

一、 环境选择
在 Windows 10 上安装 Docker 时,选择 Hyper-V 还是 WSL 2 作为虚拟化后端
核心区别与适用场景
| 维度 | Hyper-V | WSL 2 |
|---|---|---|
| 技术架构 | 完整虚拟机平台,独立运行 Windows/Linux 虚拟机 | 基于 Hyper-V 的轻量级 Linux 子系统,深度集成 Windows 文件系统 |
| 性能表现 | 资源占用较高(默认分配 2GB 内存),启动速度较慢 | 内存按需分配,文件系统性能提升 4-6 倍,启动速度更快 |
| 兼容性 | 仅支持 Windows 10 专业版/企业版/教育版(家庭版需手动破解) | 支持 Windows 10 家庭版(2004+)和专业版,无需额外配置 |
| 适用场景 | 需同时运行多个虚拟机(如 Kubernetes 集群)或 Windows/Linux 混合环境 | 专注 Linux 开发、Docker 专用场景,适合轻量级容器化任务 |
二、WSL 2 环境准备
1. 系统要求
• 必须运行 Windows 10 版本 2004 及更高版本(内部版本 19041 及更高版本)或 Windows 11 才能使用以下命令
wsl --install
#此命令将启用运行 WSL 并安装 Linux 的 Ubuntu 发行版所需的功能,这里用Redhat系统,所以不这么安装
2. 启用虚拟化平台和 Linux 子系统
# 管理员权限的 PowerShell 执行,每执行一个会重启系统
Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
3. 下载 Linux 内核更新包
WSL2 Linux 内核更新包适用于 x64 计算机
如果使用 ARM64 计算机,请改为下载 ARM64 包。 如果不确定拥有哪种计算机,请打开命令提示符或 PowerShell 并输入:
systeminfo | find "System Type"。
4. 将 WSL 2 设置为默认版本
wsl --set-default-version 2 #打开 PowerShell 并运行以下命令
5. 安装所选 Linux 分发版,命令行安装
wsl --list --online #查看可用发行版列表
wsl --install -d OracleLinux_7_9 #列如安装redhat7.9版,或者在microsoft官网下载
Microsoft官方文档,不清楚的必须看这文档

6. 安装所选 Linux 分发版,下载文件安装(本次是按照这个)
microsoft官网下载

下载分发版后,导航到包含下载的文件夹,并在该目录中运行以下命令,其中 app-name 是 Linux 分发.appx文件的名称。
Add-AppxPackage .OracleLinux7.9_7.9.1.0.Appx
6. WSL 的基本命令
WSL 的基本命令链接
wsl #shell界面
wsl --shutdown #关闭
wsl --version #查看版本
wsl --list --verbose #列出已安装的 Linux 发行版
wsl --list --online #列出可用的 Linux 发行版
wsl --help #查看协助
7. wsl –list –online没有你需要的linux版本时,可镜像tar导入导出
导入要与 WSL 一起使用的任何 Linux 发行版 | Microsoft Learn
安装完后你需要将用户名添加到 sudoers 文件,以便允许用户使用 sudo。 命令 adduser -G wheel $myUsername 会将用户 myUsername 添加到 wheel 组中。 wheel 组中的用户会被自动授予 sudo 权限,并且可以执行需要提升权限的任务。
三、Docker Desktop安装
1. 安装 Docker Engine
Docker Desktop安装官网
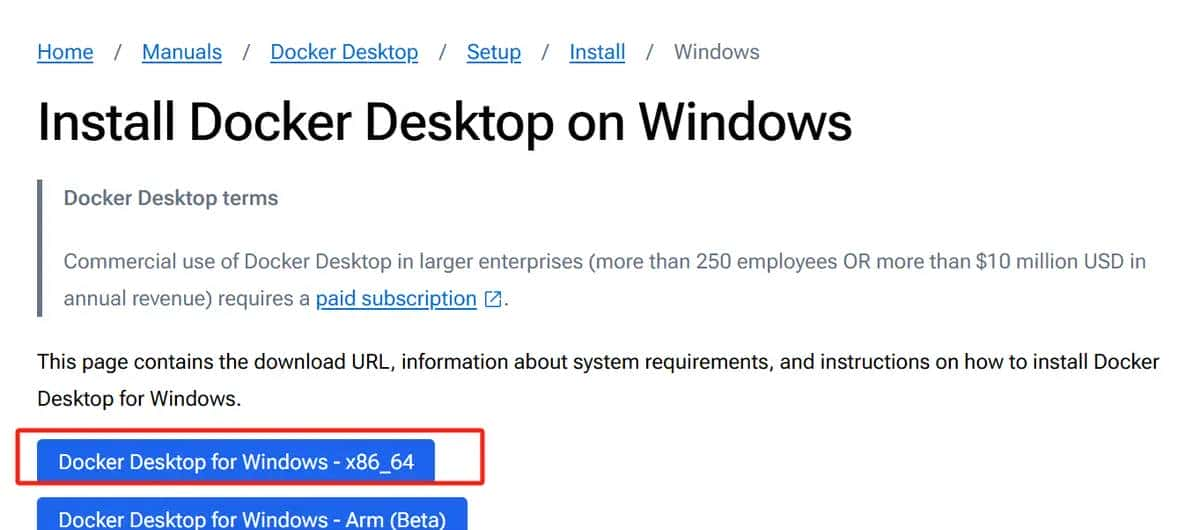
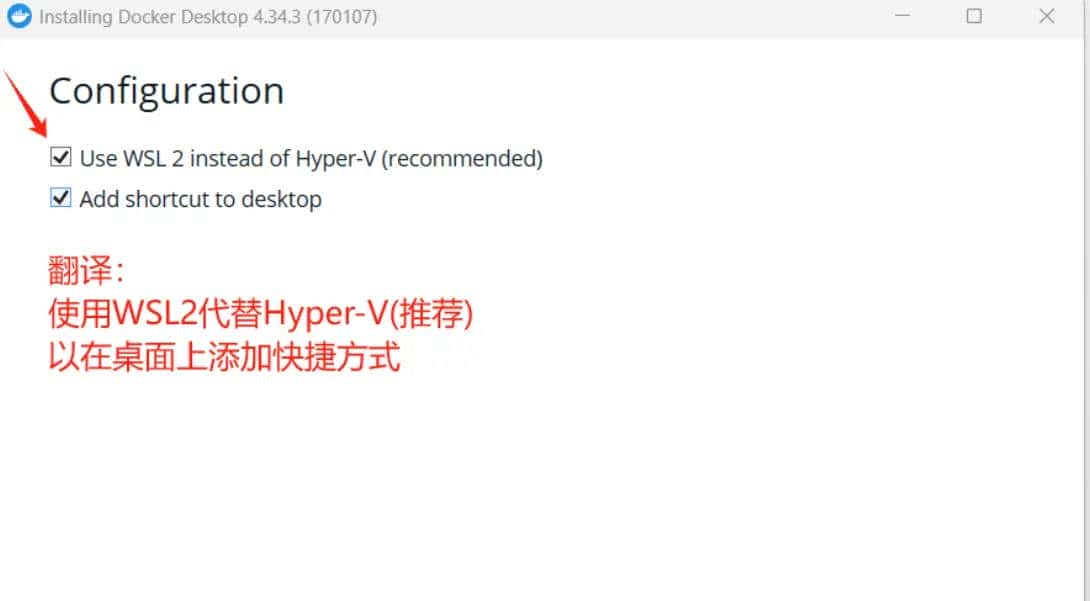
2. 在安装过程中,将 WSL 2,勾选此选项以获得更好的性能
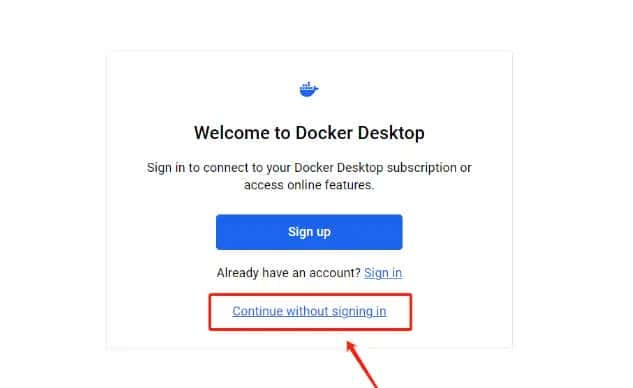
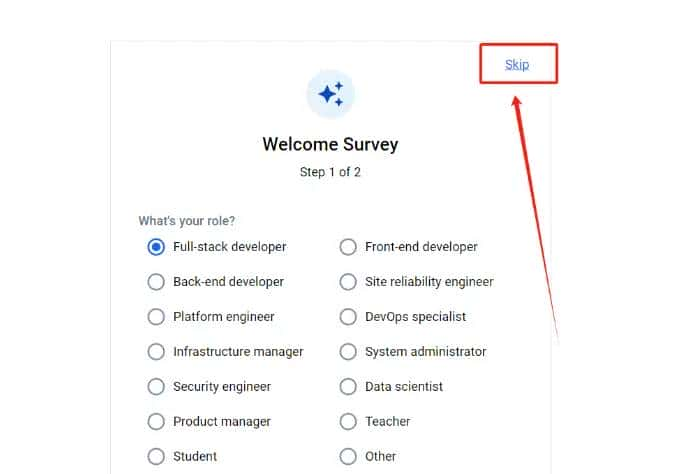
3. 可选择跳过登录步骤
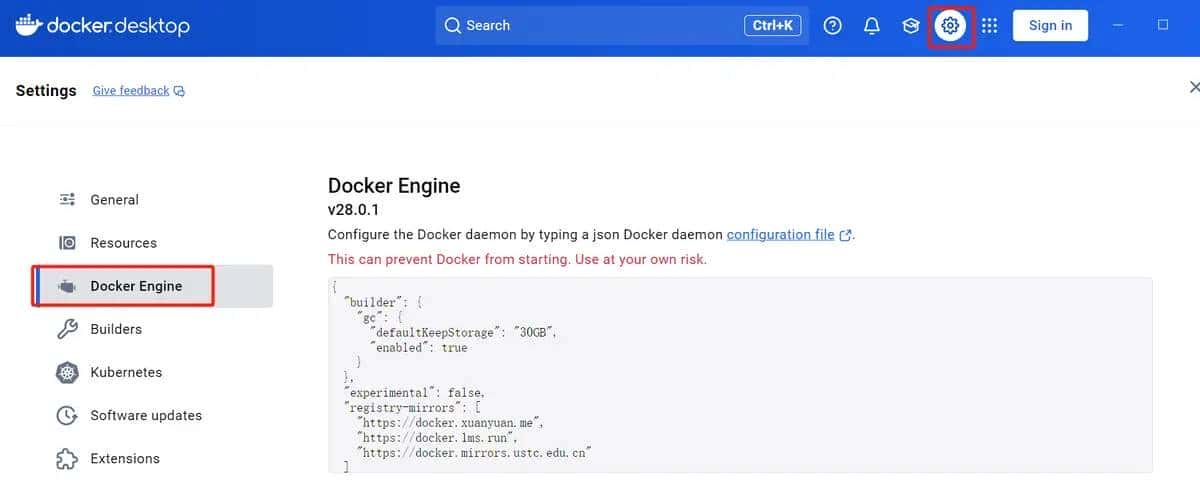
4. 配置镜像加速
# 目前可用的地址
{
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.1ms.run",
"https://docker.mirrors.ustc.edu.cn"
]
}
3. 验证
docker run hello-world # 验证安装,能下载不报错即可
#下载不成功报这个错误需要更换镜像,直到找到可用的
Using default tag: latest
Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
三、驱动与CUDA 安装
1. NVIDIA 驱动准备
-
在 Windows 中安装最新 NVIDIA 驱动
下载 NVIDIA 官方驱动 | NVIDIA -
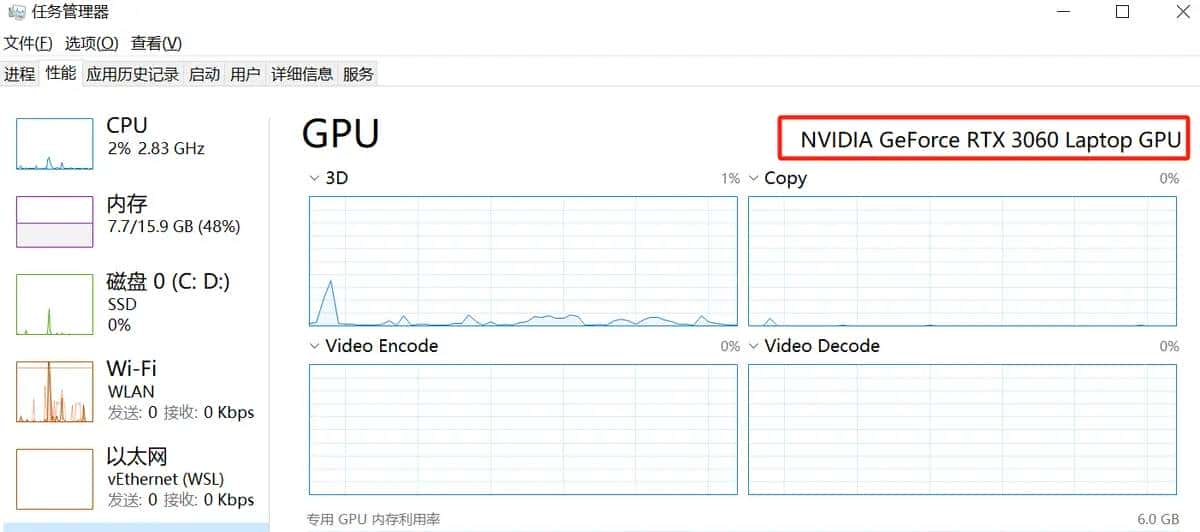
打开
任务管理器--性能--GPU查看GPU型号
- 电脑管家或者电脑品牌官网(新手推荐)
-
下载NVIDIA自动更新驱动程序(新手推荐)
NVIDIA GeForce 驱动程序 – N 卡驱动 | NVIDIA
-
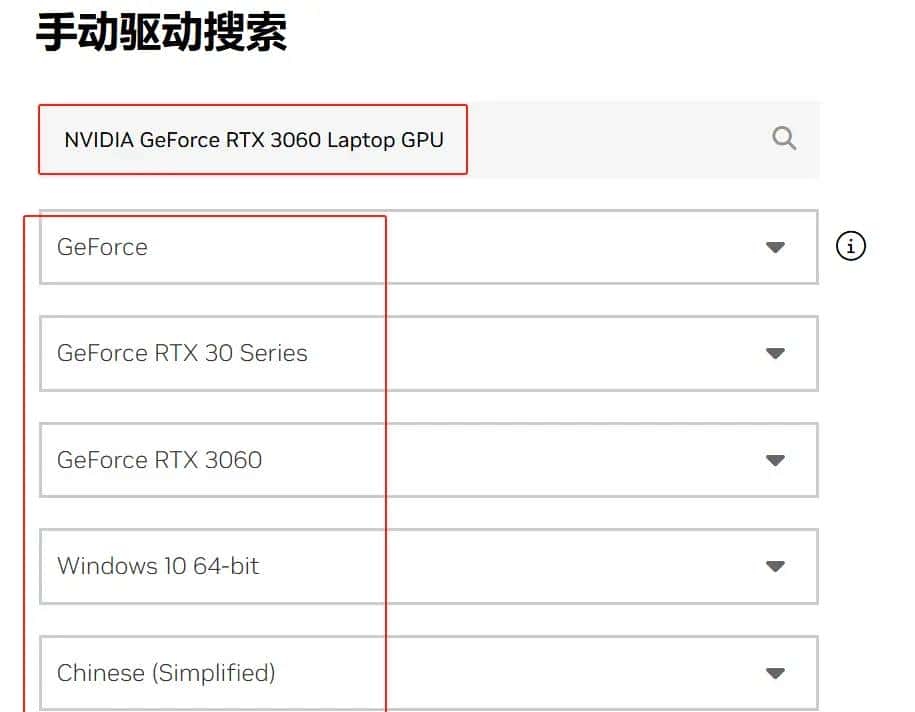
手动选择型号和版本
-
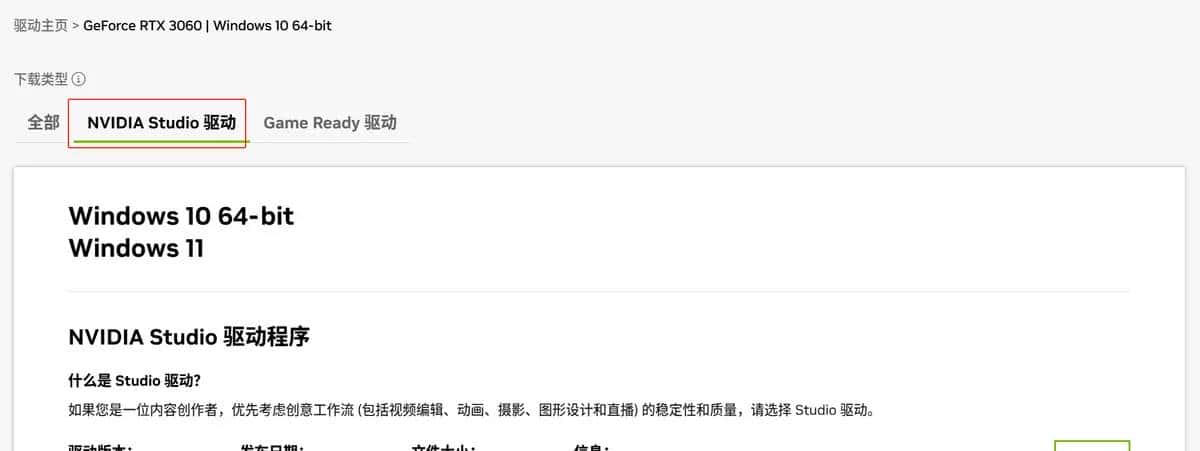
选择studio的版本
-
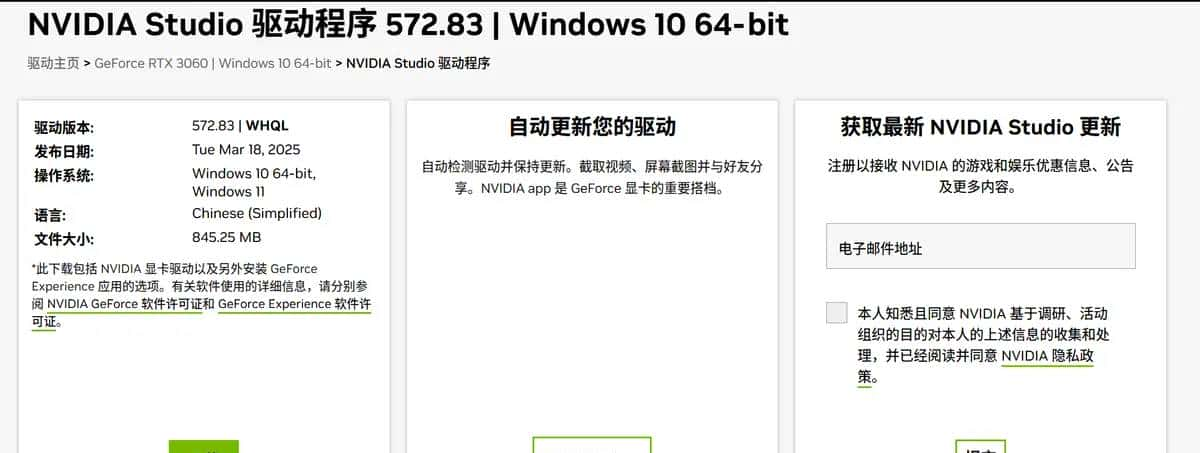
选择下载即可
- 验证驱动是否成功:
C:Users>nvidia-smi # 在 Windows CMD 查看驱动版本和CUDA最高版本
输出:
NVIDIA-SMI 536.25 Driver Version: 536.25 CUDA Version: 12.2
2. CUDA安装
-
选择版本信息,选择exe(local)下载即可
-
验证是否成功:
C:Users>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Jun_13_19:42:34_Pacific_Daylight_Time_2023
Cuda compilation tools, release 12.2, V12.2.91
Build cuda_12.2.r12.2/compiler.32965470_0
3. nvidia-container-toolkit容器,window版不需要
NVIDIA Container Toolkit 是一款用于在容器化环境中高效运行 GPU 加速应用 的工具,一般与 Docker 配合使用,能够让开发者将基于 NVIDIA GPU 的应用程序打包到容器中并在支持 NVIDIA GPU 的服务器上运行。NVIDIA Container Toolkit 使得我们可以 在容器内使用 GPU,实现高效的并行计算,特别适用于 深度学习、高性能计算(HPC) 和 图形渲染 等任务。NVIDIA Container Toolkit本质上是一个为 NVIDIA GPU 提供容器化支持的工具包,它能让 Docker 容器直接访问 GPU 资源,而无需繁琐的配置。
• 验证
docker info |grep Runtimes
输出:
Runtimes: io.containerd.runc.v2 nvidia runc
四、 容器安装 vLLM
1. 拉取镜像(镜像已安装CUDA12.1和ubuntu22.04)
# 容器镜像比较大,稍微等待一会
docker pull vllm/vllm-openai:v0.7.3
#查看镜像
docker images
输出:
REPOSITORY TAG IMAGE ID CREATED SIZE
vllm/vllm-openai v0.7.3 a0b3e59739e9 5 weeks ago 16.4GB
2. 查看镜像协助信息
# 验证镜像是否能正常启动
docker run --rm -it vllm/vllm-openai:v0.7.3 --help

3. 部署大型语言模型(LLM)所需的GPU显存计算
M=(P*4B) *(Q/32) *1.2
M:GPU内存(G)
P:模型参数数量(十亿)
Q:量化位数(32,16,8,4)
1.2:20%开销因子
举例:
Qwen2-1.5B-Instruct模型
参数说明:
• 模型参数(P):1.5B(即15亿参数)
• 量化位数(Q):假设为16位(FP16/BF16),这是推理部署常用精度
• 开销因子:1.2(覆盖激活值、中间结果等额外开销)
计算:
M=(1.5×4)× (16/32) ×1.2 = 6×0.5×1.2 = 3.6GB
其他量化方案对比
| 量化位数(Q) | 显存需求(GB) | 适用场景 |
|---|---|---|
| 32位(FP32) | 7.2 | 无损推理,显存需求高 |
| 16位(FP16) | 3.6 | 平衡精度与效率(推荐) |
| 8位(INT8) | 1.8 | 轻量级部署,精度可能下降 |
| 4位(INT4) | 0.9 | 边缘设备(需模型支持) |
4. 下载模型文件
✅ 手动下载模型:
git lfs install #lfs大文件传输
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
✅ 代码下载模型:
pip install modelscope #安装依赖
用modelscope库下载
#模型下载
from modelscope import snapshot_download
#linux系统
#local_dir = "/LLaMA-Factory/Qwen2-1.5B-Instruct"
#windows系统目录
local_dir = "D:/AiModel/Qwen2-1.5B-Instruct"
model_dir = snapshot_download( qwen/Qwen2-1.5B-Instruct ,local_dir=local_dir)
✅ 启动镜像
sudo docker run --runtime nvidia --gpus all
-v /llm_deploy/:/home/
-p 8000:8000
-e HF_HUB_OFFLINE=1
-e HF_HUB_DISABLE_SSL=1
--ipc=host
--name Qwen2_1.5B
vllm/vllm-openai:v0.7.3
--model /home/Qwen2-1.5B-Instruct
--dtype bfloat16
--gpu-memory-utilization 0.85
--max-model-len 16384
✅ VLLM在多张GPU上运行
在运行 vLLM 时,使用 –tensor-parallel-size 参数指定 GPU 数量。例如,如果你有 2 张 RTX 4090,可以这样运行:只需在上面的命令中加入:
"--tensor-parallel-size", "2"
✅KV 缓存优化
在 Transformer 结构中,每次生成新 token 时,模型需要重新计算所有之前的 token(自回归推理)。这会导致长文本推理速度越来越慢。KV 缓存(Key-Value Cache) 是一种优化策略,它将计算过的 Key(键)和 Value(值)存储起来,避免重复计算,从而加速推理。
开启 KV 缓存优化
vLLM 默认开启 KV 缓存,但如果要手动调整 KV 缓存的大小,可以使用 --max-num-batched-tokens 参数。如果你的模型处理长文本较多,提议调大 --max-num-batched-tokens,但要注意 GPU 显存的使用情况。
✅VLLM 常用参数简介
vLLM 核心参数分类详解表:
| 参数分类 | 参数名称 | 参数类型 | 默认值 | 作用说明 | 推荐值/选项 | 注意事项 |
|---|---|---|---|---|---|---|
| 核心设置 | --model |
字符串 | 无 | 指定模型名称或本地路径 | "meta-llama/Llama-3-70b" |
需验证模型与vLLM兼容性(如是否支持PagedAttention) |
--tensor-parallel-size |
整数 | 1 | 多GPU张量并行数量 | 70B模型:4-8,7B模型:1-2 | 需通过nvidia-smi topo -m确认GPU间带宽 |
|
--tokenizer |
字符串 | 自动加载 | 指定自定义分词器路径 | 与模型匹配的分词器路径 | 需确保分词器与模型兼容(如特殊token定义一致) | |
| 显存管理 | --gpu-memory-utilization |
浮点数 | 0.9 | 控制单GPU显存利用率上限 | 0.85-0.95 | 出现OOM时优先降低此值(步长0.05) |
--dtype |
字符串 | auto | 指定模型计算精度 | A100/H100用bfloat16,消费卡用float16
|
float16在部分模型可能溢出 |
|
| 推理优化 | --max-num-batched-tokens |
整数 | 自动计算 | 单次批处理最大token数 | 1024-32768(根据GPU利用率动态调整) | 值过高可能导致延迟增加 |
--enable-kv-cache |
布尔值 | True | 启用KV缓存优化 | 保持默认 | 若遇到推理错误可尝试禁用 | |
--enforce-eager |
布尔值 | False | 强制禁用CUDA Graph优化(启用即时执行模式) | 仅调试使用 | 显著降低性能(约30%),生产环境勿启用 | |
| API服务器 | --port |
整数 | 8000 | API服务监听端口 | 8000/8080 | 生产环境提议配合Nginx反向代理 |
--host |
字符串 | 0.0.0.0 | 监听地址 | 内网部署用具体IP(如192.168.1.100) | 避免直接暴露公网IP | |
--api-key |
字符串 | 无 | 设置API访问认证密钥 | 强密码字符串(如UUID) | 需配合HTTPS使用,定期轮换密钥 | |
| 输出控制 | --max-tokens |
整数 | 16 | 生成文本最大长度 | 对话512,代码生成2048 | 过长会显著增加显存占用 |
--temperature |
浮点数 | 1.0 | 控制输出随机性 | 实际问答0.1,创意生成0.7-1.0 | 设为0时启用贪婪采样 | |
| 高级调试 | --block-size |
整数 | 32 | 设置注意力计算的块大小 | 16(低显存)或64(高性能) | 影响显存碎片化程度 |
--swap-space |
整数 | 4 | 设置CPU-GPU交换空间大小(GB) | 长文本场景提议≥16GB | 需确保系统内存充足 |
如果你在使用 VLLM 过程中遇到 显存溢出(OOM) 或 推理速度慢 的问题,可以尝试调整:
降低 --max-num-batched-tokens
调整 --gpu-memory-utilization(一般设为 0.85~0.95)
使用 --dtype float16 减少显存占用
在多 GPU 服务器上增加 --tensor-parallel-size
五、遇到的问题解决
1. GPU 未识别
检查 Windows 驱动与 WSL CUDA 版本匹配性
在 WSL 中运行nvidia-smi确认 GPU 可见性
2.unknown flag: –model
问题出在 Docker 命令行参数的位置错误。vLLM 的启动参数(如 –model)必须放在 Docker 镜像名称之后,而 Docker 自身的参数(如 –runtime、-v 等)需放在镜像名称之前。
3.镜像源地址不行,网上找一个或者我上面的那些
Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
4. huggingface国内访问不了,镜像里写死了
Error retrieving file list: (MaxRetryError(“HTTPSConnectionPool(host= huggingface.co , port=443): Max retries exceeded with url
启动参数加上这两个环境变量
-e HF_HUB_OFFLINE=1 #离线
-e HF_HUB_DISABLE_SSL=1 #关掉ssl
5. 路径挂载问题
Repo id must be in the form repo_name or namespace/repo_name : /home/llm_deploy/Qwen2-1.5B-Instruct . Use
repo_typeargument if needed
这个是说Repo id must be in the form repo_name or namespace/repo_name ,还是挂载的路径有问题,没有识别到模型文件
raise ValueError(f”No supported config format found in {model}.”)
ValueError: No supported config format found in llm_deploy/Qwen2-1.5B-Instruct
-v /llm_deploy/:/home/ 挂载有问题,模型文件识别的有问题
6. 启动参数优化
ValueError: The model s max seq len (32768) is larger than the maximum number of tokens that can be stored in KV cache (17088). Try increasing
gpu_memory_utilizationor decreasingmax_model_lenwhen initializing the engine.
#我这边调试加了这3个可以的
--dtype bfloat16
--gpu-memory-utilization 0.85
--max-model-len 16384
7. Runtime报错
RuntimeError: Engine process failed to start. See stack trace for the root cause.
使用root启动,在wsl中用sudo docker run xxx命令
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










