【AI学习-comfyUI学习-图生图反推关键词工作流-各个部分学习-第五节】
1,前言2,说明1,流程说明2,想要什么
3,流程(1)调用模块1)整个模块部分2)整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片
4,模块介绍🎯 一、K采样器(KSampler)是什么?🧠 二、采样器的选择影响风格⚙️ 三、CFG(提示词引导强度)的作用🧩 四、步数(Steps)🖋 五、参数组合推荐(针对漫画风)🧩 六、与提示词/模型的关系
5,细节部分(1)clip input is invalid: None🧩 一、问题原因(通俗解释)⚙️ 二、解决方法(两种方案)✅ 方案一:为 Flux 模型添加独立 CLIP 模型节点步骤:
✅ 方案二:换成自带CLIP的Checkpoint模型
(2)单独的图反推文字模块(1)单独的图反推文字模块部分(2)推出来的描述词(3)使用AI生成图片(4)WD14 反推提示词 (WD14 Tagger)
6,使用的工作流7,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1,流程说明
整个工作流分为 三大部分:输入 → 关键词反推 → 重生成输出。
加载原图 → VAE编码 → WD14反推关键词
↓
手动或自动编辑 prompt
↓
CLIP编码 → K采样生成
↓
VAE解码 → 保存图像
2,想要什么
在测试过程中有很多次其实,生成都是不是想要的图,所以多多测试。
3,流程
(1)调用模块
1)整个模块部分
这回整个模块都可以截截图下了

2)整个模块部分

(2)输出 提示词
如下是输入提示词
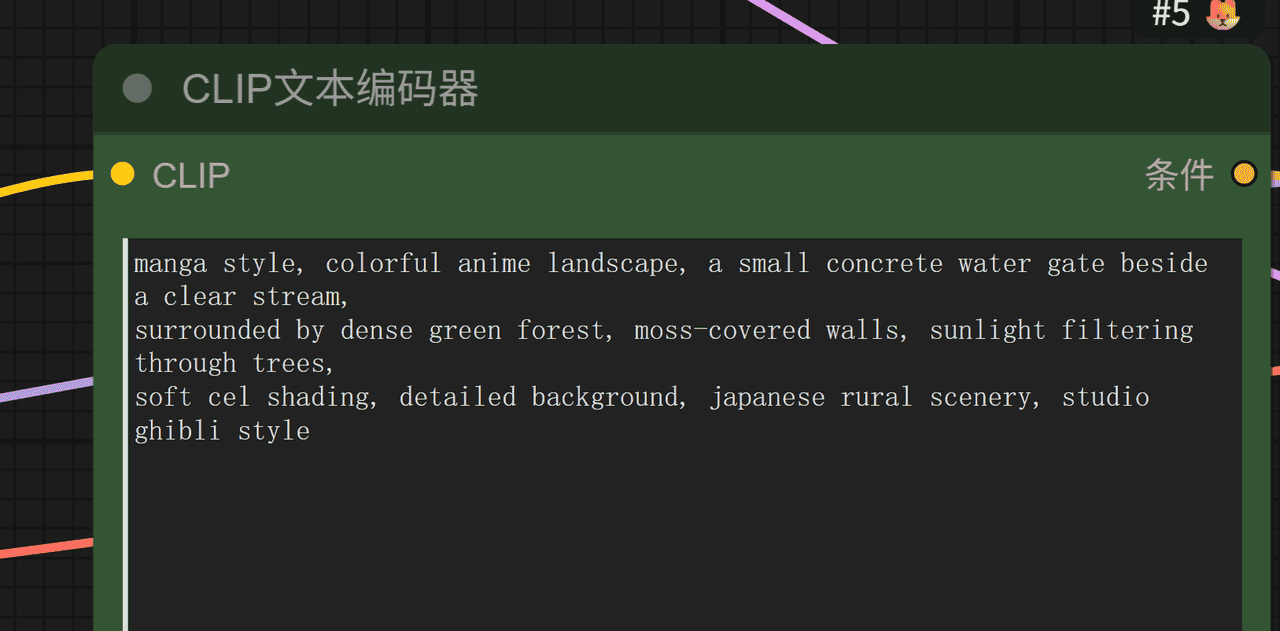
manga style, colorful anime landscape, a small concrete water gate beside a clear stream,
surrounded by dense green forest, moss-covered walls, sunlight filtering through trees,
soft cel shading, detailed background, japanese rural scenery, studio ghibli style
(3)模型加载


(4)生成图片

4,模块介绍
🎯 一、K采样器(KSampler)是什么?
KSampler 是 生成图像的核心节点,可以理解成「图像生成的引擎」,负责:
根据模型(UNet)、VAE、提示词(CLIP编码)共同计算“图像的逐步生成过程”;通过不同算法(采样器)控制风格、细节、对比度、平滑度;CFG(Classifier-Free Guidance)系数控制“提示词的影响力”。
你现在的采样器参数如下:
采样方法:euler
步骤(Steps):20
CFG:8.0
调度器:normal
随机种子:839999589484827
这套参数偏向“写实或柔和”风格,不够强调漫画的线条与对比。
🧠 二、采样器的选择影响风格
| 采样方法 | 特性 | 适合的风格 |
|---|---|---|
| Euler | 快速、细节中等、对比较低 | 写实风(你当前使用) |
| Euler a | 更随机、更柔和 | 艺术插画 |
| DPM++ 2M Karras | 细节丰富、线条清晰、最适合动漫/漫画 | ✅ 推荐 |
| DPM++ SDE Karras | 过渡平滑,色彩层次更丰富 | ✅ 推荐 |
| DDIM | 风格一致、重现性高 | 插画类稳定复现 |
| Heun | 类似Euler但更“光滑” | 插画或动画风 |
➡ 建议你改为:
DPM++ 2M Karras
DPM++ SDE Karras
⚙️ 三、CFG(提示词引导强度)的作用
| CFG数值 | 效果 | 推荐 |
|---|---|---|
| 5~7 | 提示词影响较弱,偏原图或写实 | 不适合漫画 |
| 8~10 | 平衡风格化与细节保留 | ✅ 最推荐 |
| 11~13 | 提示词主导性强,风格更“夸张” | ✅ 可试用于强线稿风 |
| >14 | 容易过曝或变形 | ❌ 不建议 |
➡ 你现在CFG=8.0,建议尝试:
若想柔和吉卜力风:保持 8.0~9.0若想黑白线稿风:提高到 11~12
🧩 四、步数(Steps)
| 步数 | 效果 | 推荐值 |
|---|---|---|
| 10~20 | 快速生成,但细节少 | 预览阶段 |
| 25~40 | 线条更干净、风格更明显 | ✅ 正式生成 |
| >50 | 渲染时间长,收益递减 | 不建议 |
➡ 你现在 Steps=20,可以试着改为 30~35。
🖋 五、参数组合推荐(针对漫画风)
| 场景 | 采样器 | Steps | CFG | 调度器 | 效果 |
|---|---|---|---|---|---|
| 彩色漫画(吉卜力风) | DPM++ SDE Karras | 30 | 8.5 | normal | 柔和自然、颜色通透 |
| 黑白漫画(线稿风) | DPM++ 2M Karras | 35 | 11 | normal | 强对比、线条明显 |
| 半写实卡通风 | DPM++ 2M Karras | 28 | 9 | karras | 介于动画与现实之间 |
🧩 六、与提示词/模型的关系
KSampler 是“生成引擎”,但它依赖的三大输入会共同影响结果:
CLIP 文本编码器 → 提示词控制内容和风格
(你现在 prompt 已经不错,建议保持)
Checkpoint 模型 → 控制总体画风(ToonYou 是卡通模型)
若你想更“手绘”一点,可换为
DreamShaper_8
Ghibli-Flux
VAE 解码器 → 控制色调和亮度
ToonYou 内置VAE即可,无需改。
5,细节部分
(1)clip input is invalid: None
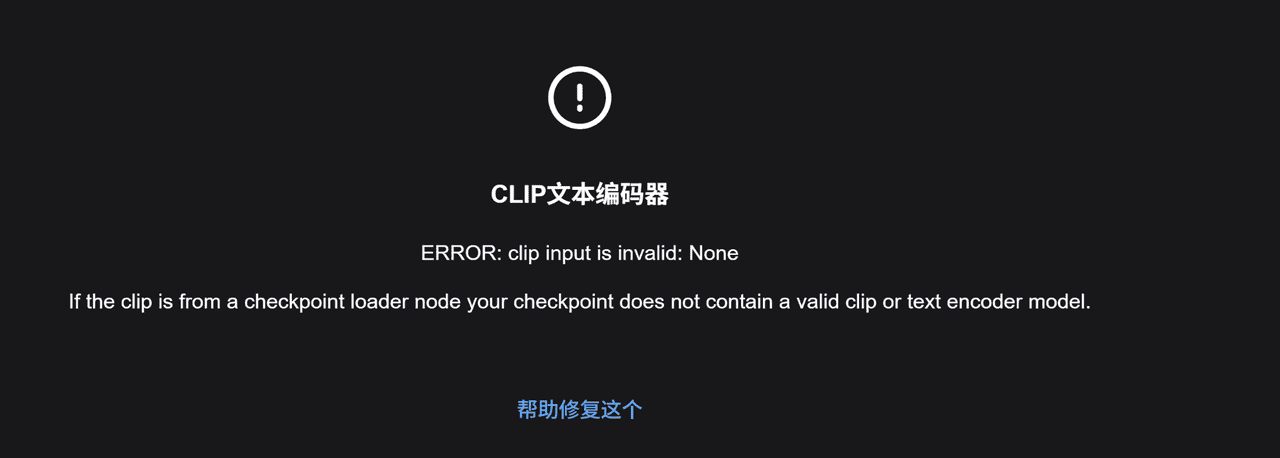
CLIP文本编码器 报错:clip input is invalid: None
“如果 clip 来自 Checkpoint 加载节点,那么该 checkpoint 不包含有效的 clip 或文本编码器模型。”
非常好,这个截图说明了你现在遇到的错误本质问题:
报错:clip input is invalid: None
CLIP文本编码器
“如果 clip 来自 Checkpoint 加载节点,那么该 checkpoint 不包含有效的 clip 或文本编码器模型。”
🧩 一、问题原因(通俗解释)
在 ComfyUI 的 Stable Diffusion/Flux 工作流中:
模型(Checkpoint)通常包含 3 个部分:
UNet:负责生成图像VAE:负责图像的压缩与解压CLIP(Text Encoder):负责把文字提示词编码成模型能理解的特征
而错误提示说明:
👉 加载的这个模型
SDVN11-Ghibli-Flux_fp8-hyper.safetensors
没有包含 CLIP 文本编码器部分(可能是纯 UNet 权重或是 Flux 微调模型,不含文本部分)。
所以,当
CLIP文本编码器
Checkpoint加载器
clip
⚙️ 二、解决方法(两种方案)
✅ 方案一:为 Flux 模型添加独立 CLIP 模型节点
(推荐,尤其是使用 Flux、SDXL 或纯 UNet LoRA 时)
步骤:
在节点搜索中添加:
CLIP Loader (CLIP 加载器)
选择一个与你模型匹配的 CLIP 文件:
对于 SD 1.5 模型:
→
clip-vit-large-patch14
sd-clip-vit-large-patch14
→
clip_g.safetensors
ViT-bigG-14
将它的输出 连接到你的 CLIP文本编码器 的输入端口上。
📘 示例连接结构:
[Checkpoint加载器] → UNet / VAE
[CLIP加载器] → CLIP文本编码器 → KSampler
✅ 方案二:换成自带CLIP的Checkpoint模型
如果只是想测试漫画风格,可以用自带完整CLIP的模型,比如:
anything-v5-pruned.ckpt
dreamshaper_8.safetensors
comic-diffusion-v2.safetensors
toonyou_beta6.safetensors
这些模型加载后,会自动输出
model
clip
vae
然后把它们接到:
model → KSampler
clip → CLIP文本编码器
vae → VAE解码器
(2)单独的图反推文字模块
(1)单独的图反推文字模块部分
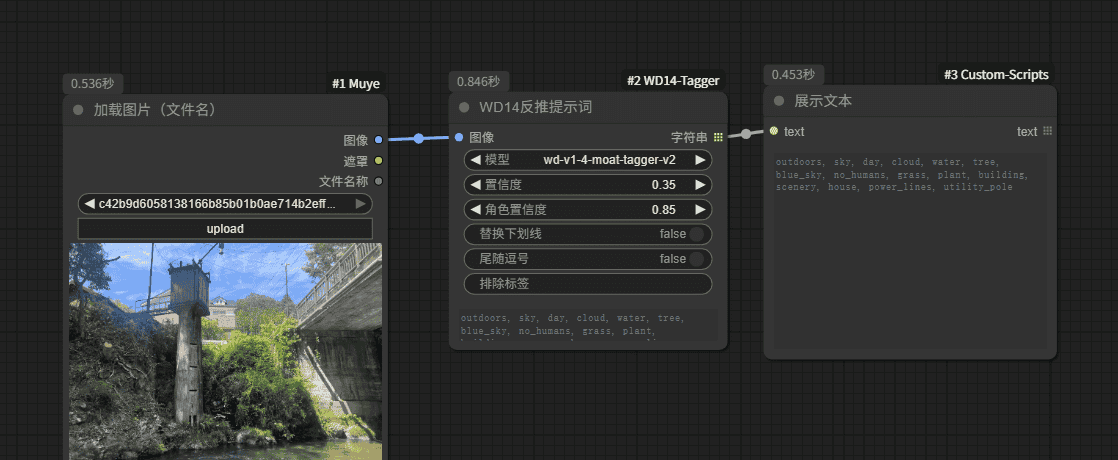
(2)推出来的描述词
outdoors, sky, day, cloud, water, tree, blue_sky, no_humans, grass, plant, building, scenery, house, power_lines, utility_pole
(3)使用AI生成图片
如图,其实生出来的,暂时就和原图没有关系了。

(4)WD14 反推提示词 (WD14 Tagger)
模块名称: WD14 反推提示词 (WD14 Tagger)
核心功能:
自动分析输入图片内容;
输出一串描述性关键词(比如 sky, tree, house, river 等);
这些关键词可以直接用作提示词(prompt)或反向提示词(negative prompt);
常用于“图生文” 或 “图反推再生成” 场景。
简单理解就是:
你把图丢进去 → 模块会自动识别图中有什么 → 输出关键词列表。
| 参数名 | 含义 | 建议值 / 说明 |
|---|---|---|
| 模型 (model) | 选择用于识别的模型 | 通常使用 |
| 置信度 (置信度) | 控制保留标签的最低置信度阈值(越高越严格) | 默认 0.35 较平衡。改高会输出更少、更准的标签;改低则更多但可能含噪音 |
| 角色置信度 (角色置信度) | 专门针对角色类(人物、动漫角色)标签的阈值 | 通常 0.85(不识别人类时影响不大) |
| 替换下划线 (replace underscore) | 是否将 |
例如 |
| 尾随逗号 (append comma) | 是否在每个标签后加上逗号 | 对接其他 prompt 模块时方便,可设 |
| 排除标签 (exclude tags) | 你想过滤掉的词 | 例如填 |
6,使用的工作流
第5节-图生图反推关键词工作流:https://download.csdn.net/download/qq_22146161/92266005
第五节-1图片反推文字工作流:https://download.csdn.net/download/qq_22146161/92266040
7,总结
这也算各一个开始吧,我也在学习摸索中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










