

背景
机器:4节点,每节点2张A40
操作系统:RockyLinux9.5
Ollama只能在单机运行deepseek,无法利用多机进行分布式推理。
尝试基于ray + VLLM进行deepseek部署,以利用多台机器。
docker镜像制作
以下操作在其中一台机器即可
# 拉取基础镜像
docker pull vllm/vllm-openai:v0.7.2
# 创建Dockerfile
mkdir -p /data/build/vllm/
cat > /data/build/vllm/Dockerfile <<"EOF"
FROM vllm/vllm-openai:v0.7.2
ENV TZ=Asia/Shanghai
DEBIAN_FRONTEND=noninteractive
VLLM_ENGINE_ITERATION_TIMEOUT_S=180
GLOO_SOCKET_IFNAME=ens18
TP_SOCKET_IFNAME=ens18
NCCL_SOCKET_IFNAME=ens18
NCCL_DEBUG=info
NCCL_NET=Socket
NCCL_IB_DISABLE=0
NODE_TYPE=worker
HEAD_NODE_ADDRESS=127.0.0.1
WORKDIR /server
COPY . .
RUN apt-get update
&& apt -y install dos2unix tzdata vim tree curl wget
&& ln -sf /usr/share/zoneinfo/${TZ} /etc/localtime
&& echo ${TZ} > /etc/timezone
&& dpkg-reconfigure --frontend noninteractive tzdata
RUN find ./ -type f -print0 | xargs -0 dos2unix && chmod +x entrypoint.sh
ENTRYPOINT ["sh","-c","./entrypoint.sh $NODE_TYPE $HEAD_NODE_ADDRESS"]
EOF
# 创建启动脚本
cat > /data/build/vllm/entrypoint.sh <<"EOF"
#!/bin/bash
NODE_TYPE="$1" # Should be head or work
HEAD_NODE_ADDRESS="$2"
echo "Starting Ray with ${NODE_TYPE}"
echo "Head node address: ${HEAD_NODE_ADDRESS}"
# Command setup for head or work node
if [ "${NODE_TYPE}" == "head" ]; then
echo "Starting head node..."
ray start --block --head --port=6379 --dashboard-host=0.0.0.0
else
echo "Starting work node..."
ray start --block --address="${HEAD_NODE_ADDRESS}":6379
fi
tail -f /dev/null
EOF
# 编译新镜像
cd /data/build/vllm/ && docker build -t ray_vllm:latest .
# 保存镜像,分发到其他机器
docker save -o ray_vllm.tar ray_vllm:latest
scp ray_vllm.tar root@xxxxxxxx:/root/
部署vllm header节点
选取10.3.6.41作为header节点
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
# 导入上一步制作的镜像
docker load < ray_vllm.tar
mkdir -p /data/vllm/data/huggingface
mkdir -p /data/vllm/data/models
# head节点
cat > /data/vllm/docker-compose.yml <<"EOF"
services:
ray_vllm:
image: ray_vllm:latest
container_name: ray_vllm
restart: always
network_mode: host
ipc: host
shm_size: 30G
environment:
# 网卡名
GLOO_SOCKET_IFNAME: ens18
TP_SOCKET_IFNAME: ens18
NCCL_SOCKET_IFNAME: ens18
NCCL_DEBUG: TRACE
NCCL_IB_DISABLE: 1
VLLM_MLA_DISABLE: 1
NODE_TYPE: head
HEAD_NODE_ADDRESS: 10.3.6.41
VLLM_USE_MODELSCOPE: false
HF_ENDPOINT: https://hf-mirror.com
volumes:
- /data/vllm/data/huggingface:/root/.cache/huggingface
- /data/vllm/data/models:/models
- /data/vllm/data/logs:/server/logs
deploy:
resources:
reservations:
devices:
- driver: nvidia
# count 与 device_ids 二选一
# count指定需要使用的GPU数量;值为int数组型或all;
# device_ids: ["0", "3"]
count: "all"
capabilities: ["gpu"]
EOF
# 启动header节点
cd /data/vllm && docker-compose up -d
ens18为网卡名称,请改成自己机器的网卡- 10.3.6.41 为本机ip
/data/vllm/data/models 为模型存储路径,提议提前下载好模型copy至此目录。列如我的路径
部署vllm work节点
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
# 导入上一步制作的镜像
docker load < ray_vllm.tar
mkdir -p /data/vllm/data/huggingface
mkdir -p /data/vllm/data/models
cat > /data/vllm/docker-compose.yml <<"EOF"
services:
ray_vllm:
image: ray_vllm:latest
container_name: ray_vllm
restart: always
network_mode: host
ipc: host
shm_size: 30G
environment:
# 网卡名
GLOO_SOCKET_IFNAME: ens18
TP_SOCKET_IFNAME: ens18
NCCL_SOCKET_IFNAME: ens18
NCCL_DEBUG: TRACE
NCCL_IB_DISABLE: 1
VLLM_MLA_DISABLE: 1
NODE_TYPE: work
HEAD_NODE_ADDRESS: 10.3.6.41
VLLM_USE_MODELSCOPE: false
HF_ENDPOINT: https://hf-mirror.com
volumes:
- /data/vllm/data/huggingface:/root/.cache/huggingface
- /data/vllm/data/models:/models
- /data/vllm/data/logs:/server/logs
deploy:
resources:
reservations:
devices:
- driver: nvidia
# count 与 device_ids 二选一
# count指定需要使用的GPU数量;值为int数组型或all;
# device_ids: ["0", "3"]
count: "all"
capabilities: ["gpu"]
EOF
cd /data/vllm && docker-compose up -d
查看集群状态
# 在任一节点执行
[root@bogon vllm]# docker exec -it ray_vllm bash
root@bogon:/server# ray status
======== Autoscaler status: 2025-03-06 09:30:42.062813 ========
Node status
---------------------------------------------------------------
Active:
1 node_0cfc3dac42eeacd03793a367ce071533275cd4cf55fba2965beac6f4
1 node_f06dd713b2ef82056be82ad1ee0614e8a352a56520928b3823583eb2
1 node_b03ff7fa423b71dbf6d52e10073adeae2e7ad100ead2fc5711c36f7f
1 node_9fb403a7e868eece3a82781c07645484dcf59561d8d5e0689714ed4d
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/112.0 CPU
6.0/8.0 GPU (6.0 used of 6.0 reserved in placement groups)
0B/237.13GiB memory
0B/102.91GiB object_store_memory
Demands:
(no resource demands)
下载模型
下载好要运行的模型,并分发至所有节点
下载方法可以参考:https://www.jianshu.com/p/e06cfe41b7a9
运行模型
1、运行LLM模型
# gguf模型 效果更好
nohup vllm serve /models/DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf
--served-model-name deepseek-r1-70B-4bit
--dtype half
--load_format bitsandbytes
--quantization bitsandbytes
--gpu-memory-utilization 0.90
--max-num-seqs 1024
--max_model_len 18240
--pipeline_parallel_size 3
--tensor-parallel-size 2
--enforce-eager
--port 8000
> logs/deepseek-r1-70B-4bit.log 2>&1 &
- 这里以70B 4bit量化的deepseek为例
pipeline_parallel_size 3代表使用3节点tensor-parallel-size 2代表每节点使用2张卡- 更多参数:https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html#cli-reference
- 如果报如下错误:ValueError: The model s max seq len (131072) is larger than the maximum number of tokens that can be stored in KV cache (6192). Try increasing
gpu_memory_utilizationor decreasingmax_model_lenwhen initializing the engine. 可以尝试增加gpu_memory_utilization或者 减少max_model_len
- 测试模型API接口
# deepseek测试
curl http://10.3.6.41:8000/v1/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer "
-d {
"model": "deepseek-r1-70B-4bit",
"messages": [
{
"role": "system",
"content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."
},
{
"role": "user",
"content": "Compose a poem that explains the concept of recursion in programming."
}
],
"stream": true
}
2、运行embedding模型
# modelscope download --model AI-ModelScope/m3e-large --local_dir /data/vllm/data/models/m3e-large
nohup vllm serve /models/m3e-large
--served-model-name m3e-large
--task embed
--uvicorn-log-level debug
--port 6000
> logs/m3e-large.log 2>&1 &
# modelscope download --model iic/nlp_gte_sentence-embedding_chinese-large --local_dir /data/vllm/data/models/nlp_gte_sentence-embedding_chinese-large
nohup vllm serve /models/nlp_gte_sentence-embedding_chinese-large
--served-model-name nlp_gte_sentence-embedding_chinese-large
--task embed
--uvicorn-log-level debug
--port 6001
> logs/nlp_gte_sentence-embedding_chinese-large.log 2>&1 &
- 测试embedding api接口
# 参考 https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html#example-request
# 测试 embedding模型
curl http://10.3.6.41:6000/v1/embeddings
-H "Authorization: Bearer xxx"
-H "Content-Type: application/json"
-d {
"model": "m3e-large",
"input": "The food was delicious and the waiter...",
"encoding_format": "float"
}
3、运行reranker模型
# modelscope download --model BAAI/bge-reranker-v2-m3 --local_dir /data/vllm/data/models/bge-reranker-v2-m3
nohup vllm serve /models/bge-reranker-v2-m3
--served-model-name bge-reranker-v2-m3
--task score
--uvicorn-log-level debug
--port 7000
> logs/bge-reranker-v2-m3.log 2>&1 &
- 测试reranker api接口
# 参考 https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html#example-request
curl -X POST
http://10.3.6.41:7000/v1/rerank
-H accept: application/json
-H Content-Type: application/json
-d {
"model": "bge-reranker-v2-m3",
"query": "What is the capital of France?",
"documents": [
"The capital of Brazil is Brasilia.",
"The capital of France is Paris.",
"Horses and cows are both animals"
]
}
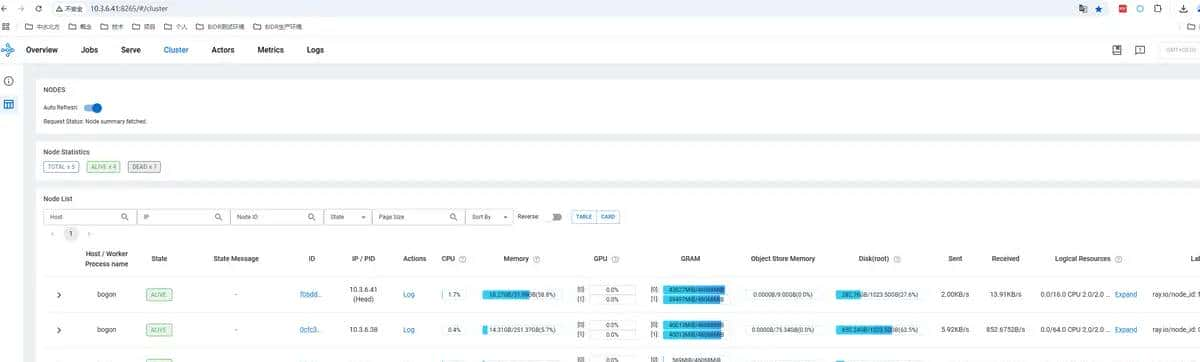
可视化集群状态 Ray Dashboard
可以通过以下地址访问
http://10.3.6.41:8265/#/overview
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





