习和 AI 工作负载,特别是在神经网络计算中普遍存在的矩阵乘法和卷积运算。
CUDA 核心和 Tensor 核心之间的主要区别:
|
方面 |
CUDA 核心 |
Tensor 核心 |
|
目的 |
通用并行计算 |
专注于AI与深度学习加速 |
|
引入 |
2007 |
2017 年推出 NVIDIA Volta 架构 |
|
精度 |
主要为 FP32 和 FP64 |
混合精度(FP16、FP32、INT8、INT4) |
|
工作量 |
广泛的 GPU 计算任务 |
针对矩阵乘法和卷积运算进行了优化 |
|
编程模型 |
CUDA 编程模型 |
可通过高级 AI 框架和 CUDA 访问 |
|
架构 |
基于单指令多线程 (SIMT) 模型 |
围绕矩阵乘法累加引擎设计 |
|
典型应用 |
传统图形渲染、物理模拟 |
深度学习训练和推理,大型神经网络 |
|
性能 |
通用 GPU 计算的高性能 |
矩阵运算的吞吐量极高 |
虽然 CUDA 核心为 NVIDIA 的 GPU 计算能力提供了基础,但 Tensor 核心为特定的 AI 和深度学习任务提供了显著的性能提升。现代 NVIDIA GPU 中这两种核心类型的组合可以高效处理各种工作负载,从传统的图形渲染到尖端的 AI 应用程序。
了解 CUDA 核心和 Tensor 核心之间的区别对于开发人员和工程师优化其应用程序并充分利用 NVIDIA GPU 的潜力至关重大。通过利用适合特定任务的核心类型和 API,开发人员可以在其计算工作流程中实现显着的性能改善和能源效率。
GPU 加速的构建模块
解码 CUDA 核心:多功能主力
CUDA 核心是 NVIDIA GPU 的基本处理单元。这些核心旨在高效执行并行计算,是 GPU 加速的支柱。每个 CUDA 核心本质上都是一个小型可编程处理器,能够执行浮点和整数运算。
CUDA 核心的架构基于单指令多线程 (SIMT) 模型。此设计允许多个线程同时对不同数据执行同一条指令,从而实现大规模并行。CUDA 核心被组织成流式多处理器 (SM),这些处理器共享缓存和内存等资源,从而进一步提高计算效率。
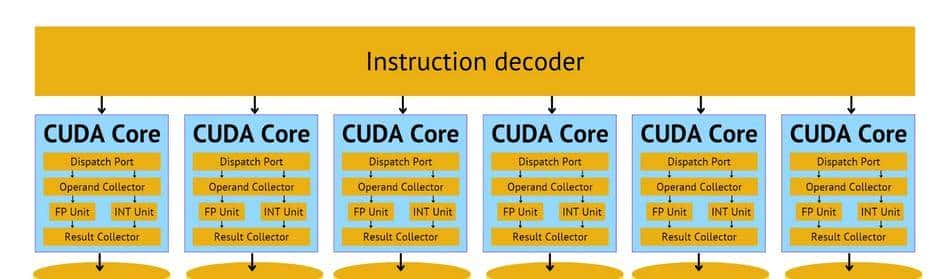
SIMT 模型的框图,其中所有核心都执行一样的指令,并且每个核心都有自己的一组寄存器
在并行处理和通用 GPU 计算方面,CUDA 核心擅长处理各种工作负载。它们可以同时处理数千个线程,超级适合可分解为较小独立计算的任务。这种并行处理能力对于科学模拟、计算机视觉和数据分析中的应用尤其有益。
使 CUDA Cores 能够高效执行各种任务的关键特性包括:
- 灵活的精度支持,允许 FP32(单精度)和 FP64(双精度)计算
- 先进的调度和负载平衡机制
- 硬件加速原子操作,实现高效并行算法
- 支持复杂分支和流程控制
CUDA Cores 的主要功能包括:
- 并行执行算术和逻辑运算
- 高效的内存访问和管理
- 支持各种数据类型和精度级别
- 执行复杂的算法和控制结构
- 与图形渲染管道无缝集成
- 跨多领域通用计算任务加速
如上一节所述,CUDA Cores 在多功能性和通用性方面与 Tensor Cores 不同。虽然 Tensor Cores 专门用于 AI 和深度学习的矩阵运算,但 CUDA Cores 可以处理更广泛的计算任务,从而巩固了其作为 NVIDIA GPU 多功能主力的独特作用。这种灵活性使 CUDA Cores 能够适应各种计算挑战,从传统的图形渲染到复杂的科学模拟。
Tensor Cores:专为 AI 和高性能计算 (HPC) 而精心设计
Tensor Core 代表了 GPU 架构的革命性进步,专为加速深度学习和高性能计算 (HPC) 工作负载而设计。这些专用处理单元具有独特的矩阵乘法累加引擎,可对小矩阵进行操作,一般为 4×4(用于 FP16 输入)和 FP32 累加。
Tensor Core 的主要功能是大幅加速矩阵乘法和卷积运算,这些运算是许多深度学习算法的基础。通过在单个时钟周期内执行这些运算,Tensor Core 可实现比传统 CUDA 核心更高的吞吐量。这种加速对于训练和推理大型神经网络至关重大,由于这些神经网络需要重复执行数百万次此类运算。
在深度学习和科学计算中,Tensor Core 在缩短训练时间和实现更复杂的模型方面发挥着关键作用。它们在图像和语音识别、自然语言处理和自主系统等应用中表现出色。在 HPC 中,Tensor Core 可加速气候建模、分子动力学和金融风险分析等领域的模拟。
不同 NVIDIA GPU 代系中 Tensor Core 的演变带来了性能和功能的显著提升:
|
代数 |
架构 |
主要特点 |
性能改善 |
|
第一代 |
Volta |
FP16 和 FP32 支持 |
基线 |
|
第二代 |
Turing |
INT8 和 INT4 支持 |
与 Volta 相比,FP16 性能提高了 2 倍 |
|
第三代 |
Ampere |
TF32 格式,稀疏矩阵支持 |
与 Volta 相比,FP16 性能提高了 5 倍 |
|
第四代 |
Hopper |
FP8 支持,Transformer Engine |
与 Ampere 相比,FP16 性能提高了 6 倍 |
与 CUDA Core 不同,Tensor Core 是针对特定数学运算进行优化的高度专业化单元。虽然 CUDA Core 为各种并行计算任务提供了灵活性,但 Tensor Core 为 AI 和 HPC 工作负载中常见的矩阵运算提供了无与伦比的性能。这种专业化使 Tensor Core 能够为这些特定操作实现更高数量级的吞吐量,使其成为尖端 AI 研究和开发不可或缺的一部分。
Tensor Core 的引入不仅加速了现有 AI 应用的发展,还推动了之前计算上无法实现的更复杂模型和技术的开发。随着 AI 和 HPC 的不断发展,Tensor Core 在突破这些领域的可能性方面发挥的作用变得越来越重大。
架构对决:Tensor Cores 与 CUDA Cores
设计理念和计算方法
Tensor Core 和 CUDA Core 的架构设计反映了它们在现代 GPU 计算中的独特作用。CUDA Core 体现了以多功能性和通用计算为中心的设计理念。同时,Tensor Core 代表了一种针对 AI 和 HPC 工作负载所必需的特定数学运算进行优化的专门方法。
CUDA 核心基于单指令多线程 (SIMT) 模型构建,允许它们同时对多个数据点执行同一条指令。这种设计可实现各种计算任务的高效并行处理。CUDA 核心的架构包括:
- 用于整数和浮点运算的算术逻辑单元 (ALU)
- 用于复杂数学函数的特殊功能单元 (SFU)
- 用于内存操作的加载/存储单元
- 注册文件以实现快速数据访问
相比之下,Tensor Core 的核心设计为矩阵乘法累加引擎。这种专门的架构使它们能够以极高的效率执行矩阵运算。Tensor Core 的关键组件包括:
- 用于快速矩阵计算的矩阵乘法单元 (MMU)
- 用于准确求和运算的累积单元
- 用于处理各种精度级别的数据格式化单元
CUDA Cores 的指令集更加多样化,支持各种操作,包括算术、逻辑和控制流指令。这使 CUDA Cores 能够处理复杂的算法和各种工作负载。CUDA Cores 的执行模型包括:
- 基于 Warp 的执行(每个 Warp 32 个线程): CUDA Core 使用所谓的“基于 Warp 的执行”。在这种情况下,Warp 是 CUDA Core 同时执行的一组 32 个线程。这种分组方法允许高度并行处理,由于 32 个线程中的多个操作可以同时执行。这对于可以并行化的操作尤其有效,可提高涉及大型数据集或重复计算的任务的处理速度。
- 动态调度 Warp: CUDA Core 根据可用性和工作负载需求动态地将 Warp 调度到不同的流式多处理器。动态调度有助于优化 GPU 资源的利用率,确保所有多处理器尽可能保持繁忙。这种自适应调度还可以减轻某些线程中操作较慢导致的延迟的影响,由于其他 Warp 可以在这些线程等待时进行处理。
- 分支分歧处理: 当同一 Warp 的不同线程需要执行不同的指令时,就会发生分支分歧,这一般是由于代码中的条件分支(如 if 语句)造成的。发生这种情况时,CUDA 架构可以有效地处理分歧。它通过执行 Warp 中任何线程所需的每个分支路径来实现这一点,但只有需要执行该特定分支的线程才会处于活动状态,而其他线程则处于空闲状态。这确保覆盖所有可能的路径,而不会强制所有线程执行所有路径,从而巧妙地管理分歧并减少不必要的计算。
不过,Tensor Core 具有更聚焦的指令集,主要以矩阵运算为中心。它们的执行模型针对以下方面进行了优化:
- 快速矩阵乘法和累加: Tensor Core 经过专门设计,可执行超级快速的矩阵乘法和累加运算,这对许多 AI 算法(尤其是神经网络)至关重大。每个 Tensor Core 都可以执行 A * B + C 之类的运算,其中 A、B 和 C 是矩阵。这种只需一步即可执行复杂矩阵运算的能力大大加快了深度学习模型中的训练和推理过程。
- 混合精度运算: 混合精度是指在计算过程中使用不同的数值精度。Tensor Core 旨在支持混合精度计算,这使得它们能够以较低的精度(如 FP16)进行矩阵乘法运算,同时使用较高精度(如 FP32)进行累加。这种方法在保持结果必要的数值精度的同时,还保持了较高的计算吞吐量和能效。混合精度在加快深度学习计算速度和减少训练期间的内存占用方面特别有益。
- 矩阵运算之间的高效数据移动: 高效的数据移动对于高性能计算至关重大,可以避免与硬件不同部分之间的数据传输相关的瓶颈。Tensor Cores 优化了操作之间的数据移动,减少了移动数据所花费的时间和精力。这是通过复杂的内存层次设计和将 Tensor Cores 连接到 GPU 内存和缓存的直接数据路径实现的。因此,可以快速获取连续操作所需的数据,从而提高 GPU 的整体效率。
这些核心类型的不同作用在其设计和计算方法中显而易见。CUDA 核心提供通用 GPU 计算所需的灵活性和广泛适用性,可处理从图形渲染到科学模拟的各种任务。Tensor 核心凭借其专门的架构,为主导 AI 和 HPC 工作负载的特定矩阵运算提供前所未有的性能,从而实现深度学习和复杂数值模拟的突破。
精度和数据类型:平衡法
在 GPU 计算中,精度和数据类型在确定计算准确性和应用程序的整体性能方面起着至关重大的作用。CUDA Cores 和 Tensor Cores 提供不同的精度功能,可满足广泛的计算需求。
CUDA Core 历来擅长单精度 (FP32) 和双精度 (FP64) 浮点运算,这对于许多需要高精度的科学计算应用至关重大。它们还支持用于通用计算任务的整数运算 (INT32、INT64)。最近的 NVIDIA 架构扩展了 CUDA Core 功能,包括半精度 (FP16) 支持,从而提高了可以容忍较低精度的应用程序的性能。
Tensor Core 主要为 AI 和深度学习工作负载而设计,可提供更多样化的精度选项。它们支持 FP16、FP32,在较新的架构中甚至支持 FP64 操作。此外,Tensor Core 可以使用 INT8 和 INT4 等较低精度格式,这对于深度学习中的推理任务特别有用。最新一代的 Tensor Core 还支持 TensorFloat32 (TF32) 格式,该格式可提供接近 FP32 的精度和类似 FP16 的性能。
混合精度计算是一种在单个工作流程中结合不同精度级别的技术。这种方法允许应用程序尽可能利用低精度操作的速度,同时在必要时保持更高精度计算的准确性。混合精度计算在深度学习中尤其重大,由于训练一般需要更高的精度(FP32 或 FP16)来更新权重。相比之下,推理一般可以以较低的精度(INT8 或 INT4)执行,而不会显着降低准确性。精度和性能之间的权衡取决于应用程序。更高的精度一般提供更高的准确性,但代价是增加计算时间和能耗。例如:
- 科学模拟一般需要 FP64 精度才能在多次迭代中保持准确性,因此尽管性能有所下降,但 CUDA Cores 依旧更适合。
- 深度学习训练一般使用 FP32 或 FP16,受益于 Tensor Cores 针对这些精度的优化性能。
- 人工智能中的推理任务一般可以使用 INT8 甚至 INT4 精度,尽管准确性略有下降,但可以通过 Tensor Core 显著提高性能和能源效率。
- 计算机图形一般使用 FP32 进行大多数计算,并使用 CUDA Cores 平衡视觉质量和性能。
- 金融应用程序可能需要 FP64 进行特定计算以满足监管要求,从而需要使用支持 FP64 的 CUDA Cores 或新一代 Tensor Cores。
精度和核心类型的选择最终取决于应用程序的具体要求,在精度需求与性能和能效需求之间取得平衡。了解这些权衡对于优化各个领域的 GPU 加速应用程序至关重大。
性能指标:数字计算:对 Tensor 核心和 CUDA 核心进行基准测试
对 Tensor Core 和 CUDA Core 进行基准测试,可以深入了解它们在各种计算任务中的性能特征。这些基准测试可协助开发人员和研究人员确定哪种核心类型最适合特定应用程序。
在一系列比较最新一代 NVIDIA GPU 的测试中,Tensor Core 在矩阵乘法和深度学习工作负载方面的表现始终优于 CUDA Core。例如,在使用大规模矩阵乘法任务(10,000 x 10,000 矩阵)的基准测试中,使用混合精度 (FP16) 计算时,Tensor Core 的性能比 CUDA Core 高出 6 倍。
在评估特定的绩效指标时,有必要了解以下术语:
- FLOPS(每秒浮点运算次数)
- 吞吐量:Tensor Cores 在处理大批量数据方面表现出色,在深度学习推理任务中的吞吐量比 CUDA Cores 高出 3 倍。
- 延迟:由于其更通用的设计,CUDA Cores 一般为单个小型计算提供较低的延迟。Tensor Cores 可能会为单个操作引入稍高的延迟,但对于更大的工作负载可以通过显着的更高吞吐量来弥补。
在实际场景中,这些基准测试结果可显著提升特定应用程序的性能:
- 深度学习训练:在 ImageNet 数据集上训练的流行图像分类模型 (ResNet-50) 使用 Tensor Core 进行训练,与单独使用 CUDA Core 相比,速度提高了 3 倍。[1]
- 科学模拟:虽然 CUDA Cores 在双精度 (FP64) 计算中依旧占据主导地位,但具有 TF32 精度的 Tensor Cores 为许多模拟提供了引人注目的替代方案,可提供接近 FP32 的精度并将性能提高 2 倍。
- 计算机视觉:在实时物体检测任务中,Tensor Cores 的性能比 CUDA Cores 提高了 2.5 倍,从而可以在边缘设备中实现更高的帧速率和更复杂的模型。
值得注意的是,这些基准测试代表了最佳条件下的性能。实际性能可能因问题大小、内存带宽利用率和所使用的特定算法等因素而异。此外,Tensor Core 的有效性在很大程度上取决于在应用程序的计算工作流程中利用其专门的矩阵乘法功能的能力。
对于开发人员来说,这些基准测试强调了算法设计和优化技术的重大性,这些技术可以充分利用每种核心类型的优势。虽然 Tensor Cores 为特定操作提供了前所未有的性能,但 CUDA Cores 依旧因其在各种通用计算任务中的灵活性和性能而至关重大。
驾驭力量:应用程序和用例
人工智能与深度学习:Tensor Cores 领域
Tensor Core 为矩阵运算提供了前所未有的计算能力,彻底改变了人工智能和深度学习领域,而矩阵运算是大多数神经网络架构的支柱。这些专用处理单元在人工智能任务中表现出色,由于它们能够在单个时钟周期内执行混合精度矩阵乘法累加运算,从而大大加快了深度学习模型的训练和推理速度。
Tensor Cores 的架构专门针对以下深度学习操作进行了优化:
- 矩阵乘法: 神经网络层中的基本操作,特别是在全连接层中。
- 卷积: 对于图像和视频处理任务中使用的卷积神经网络 (CNN) 至关重大。
- 注意力机制:对于自然语言处理 (NLP) 模型中的 Transformer 架构至关重大。
- 张量收缩:对于高级神经网络架构和科学计算应用超级重大。
这些操作受益于 Tensor Cores 执行快速、低精度计算的能力,同时通过混合精度训练和自动损失缩放等技术保持准确性。
一些流行的 AI 框架和库已经过优化,可以充分利用 Tensor Core :
- TensorFlow:通过 XLA(加速线性代数)编译器和优化的 CUDA 内核利用 Tensor Cores。
- PyTorch:通过 NVIDIA 的 cuDNN 和 cuBLAS 库集成 Tensor Core 加速。
- NVIDIA TensorRT: 用于高性能深度学习推理的 SDK,充分利用 Tensor Cores。
- RAPIDS: 一套开源软件库,用于完全在 GPU 上执行端到端数据科学和分析管道。
- MXNet:通过 TensorCore 算子和自动混合精度 (AMP) 支持 Tensor Cores。
利用 Tensor Core 技术的关键 AI 应用包括:
- 自然语言处理
- 机器翻译系统
- 情绪分析引擎
- 文本摘要工具
- 大型语言模型(例如 GPT、BERT)
- 计算机视觉
- 实时视频流中的物体检测和识别
- 医学成像的图像分割
- 面部识别系统
- 自动驾驶汽车感知系统
- 语音技术
- 虚拟助手的语音识别
- 文本转语音合成
- 语音克隆和音频生成
- 生成式人工智能
- 图像生成模型(例如 DALL-E、稳定扩散)
- 文本到图像合成
- 风格转换算法
- 推荐系统
- 电子商务产品推荐
- 流媒体服务的内容个性化
- 社交媒体信息管理
- 科学和医学人工智能
- 药物发现和分子建模
- 蛋白质结构预测
- 医学图像分析与诊断
- 金融服务
- 高频交易算法
- 欺诈检测系统
- 风险评估模型
这些应用程序中 Tensor Core 的采用显著提高了模型准确性、训练速度和推理性能,从而支持在各个行业开发更复杂、更强劲的 AI 系统。
科学计算和模拟:CUDA 的优势
CUDA 核心已成为科学计算和模拟中不可或缺的一部分,为各种复杂的科学问题提供了前所未有的计算能力。这些多功能处理单元在需要高精度计算、复杂算法实现和高效处理大型数据集的能力的领域表现出色。
CUDA Core 在科学计算中表现突出的关键领域包括:
- 计算流体动力学 (CFD):模拟航空航天、汽车和气候模型中的流体流动。
- 分子动力学:研究生物和材料科学中原子和分子的物理运动。
- 量子化学:对分子系统进行电子结构计算。
- 天体物理学:建模星系演化、引力波分析和宇宙学模拟。
- 金融模型:运行蒙特卡罗模拟进行风险分析和期权定价。
- 地球物理学: 处理地震数据和建模地下结构。
CUDA Cores 在处理各种科学工作负载方面的多功能性源于以下几个因素:
- 精度灵活性: CUDA Cores 支持单精度、双精度和半精度浮点运算,使科学家能够根据需要平衡精度和性能。
- 算法适应性: CUDA Cores 的通用特性使其能够实现特定于各个科学领域的复杂自定义算法。
- 可扩展性: CUDA 的编程模型允许跨多个 GPU 有效扩展计算,从而能够解决日益庞大和复杂的问题。
- 内存层次结构利用率: CUDA 核心可以有效利用不同级别的 GPU 内存,优化对科学计算至关重大的数据访问模式。
严重依赖 CUDA 技术的科学模拟示例包括:
- GROMACS(格罗宁根化学模拟机器):用于模拟蛋白质、脂质和核酸的分子动力学包。
- NAMD(纳米分子动力学):专为大型生物分子系统的高性能模拟而设计。
- ANSYS Fluent:一种用于航空航天、汽车和能源领域的计算流体动力学软件。
- WRF(天气研究与预报): 下一代中尺度数值天气预报系统。
科学领域和对应的 CUDA 加速应用程序表:
|
科学领域 |
CUDA 加速应用程序 |
|
生物信息学 |
BLAST+(基本局部比对搜索工具) |
|
量子化学 |
GAMESS(通用原子和分子电子结构系统) |
|
地球科学 |
SPECFEM3D(3D 谱有限元方法) |
|
粒子物理学 |
GEANT4(几何与追踪) |
|
电磁模拟 |
FDTD 解决方案(时域有限差分) |
|
计算化学 |
LAMMPS(大规模原子/分子大规模并行模拟器) |
|
信号处理 |
cuSignal(GPU加速信号处理) |
|
金融工程 |
QuantLib(量化金融库) |
这些科学应用采用 CUDA Core 后,计算时间大幅缩短,一般可缩短几个数量级。这种加速不仅提高了现有研究的效率,还使科学家能够解决前所未有的规模和复杂性问题,从而突破了跨学科科学发现的界限。
图形和渲染:混合方法
NVIDIA GPU 中的现代图形渲染采用混合方法,利用 Tensor Core 和 CUDA Core 实现前所未有的视觉保真度和性能。专用核心和通用核心之间的这种协同作用彻底改变了实时渲染技术,实现了光线追踪和 AI 增强升级等高级功能。
Tensor Core 主要通过 AI 加速任务促进图形渲染:
- 光线追踪场景中的降噪:光线追踪通过模拟光的物理行为来生成高度逼真的照明。但是,如果采样的光线不足,它可能会产生嘈杂的图像。Tensor Cores 通过使用深度学习算法来预测和填补空白,加速这些图像的降噪过程,从而提高图像清晰度,而不会影响光线追踪提供的细节。
- 深度学习超级采样 (DLSS): DLSS 是一项革命性功能,它使用神经网络分析数千帧并学习如何以最佳方式增强渲染图像的分辨率。通过使用 DLSS,游戏可以以较低的原始分辨率运行,然后智能地升级到更高的分辨率,从而提高帧速率而不会明显降低图像质量。Tensor Core 在这里至关重大,由于它们可以高速执行深度学习模型所需的密集矩阵乘法。
- AI 增强纹理合成:在纹理合成中,AI 模型可以从较小的数据集生成高质量纹理或增强现有纹理。Tensor Core 通过高效处理分析和生成这些纹理的神经网络所需的计算来加速这一过程。
- 时间抗锯齿的运动矢量生成:时间抗锯齿 (TAA) 是一种减少闪烁并使动画场景中的运动更加平滑的技术。由 Tensor Cores 支持的 AI 驱动的 TAA 方法涉及生成预测帧间像素运动的运动矢量。这种预测可以实现更平滑的过渡并减少视觉伪影。
CUDA Cores 功能更加多样,可以处理更广泛的图形任务:
- 传统光栅化:光栅化是将 3D 矢量图形转换为 2D 图像的过程,它涉及多个步骤,包括顶点处理、形状组装和像素输出。CUDA 核心可高效处理像素着色和其他光栅操作,使其成为视频游戏和应用程序中大多数图形渲染过程的基础。
- 几何处理:这涉及处理构成 3D 场景的形状(例如顶点和多边形)的计算。CUDA 核心执行将几何图形转换为不同视角所需的数学运算,并计算照明和其他环境因素对这些对象的影响。
- 像素着色:像素着色器用于为每个像素添加深度、颜色、纹理和更详细的特性。CUDA 核心被广泛用于计算这些着色器,它们定义像素在屏幕上的显示方式,包括模糊、阴影和光折射等效果。
- 粒子效果和布料动态的物理模拟: CUDA 核心擅长处理实时模拟物理现象所需的复杂数学计算。这包括用于烟雾、火焰和爆炸等效果的粒子系统模拟,以及模拟视频游戏和动画中布料真实运动的布料动态。
在光线追踪中,CUDA Core 负责光线生成、遍历和相交测试。然后,Tensor Core 开始对嘈杂的光线追踪图像进行 AI 加速降噪。这种分工允许在复杂场景中进行实时光线追踪。
DLSS 展示了这种混合方法的强劲功能。CUDA Cores 处理初始的低分辨率渲染,而 Tensor Cores 运行 AI 升级模型,可智能地重建高分辨率图像。这种技术可显著提高帧速率,同时保持视觉质量。
在现代图形管道中,工作流程一般遵循以下模式:
- CUDA Cores 执行初始场景设置和几何处理。
- 光栅化由专用的固定功能单元执行。
- CUDA 核心处理像素着色和初始照明计算。
- 如果启用光线追踪,CUDA 核心和光线追踪核心会追踪光线并收集照明信息。
- Tensor Cores 对光线追踪元素进行去噪并应用 AI 增强后处理。
- 对于 DLSS,Tensor Cores 将渲染图像升级到目标分辨率。
- CUDA Cores 应用最终合成和输出处理。
在渲染游戏中的图像时,Nvidia GPU(尤其是 RTX 系列的 GPU)会利用几种类型的内核(CUDA、Tensor 和 RT 内核),每种内核在渲染过程中都发挥着不同的作用。以下是此渲染过程所涉及的步骤的细分:
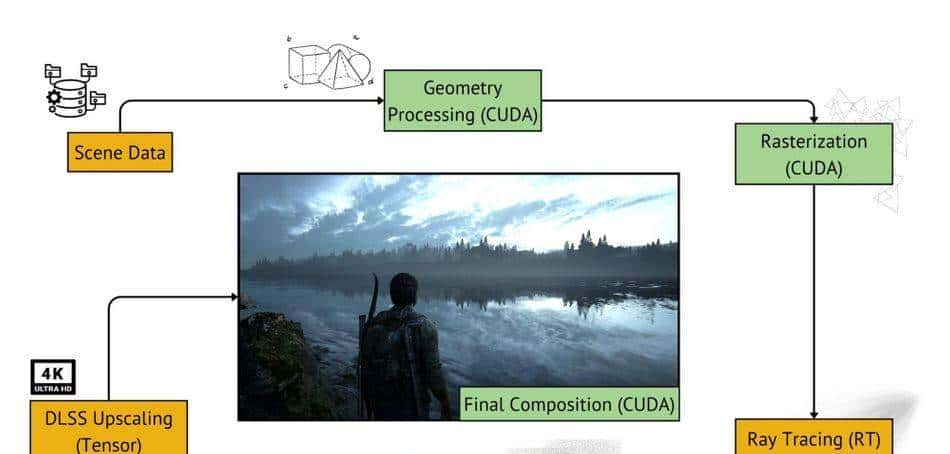
该管道展示了针对特定任务定制的不同 GPU 核心的复杂使用,可最大限度地提高效率和渲染性能
这种方法允许灵活的渲染管道,可以适应不同的图形技术。例如,在路径追踪中,CUDA Cores 可以处理路径生成和相交测试,而 Tensor Cores 可用于重大性采样和最终图像重建。
Tensor Cores 和 CUDA Cores 之间的协作还扩展到其他高级图形技术。在实时全局照明解决方案中,CUDA Cores 可以计算光传播体积,而 Tensor Cores 可以通过学习的光传输模型增强由此产生的间接照明。
RT 核心虽然不是 CUDA 和 Tensor 核心讨论的重点,但它在 Nvidia 的 GPU 中发挥着至关重大的作用,由于它可以加速光线和边界体积相交测试,以实现实时光线追踪。这些专用核心可实现逼真的灯光和阴影,增强游戏中动态、物理准确的环境。它们通过集成的混合渲染技术优化性能和视觉保真度,从而补充 CUDA 和 Tensor 核心。
通过利用所有核心类型的优势,现代 GPU 可以在实时图形渲染中提供前所未有的逼真度和性能。这种混合方法改善了当前的渲染技术,并为以前在计算上不可行、由 AI 增强的新型图形算法开辟了可能性。
挑战与限制:理解权衡
编程复杂性和优化障碍
Tensor Core 和 CUDA Core 的编程和优化面临着不同的挑战,每个挑战都需要专业知识和技术。复杂性源于不仅需要了解硬件架构,还需要了解每种核心类型的特定编程模型和优化策略。
对于 CUDA 核心,主要挑战在于有效地并行化算法以利用大量可用的核心。这一般需要重新思考传统的顺序算法并使其适应并行计算范式。开发人员必须仔细管理内存访问模式、线程同步和负载平衡,以实现最佳性能。
Tensor Core 在为特定操作提供卓越性能的同时,也带来了额外的复杂性。Tensor Core 编程需要深入了解矩阵乘法和卷积运算。开发人员必须构建他们的算法以有效利用这些专用单元,这一般涉及重塑数据和计算以适应 Tensor Core 的首选格式和大小。
每种技术的学习曲线都很陡峭,但重点不同:
- CUDA Core 编程需要掌握并行计算概念、CUDA C/C++ 或其他支持 CUDA 的语言,并了解 GPU 架构。
- Tensor Core 优化涉及线性代数、深度学习框架和混合精度算术技术的深度知识。
有多种工具和框架可用于辅助开发:
- NVIDIA CUDA 工具包: 提供 CUDA 开发的基本工具。
- NVIDIA NSight: 为 CUDA 和 Tensor Core 应用程序提供分析和调试功能。
- TensorRT:优化深度学习模型以便在 Tensor Core 上进行推理。
- PyTorch 和 TensorFlow: 内置支持 Tensor Core 操作的高级框架。
- NVIDIA DALI: 优化数据加载和预处理管道,实现 GPU 加速。
CUDA Cores的常见优化技术:
- 合并内存访问以最大化内存带宽利用率
- 使用共享内存来减少全局内存访问
- 适当的线程块大小以最大化占用率
- 循环展开和指令级并行
- 异步内存传输和基于流的并发
- 尽量减少经纱内的纱线分歧
Tensor Core 的常见优化技术:
- 构建矩阵运算以匹配 Tensor Core 尺寸(例如,FP16 为 16×16)
- 利用混合精度算法实现性能与准确度的最佳平衡
- 使用针对 Tensor Core 优化的专用库(如 cuBLAS 和 cuDNN)
- 在深度学习框架中采用自动混合精度 (AMP)
- 优化 Tensor Core 操作的数据布局和内存访问模式
- 平衡 Tensor Core 与其他 GPU 资源的利用率,以提高整体性能
在利用混合方法的应用程序中同时优化两种核心类型的复杂性又增加了一层挑战。开发人员必须仔细分析他们的应用程序以识别瓶颈并确定哪些操作应定向到每种核心类型以获得最佳整体性能。
硬件限制和兼容性问题
GPU 架构中 Tensor Core 和 CUDA Core 的实现带有特定的硬件限制和兼容性思考,这些会显著影响它们在不同用例中的性能和适用性。
Tensor Core 虽然为特定操作提供了出色的性能,但在精度和灵活性方面却受到限制。早期的 Tensor Core 仅限于 FP16 和 INT8 操作,虽然适用于许多 AI 工作负载,但对于需要更高精度的应用来说可能不够。较新的架构已将其扩展到包括 FP32 甚至 FP64 操作,但代价是增加芯片面积和功耗。
CUDA Core 用途更广泛,灵活性更高,但对于矩阵乘法等特定运算,可能无法达到与 Tensor Core 一样的性能水平。在执行兼容任务时,它们一般比 Tensor Core 每次运算消耗更多电量。
跨 GPU 架构和代际兼容性是另一个挑战。Tensor Core 是随 Volta 架构引入的,并在每一代中都得到了显著发展。这意味着针对一种架构优化的 Tensor Core 代码可能不完全兼容,或者在其他架构上性能不佳。例如,在 Ampere GPU 上利用 Tensor Core 的应用程序可能无法在完全没有 Tensor Core 的 Pascal GPU 上运行,或者性能可能会降低。
CUDA 核心保持了更好的向后兼容性,CUDA 代码一般可在多代 GPU 上运行。但是,较新的 CUDA 功能和优化可能无法在较旧的硬件上使用,这可能会导致性能差异。
在 Tensor Core 和 CUDA Core 之间做出选择会显著影响功耗和热管理。Tensor Core 在用于适当的工作负载时,可以提供比 CUDA Core 更高的每瓦性能。不过,由于它们的专用性质,对于通用计算任务,它们可能会处于闲置状态,这可能会导致混合工作负载中的功耗低下。
在处理高利用率场景时,热管理变得尤为重大。Tensor Cores 的密集计算能力可能导致 GPU 芯片上出现局部热点,需要复杂的冷却解决方案。CUDA Cores 虽然在同等计算量下一般会产生更多热量,但往往会更均匀地将热量分布在芯片上。
不同 GPU 型号的硬件规格比较表:
|
GPU 型号 |
架构 |
CUDA 核心 |
张量核心 |
FP32 性能 |
张量核心性能(FP16) |
热设计压电 |
|
RTX 4090 |
艾达·洛夫莱斯 |
16,384 |
512 |
82.6 TFLOPS |
330 TFLOPS |
450 瓦 |
|
RTX 3090 |
安培 |
10,496 |
328 |
35.6 TFLOPS |
142 TFLOPS |
350 瓦 |
|
RTX 2080 Ti |
图灵 |
4,352 |
544 |
13.4 TFLOPS |
108 TFLOPS |
250 瓦 |
|
特斯拉 V100 |
沃尔特 |
5,120 |
640 |
14.0 TFLOPS |
112 TFLOPS |
300 瓦 |
|
GTX 1080 Ti |
帕斯卡 |
3,584 |
不适用 |
11.3 TFLOPS |
不适用 |
250 瓦 |
|
A100 |
安培 |
6,912 |
432 |
19.5 TFLOPS |
312 TFLOPS |
400 瓦 |
该表说明了 GPU 架构的演变,重点介绍了 Tensor Core 的引入及其为特定工作负载带来的显著性能提升。它还展示了不同模型和代际之间计算能力与功耗之间的权衡。
结论
Tensor Core 和 CUDA Core 代表了两种不同的 GPU 计算方法,每种方法都有各自的优势和应用。Tensor Core 擅长加速对 AI 和深度学习至关重大的大量特定数学运算,为矩阵乘法和卷积提供前所未有的性能。另一方面,CUDA Core 为从图形渲染到科学模拟的各种计算任务提供了多功能性和广泛的适用性。
选择利用 Tensor Core 还是 CUDA Core 会显著影响工程应用的性能和效率,特别是在人工智能、计算机视觉和高性能计算等领域。
在为特定工程任务选择合适的核心类型时,请思考所涉及计算的性质。对于严重依赖矩阵运算或深度学习推理的应用程序,Tensor Cores 可提供卓越的性能。对于更通用的计算或需要高精度的任务,CUDA Cores 依旧是首选解决方案。
再次重申,CUDA 核心和 Tensor 核心并不一样。虽然两者都位于 NVIDIA GPU 上,但它们的用途不同,并且在不同类型的计算中表现出色,反映了 GPU 架构的持续专业化,以满足不同的计算需求。
常见问题
- Tensor Cores 如何在矩阵运算中实现高性能?
Tensor Cores 使用专门的架构,在单个时钟周期内执行矩阵乘法累加运算,利用混合精度算法和优化的数据流,与传统浮点单元相比实现更高的吞吐量。 - CUDA Cores 可以执行与 Tensor Cores 一样的操作吗?
虽然 CUDA Cores 理论上可以执行一样的操作,但它们并未针对 Tensor Cores 擅长的特定矩阵计算进行优化。CUDA Cores 在这些专门任务中提供了更大的灵活性,但性能较低。 - Tensor Cores 的精度与 CUDA Cores 相列如何?
早期的 Tensor Cores 仅限于 FP16 和 INT8 精度,而 CUDA Cores 一般支持 FP32 和 FP64。不过,新一代的 Tensor Cores 已经扩展到支持 FP32 甚至 FP64 操作,从而缩小了这一差距。 - 针对 Tensor Cores 与 CUDA Cores 进行编程时,主要的编程差异是什么?
Tensor Cores 编程一般涉及使用高级深度学习框架或自动利用这些核心的专用库。CUDA Core 编程一般需要使用 CUDA C/C++ 或其他支持 CUDA 的语言进行更多的低级控制和显式并行管理。这些工具适用于所有主要操作系统,包括 Linux、Windows 和 MacOS。 - Tensor Core 和 CUDA Core 如何影响 GPU 的功耗?
Tensor Core 一般可为兼容操作提供更高的每瓦性能。不过,它们的专用性质意味着它们在通用计算期间可能处于闲置状态,与功能更丰富的 CUDA Core 相比,这可能导致混合工作负载中的整体功耗效率较低。 - 我们可以期待 GPU 核心架构的未来发展吗?
未来的 GPU 架构可能会进一步集成专用核心,用于光线追踪、AI 和物理模拟等任务。我们还可能会看到更灵活的核心设计,可以动态适应不同的计算需求,融合 Tensor 和 CUDA 核心的优势。 - Tensor Core 如何促进计算机图形学的发展?
Tensor Core 在 AI 增强型图形技术(如 DLSS(深度学习超级采样)和光线追踪中的 AI 加速降噪)中发挥着至关重大的作用。这些应用程序利用核心快速处理神经网络的能力,实现实时、高质量的渲染增强。
参考
[1] NVIDIA。适用于 TensorFlow 的 ResNet-50 v1.5 [互联网]。可从以下网址获取: https:
//catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_tensorflow
[2] Buck I、Foley T、Horn D、Sugerman J、Fatahalian K、Houston M、Hanrahan P。Brook for GPUs:图形硬件上的流计算。[互联网]。2004 年。可从以下网址获取:https
://graphics.stanford.edu/papers/brookgpu/brookgpu.pdf
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











